前言 近日,腾讯优图实验室6篇论文被国际人工智能多媒体领域顶级会议ACM MM 2023(ACM International Conference on Multimedia)所接收, 涵盖视觉识别、神经绘画和风格化研究、半监督学习等多个研究方向,进一步展示了腾讯优图实验室在人工智能领域的技术能力和学术成果。
ACM MM是计算机图形学与多媒体领域的顶级国际会议,也是中国计算机学会推荐的该领域唯一的A类国际学术会议。本届ACM MM有效投稿量达3072篇,接收论文902篇,接收率约为29.3%。
本文转载自腾讯优图实验室
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
以下为腾讯优图实验室入选论文概览:
01 针对视觉识别的渐进图神经网络
PVG: Progressive Vision Graph for Vision Recognition
Jiafu Wu(Fudan University), Jian Li,Jiangning Zhang, Mingmin Chi(Fudan University),Yabiao Wang, Chengjie Wang
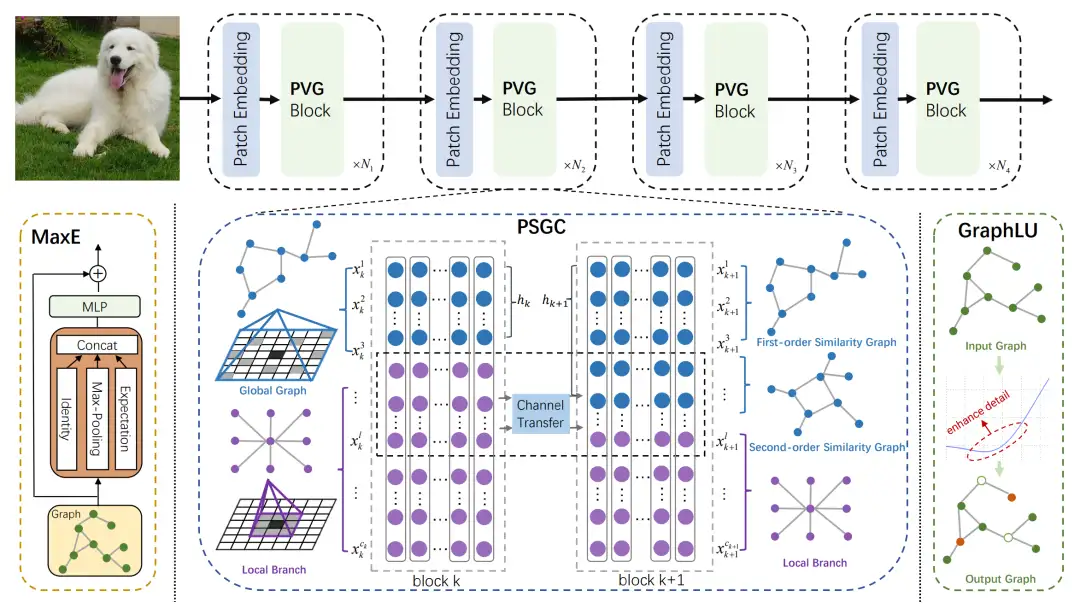
基于卷积和基于 Transformer 的视觉主干网络分别将图像处理为网格或序列结构,这对于捕获不规则物体来说不灵活。虽然Vision GNN(ViG)以图层级特征处理复杂图像,但其存在一些问题,包括邻节点选择的不准确性、节点信息聚合计算的昂贵性以及在深层中出现的过平滑问题。为了应对上述问题,本文提出了一种适用于视觉识别任务的渐进式视觉图(PVG)架构。
与过去的研究相比,PVG包含三个主要组件:其一,通过逐渐增加全局图分支的通道数并降低局部分支的通道数,引入二阶相似性的渐进分离图构建(PSGC)方法;其二,利用最大池化和数学期望(MaxE)实现邻节点信息的聚合和更新,以获取丰富的邻居信息;其三,采用图误差线性单元(GraphLU)方法,以一种松弛的形式增强低值信息,从而减轻对图像细节信息的压缩,以此缓解过平滑问题。通过在主流基准数据集上进行广泛实验,验证了PVG相对于现有最先进方法的卓越性能。
