论文阅读01-Attributed Graph Clustering: A Deep Attentional Embedding Approach
1. 创新点idea
- Two-step的图嵌入方法不是目标导向的,聚类效果不好,提出一种基于目标导向的属性图聚类框架。
所谓目标导向,就是说特征提取和聚类任务不是独立的,提取的特征要在一定程度上有利于聚类,那么如何实现?可以通过自训练聚类的方式,将隐藏图嵌入产生的软聚类分配与聚类联合优化。
- 提出图注意力自动编码器
2. 模型 model
1. two-step
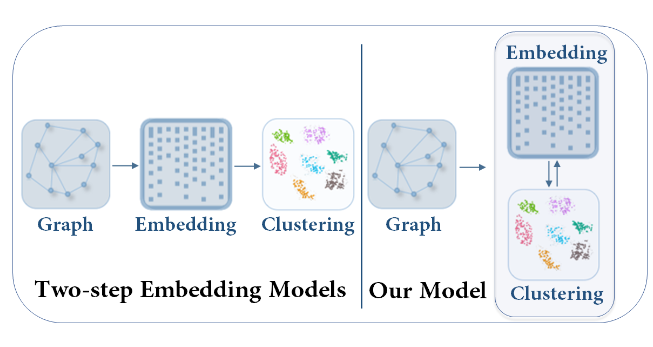
two-step 步骤:深度学习方法来学习紧凑图嵌入 embedding,在此基础上应用的聚类方法
two-step之前缺点:图嵌入的生成和聚类是两个独立的部分,通常会导致性能不佳。
这主要是因为图嵌入不是目标导向的,即专为特定的聚类任务而设计
DAEGC 解决办法:让模型图嵌入和聚类之间联合优化
2. 模型架构图
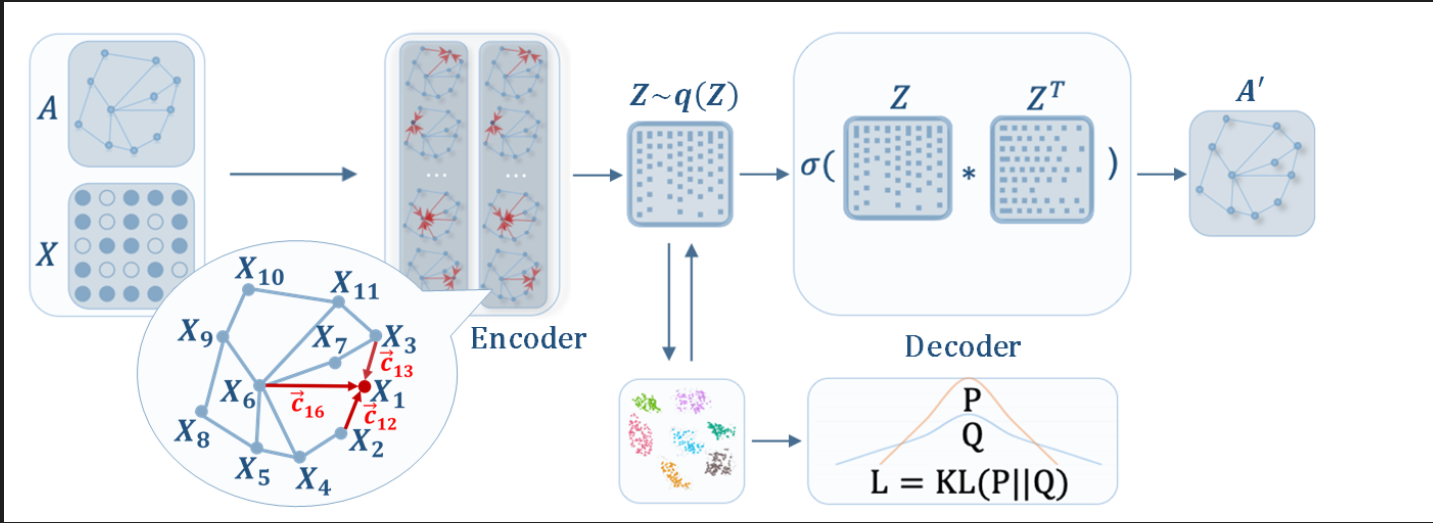
DAEGC通过基于图注意力的自动编码器学习隐藏表示 Z,并使用自训练聚类模块对其进行操作,该模块与自动编码器一起优化并在训练期间执行聚类.