具体而言,PVG-S在ImageNet-1K数据集上取得了83.0%的Top-1准确率,较基于图神经网络的ViG-S方法提高了0.9个百分点,同时参数数量减少了18.5%。在最大规模的PVG-B模型上取得了84.2%的Top-1准确率,相较于ViG-B方法提升了0.5个百分点。此外,PVG-S在COCO数据集上的box AP和mask AP分别较ViG-S方法提高了1.3和0.4。
02 高质量自监督表示学习研究
Toward High Quality Facial Representation Learning
Yue Wang*(Shanghai Jiao Tong University),Jinlong Peng*, Jiangning Zhang, Ran Yi(Shanghai Jiao Tong University), Liang Liu, Yabiao Wang, Chengjie Wang
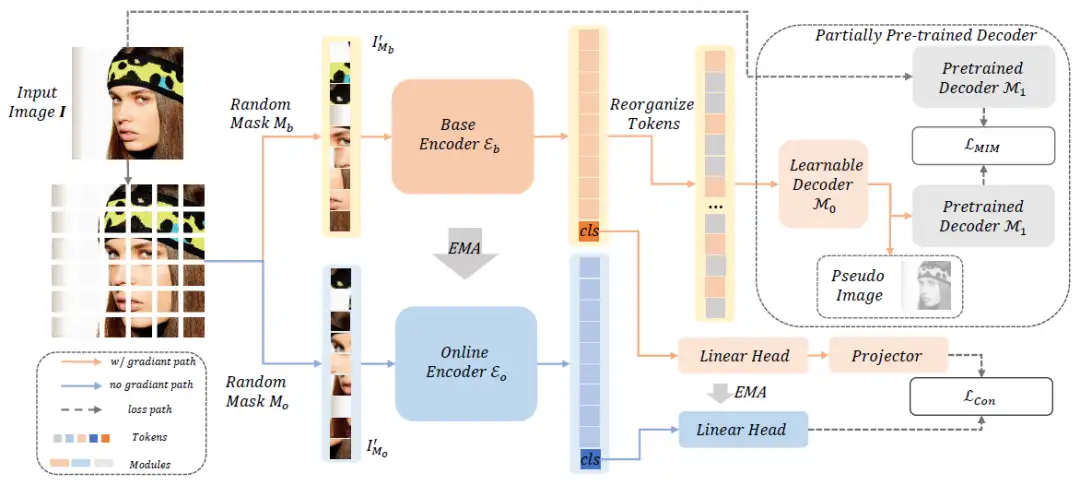
面部分析任务具有广泛的应用,但通用的面部表示仅在少数研究中进行了探索。在本文中,我们探索了高性能的预训练方法,以提升面部分析任务,如面部对齐和面部解析。我们提出了一种自监督预训练框架,称为Mask Contrastive Face(MCF),其中包括面部领域任务特别调整的遮罩图像建模和对比策略。
为了提高面部表示质量,我们使用预训练视觉骨干的特征图作为监督项,并使用部分预训练的解码器进行遮罩图像建模。为了在预训练阶段处理面部身份,我们进一步使用随机遮罩构建对比学习对。我们在LAION-FACE-cropped数据集上进行预训练,这是LAION-FACE 20M的变体。为了提高预训练效率,我们在LAION-FACE-cropped的一小部分上探索了我们的框架预训练性能,并验证了不同预训练设置的优越性。我们使用完整的预训练数据集进行预训练的模型在多个下游任务上优于最先进的方法。我们的模型在AFLW-19面部对齐任务中实现了0.932的NME ,而在LaPa面部解析任务中实现了93.96的F1得分。
03 基于动态预测区域的神经绘画和风格化研究
Stroke-based Neural Painting and Stylization with Dynamically Predicted Painting Region