DAEGC模型架构为两个部分:
图注意力自动编码器部分自训练聚类
自然而然的,该任务的目标函数就由两部分组成,重建损失和聚类损失:L=Lr+γLc 。
3. 图注意力自动编码器
DAEGC这篇论文的编码器在GAT 的基础上修改 作为图编码。原GAT论文 仅考虑 1 阶相邻节点(一阶)以进行图注意力。 DAEGC 认为图具有复杂的结构关系,建议在编码器中利用高阶邻居。我们通过考虑图中的 t 阶邻居节点获得邻近矩阵M: t参数可以根据实验结果,自己调节,也即是输入参数

接下来计算顶点之间的图注意力系数: 顶点间的图注意力是不对成的 即 aij 不等于aji
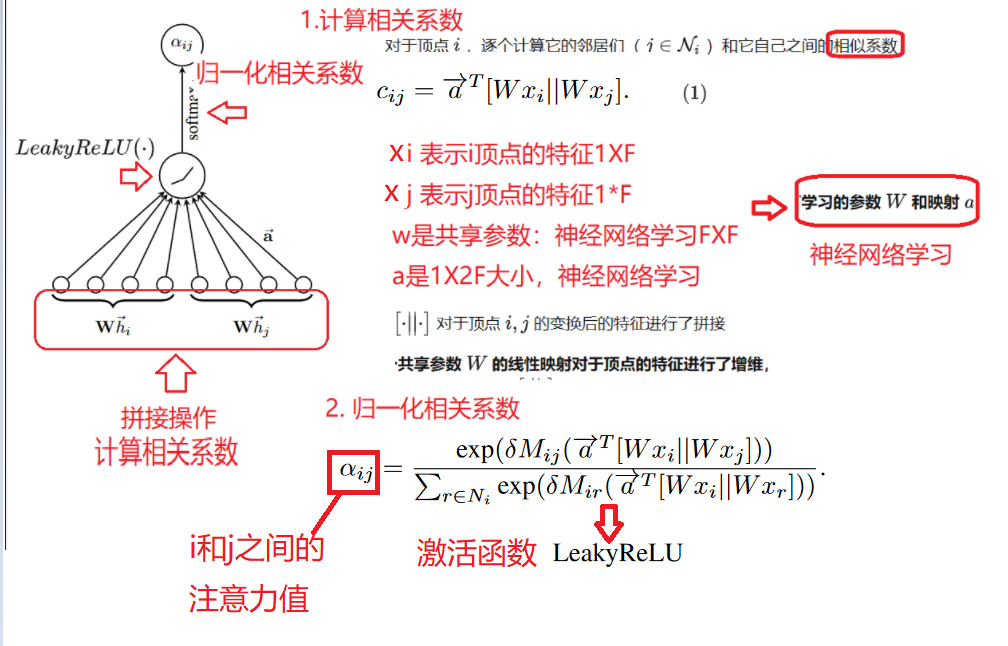
DAEGC 堆叠两层图注意层得到图注意力自动编码器的编码器部分:


解码器采用简单的内积:
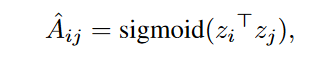
损失函数Lr:
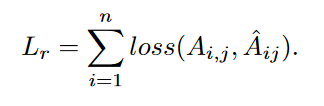
4. 自训练聚类模块
我们使用t-分布来衡量嵌入节点Zi 和簇中心节点Uu 之间的相似性。
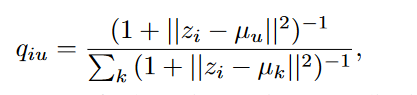
其他论文中公式:

qiu表示节点i属于簇u的概率,将其看作是每个节点的软聚类分配标签,如果值越大,那么可信度越高 。通过平方运算将这种可信度放大:
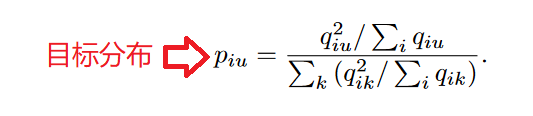
自训练聚类模块的损失函数采用KL 散度:
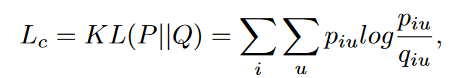
聚类损失然后迫使当前分布 Q 逼近目标分布 P ,从而将这些“置信分配”设置为软标签来监督 Q 的嵌入学习