Teng Hu(Shanghai Jiao Tong University), Ran Yi(Shanghai Jiao Tong University), Haokun Zhu(Shanghai Jiao Tong University), Liang Liu, Jinlong Peng, Yabiao Wang, Chengjie Wang, Lizhuang Ma(Shanghai Jiao Tong University)
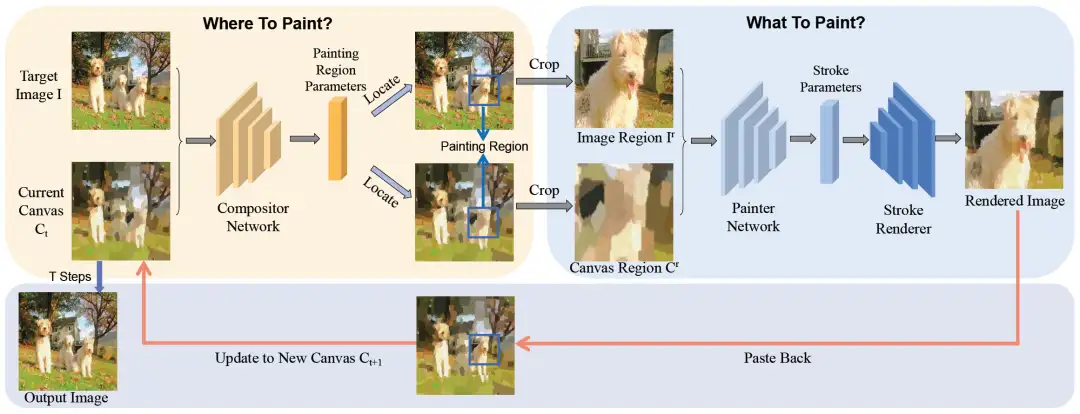
基于笔画的渲染旨在使用一组笔画重新创建图像。大多数现有方法使用均匀块划分策略来渲染复杂图像,这导致边界不一致的伪影。为了解决这个问题,我们提出了一种新颖的基于组合的神经绘画器(Compositional Neural Painter)框架,它根据当前画布动态预测下一个绘画区域,而不是将图像平面均匀划分为绘画区域。我们从一个空白画布开始,将绘画过程分为几个步骤。在每个步骤中,首先使用阶段性强化学习策略训练的合成器网络预测下一个绘画区域,然后使用经过WGAN鉴别器训练的绘画器网络预测笔画参数,最后笔画渲染器将笔画绘制到当前画布的绘画区域上。
此外,我们还通过一种新颖的可微分距离变换损失将我们的方法扩展到基于笔画的风格转移,这有助于在基于笔画的风格化过程中保留输入图像的结构。大量实验证明,我们的模型在基于笔画的神经绘画和基于笔画的风格化方面优于现有模型。
04 基于运动提示学习的动作识别研究
Seeing in Flowing: Adapting CLIP for Action Recognition with Motion Prompts Learning
Qiang Wang, Junlong Du, Ke Yan, Shouhong Ding
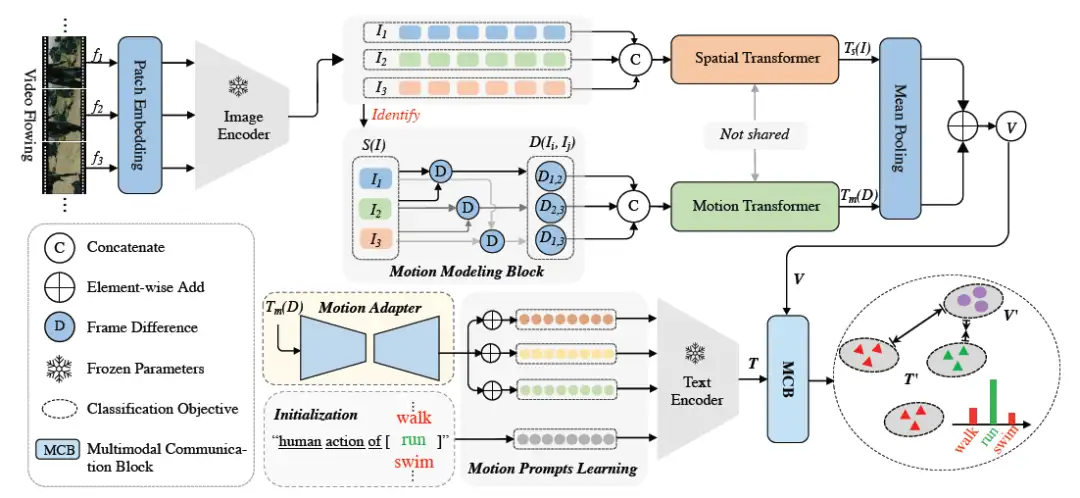
近期,大规模图文预训练模型(CLIP)在零样本(zero-shot)训练中展现出显著的泛化能力,并在多种下游任务中得到广泛应用。本文探讨了基于CLIP模型实现更高效、更通用的动作识别算法。本文提出,将CLIP迁移到动作识别任务的关键在于对视频帧中流动的运动信息进行显式建模。为此,本文设计了一种新型的双流运动捕捉模块,同时获取帧间运动信息和空间信息,然后利用运动信息驱动动态提示学习器生成运动感知提示。此外,我们还提出了一种多模态通信模块来实现协作学习,并进一步提高动作识别效果。
在HMDB-51、UCF-101和Kinetics-400数据集上的实验证明,本文提出的方法在少样本(few-shot)和零样本(zero-shot)训练方面明显优于现有的SOTA方法。同时,该方法仅需极少的可训练参数和额外的计算成本,便可在全量训练(closed-set)中取得与完全微调(fully-finetune)方法相当的效果。
05 基于个体和全局熵的半监督学习方法
Entropy-based Optimization on Individual and Global Predictions for Semi-Supervised Learning
Zhen Zhao, Meng Zhao, Ye Liu, di yin, Luping Zhou (University of Sydney)
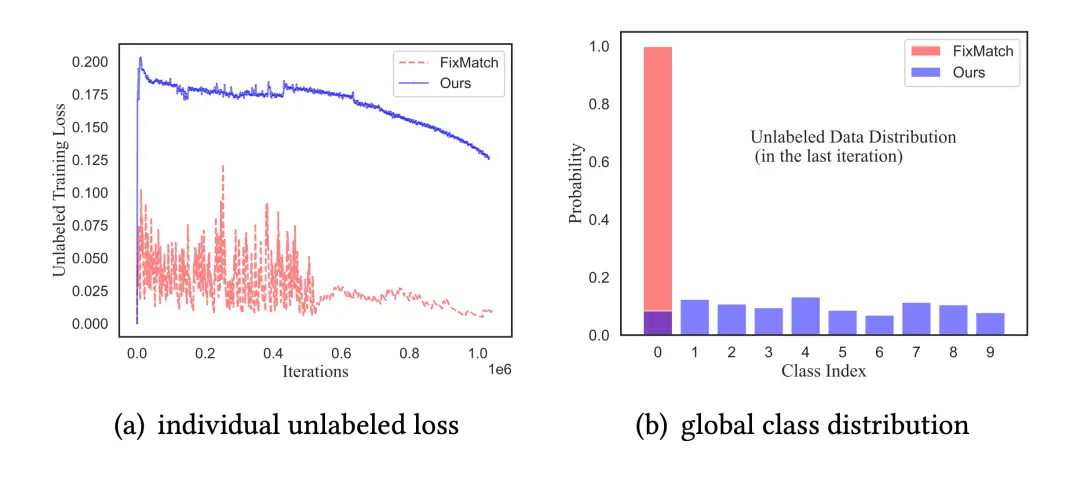
基于伪标签的半监督学习(SSL)已经被证明能显著提升模型在大规模未标注数据上的性能。然而,现有的研究大部分都致力于纠正每个未标注样本独立的预测,而忽略了全局性的信息,这种疏忽会导致在半监督学习中模型坍塌或性能下降,特别是在标签类别稀缺的场景下。
在本文,我们认为全局约束十分重要,并提出了一种半监督学习方法EntInG,此方法同时对个体和全局进未标注实例行熵优化。我们使用了两种手段来影响未标注数据:最小化个体预测熵(IPEM)和最大化全局分布熵(GDEM)。一方面,我们认为主流的SSL方法可以看作是可优化的隐式IPEM。另一方面,我们创造了一种新的分布损失来激励GDEM,这极其有利于为未标注数据打上更好的伪标签。理论分析还表明我们提出的方法能使得未标注数据强制互信息最大化。简而言之,我们的方法在常见的SSL基线上获得了显著的准确率提升。
06 基于底层线索和局部指引的弱监督目标定位
LocLoc: Low-level Cues and Local-area Guides for Weakly Supervised Object Localization
Xinzi Cao, Xiawu Zheng, Yunhang Shen, Ke Li, Jie Chen, Yutong Lu, Yonghong Tian.