因此DEAGC 模型总的损失函数L:

5. DAEGC 算法流程图、

6. DAEGC 模型参数和评价标准
DAEGC 参数设定:
我们将聚类系数 γ 设置为 10。我们考虑二阶邻居并设置 M = (B +B2)/2。编码器由一个 256 个神经元隐藏层和一个 16 个神经元嵌入层构成,适用于所有数据集。
DAEGC 评价指标:
使用四个指标 [Xia et al., 2014] 来评估聚类结果:准确性 (ACC)、归一化互信息 (NMI)、F 分数和调整兰德指数 (ARI)。
更好的聚类结果应该会导致所有指标的值更高。
7.实验结果分析
- 实验对比
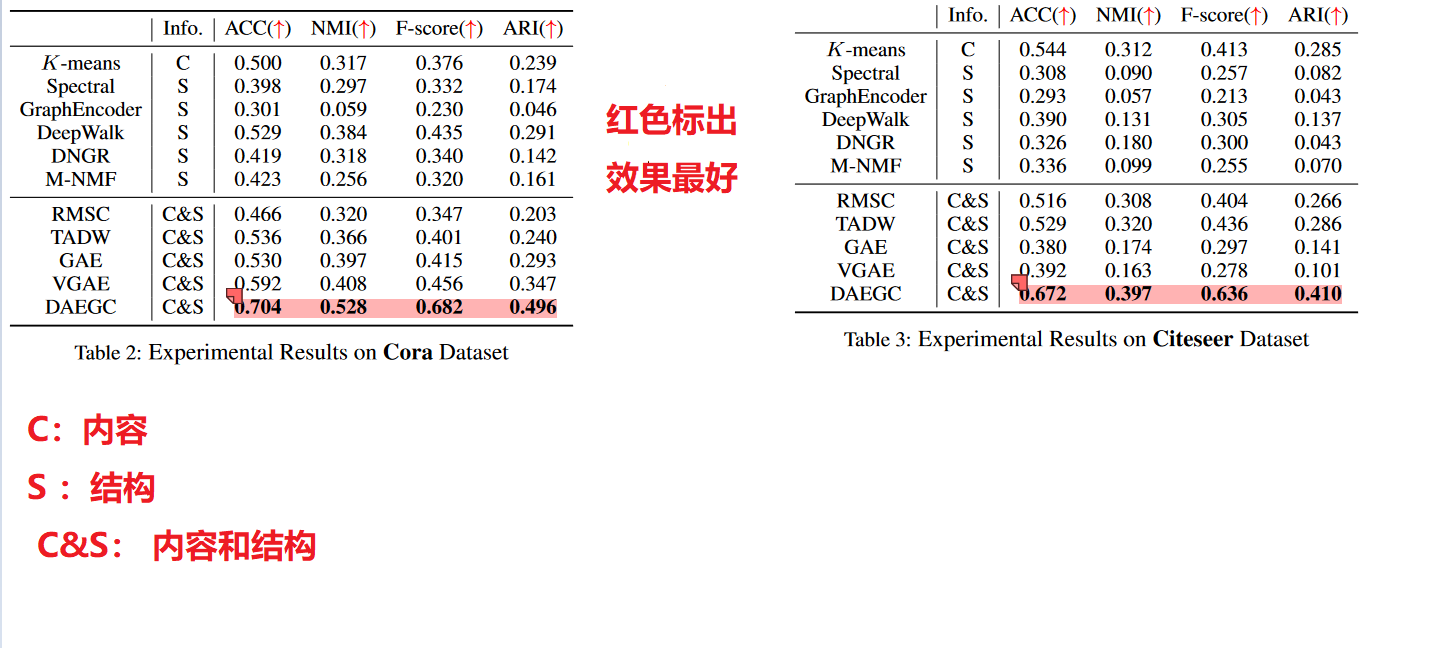
-
同时使用图的结构和内容信息的方法通常比仅使用图的一侧信息的方法表现更好 -
DAEGC模型为啥好:
(1)我们采用了图注意力网络,有效地整合了图的内容和结构信息;(2) 我们的自训练聚类组件在提高聚类效率方面专业而强大
- 嵌入层维度
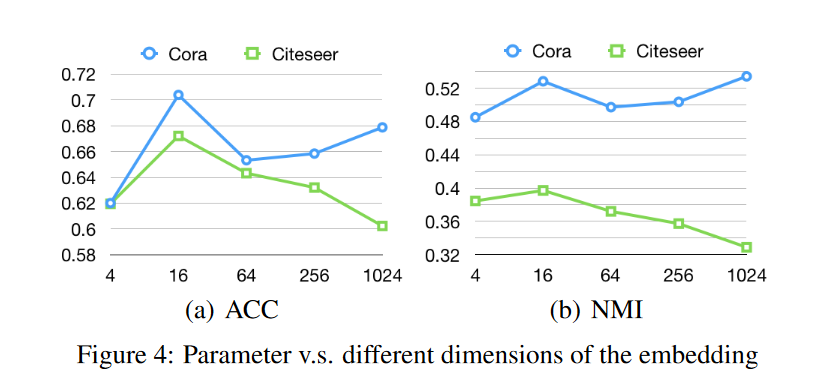
嵌入层维度分析:
当嵌入维度从 4 个神经元增加到 16 个神经元时,聚类性能稳步上升;但是当我们进一步增加嵌入层的神经元时,性能会有所波动,尽管 ACC 和 NMI 分数总体上都保持良好
- 可视化分析

第一个可视化说明仅使用图形注意自动编码器进行嵌入训练,然后是显示后续相等时期的可视化,其中包含自训练组件,直到最后一个是最终的嵌入可视化
额外知识补充
student t分布
对于 i 样本和 j 样本,我们使用 Student 的 t 分布作为核心来度量嵌入点 hi 和聚类中心向量 μj 之间的相似性,如下所示:
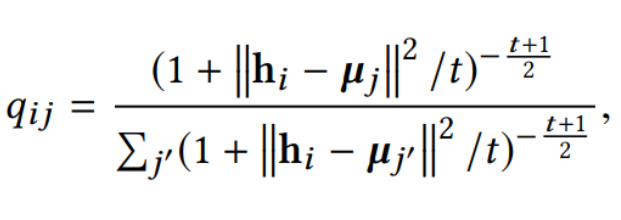
qij可以看作是将样本i分配给聚类j的概率,即软分配。
注意点: t=1
解释
我们无法在无监督环境中对验证集上的 t 进行交叉验证,并且学习它是多余的(van der Maaten,2009),我们让所有实验的 t= 1。
无监督的深度嵌入式聚类分析 - 知乎 (zhihu.com)
参考文献
无监督的深度嵌入式聚类分析 - 知乎 (zhihu.com)
论文阅读02——《Attributed Graph Clustering: A Deep Attentional Embedding Approach》 (marigold.website)
DAEGC 代码
出现问题解决办法:
在torch_geometric.datasets中使用Planetoid手动导入Core数据集及发生相关错误解决方案-阿里云开发者社区 (aliyun.com)
- Attentional Attributed Clustering Embedding Approachattentional attributed clustering embedding attributed clustering network mutual attentional attributed segmentation attentional semantic network representation heterogeneous attributed multiplex approach organizational behavioral management approach generating approach what best understand q-networks analytics approach