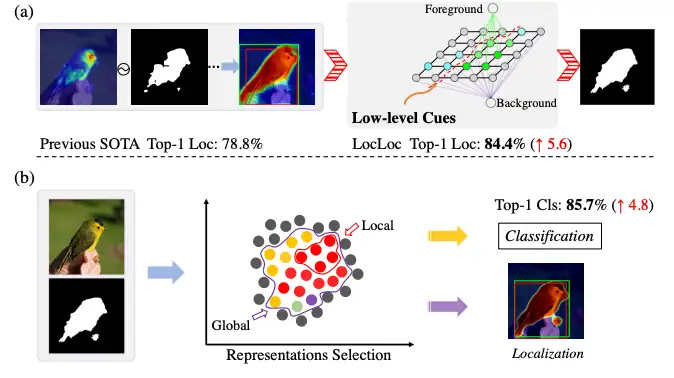
弱监督目标定位(WSOL)旨在仅使用图像级标签定位目标,同时确保具有竞争性的分类性能。然而,以往的研究更注重于判别特征中的定位而非分类准确性,而忽略了低级信息。我们认为,低级图像表示(如边缘、颜色、纹理和动态)对于准确检测至关重要。也就是说,使用这些信息可以进一步实现更精细的定位,从而提高分类准确性。
在本文中,我们提出了一个统一的框架,同时提高了定位和分类准确性,称为LocLoc(低级线索和局部指引)。它利用低级图像线索探索全局和局部表示,以实现准确的定位和分类。具体地,我们引入了一个GrabCut增强生成器(GEG),通过基于图割的全局语义表示来增强低级信息,利用变换器捕获的长距离依赖关系。我们进一步设计了一个局部特征挖掘模块(LFDM),利用低级线索来指导局部特征表示的学习路径,以实现准确的分类。广泛的实验表明,LocLoc在CUB-200-2011上具有84.4%(↑5.2%)的Top-1Loc.,85.8%的Top-1 Cls.,在ILSVRC 2012上具有57.6%(↑1.5%)的Top-1 Loc.,78.6%的Top-1 Cls.,表明我们的方法与以往的方法相比具有很大的竞争优势。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
RecursiveDet | 超越Sparse RCNN,完全端到端目标检测的新曙光
ICCV 2023 | ReDB:可靠、多样、类平衡的域自适应3D检测新方案!
ICCV2023 | 清华大学提出FLatten Transformer,兼顾低计算复杂度和高性能
ICCV'23 | MetaBEV:传感器故障如何解决?港大&诺亚新方案!
RCS-YOLO | 比YOLOv7精度提高了2.6%,推理速度提高了60%
国产130亿参数大模型免费商用!性能超Llama2-13B支持8k上下文,哈工大已用上
KDD 2023奖项出炉!港中文港科大等获最佳论文奖,GNN大牛Leskovec获创新奖
大连理工联合阿里达摩院发布HQTrack | 高精度视频多目标跟踪大模型
ICCV 2023 | Actformer:从单人到多人,迈向更加通用的3D人体动作生成
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary