论文笔记:
Attributed Graph Clustering: A Deep Attentional Embedding Approach
-
中文名称: 属性图聚类:一种深度注意力嵌入方法
背景:
图聚类是发现网络中的社区或群体的一项基本任务。最近的研究主要集中在开发深度学习方法来学习紧凑图嵌入,并应用 k 均值或谱聚类算法等经典聚类方法。这些两步框架通常会导致性能不佳,主要是因为图嵌入不是目标导向的,即不是为特定的聚类任务而设计的。本文提出了一种目标导向的深度学习方法,深度注意力嵌入图聚类(简称DAEGC)。
通过使用图注意力网络(GAT)来捕获相邻节点对目标节点的重要性,DAEGC 算法将图中的拓扑结构和节点内容进行编码,在此基础上训练内积解码器来重建图结构。此外,还生成来自图嵌入本身的软标签来监督自训练图聚类过程,从而迭代地细化聚类结果。自训练过程与图嵌入在统一框架中共同学习和优化.
简单的区别如下图(摘自论文):
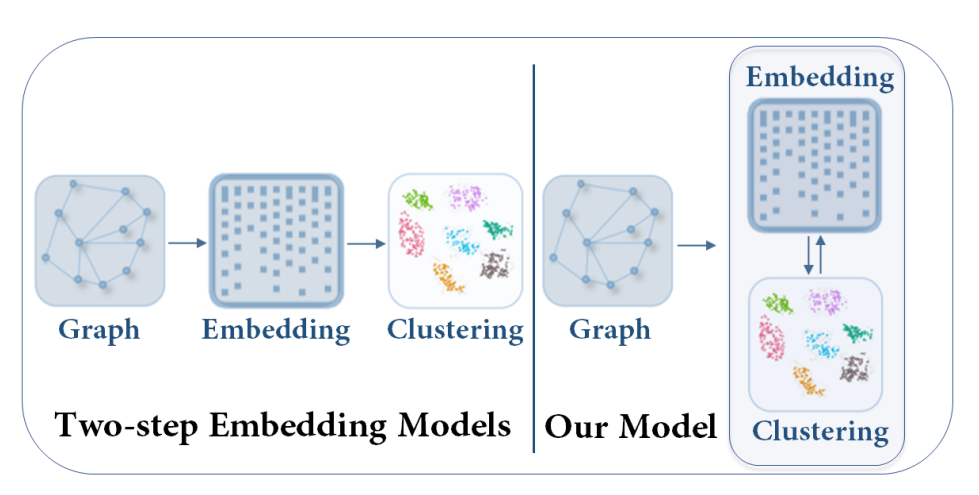
-
在上图中, 左边时传统的图聚类过程, 右边是本篇论文所研究的图聚类过程.
-
Embedding表示的是图嵌入的过程, 通过编码器将高维紧凑的图矩阵降维到低维紧凑的矩阵.
-
Clustering即是对降维后的数据进行聚类, 通常用k-means或者谱聚类等.
算法介绍:
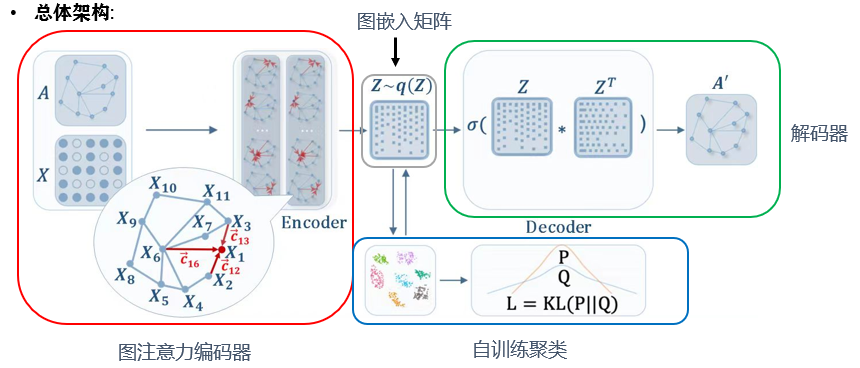
-
具体算法:
- 图注意力编码器:
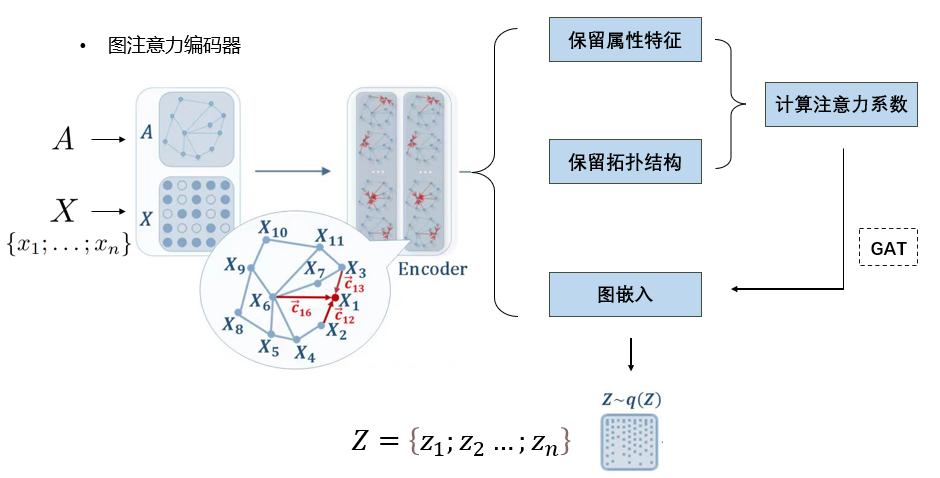
- 这里采用的Encoder是图注意力神经网络(GAT), 关于他的具体内容可以参考论文: Graph Attention Networks
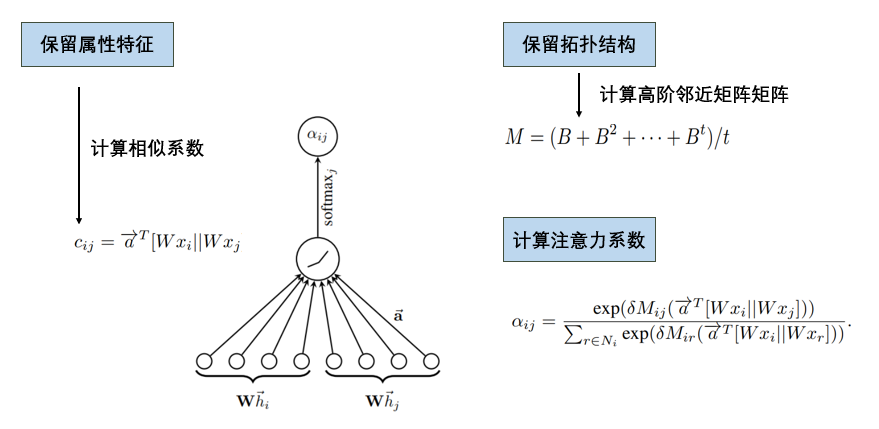
- 计算相似系数的目的是为了保留每个节点的属性特征的相似性, 计算高阶邻近矩阵是为了保留每个节点的拓扑结构
- 在计算高阶邻接矩阵的时候, \(B\) 矩阵是邻接矩阵的变形, 首先我们有图结构的邻接矩阵\(A\), \(A_{ij}\) 表示的是第i个节点和第j个节点是否存在边, 在\(B\) 中, 如果第i个节点和第j个节点存在边的话, \(B_{ij}\)表示的是 \(1/d_{ij}\) , 其中\(d_{ij}\)表示的是第i个节点的度, 相当于对每一行进行了归一化 , 这样的好处是可以有效衡量每个邻居的重要性, 而进行高阶的目的是为了表示拓扑结构的高阶隐藏属性, 不仅仅关注1阶.加入\(M_{ij}\)是论文与原来的GAT的不同之处.
- 之后让\(c{ij}\cdot M_{ij}\) , 最后用softmax函数求得注意力系数\(\alpha_{ij}\) ,就成功地表示了第j个节点对第i个节点的重要性.
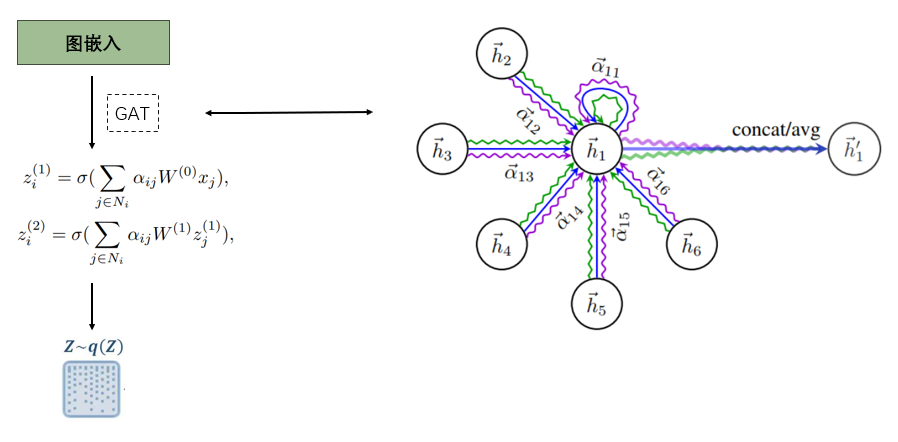
-
计算出注意力系数之后, 构建两层图神经网络, 对每个节点的属性值进行更新, 加权求和, 最终得到每个节点的图嵌入向量, 构成矩阵\(Z\), 其中\(Z_i\)表示的是第i个节点的信息, 此处仍可以参考论文:Graph Attention Networks.
- 解码器:
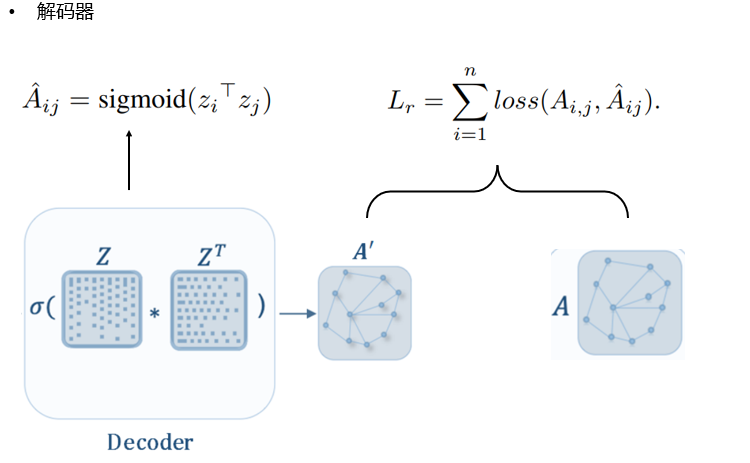
- 这里采用最简单的内积解码器, 因为我们知道点乘最后得到的标量值可以衡量两个向量的相似度, 所以对\(A_{ij}\)进行sigmoid操作映射到(0,1)上表示的是第i个节点和第j个节点的相似度, 越大则代表更有可能有关系, 体现在邻接矩阵上就是有边, 越小则可能无关, 体现在邻接矩阵上就是无边, 所以目标转化成对解码的结果与原来的邻接矩阵进行损失函数的优化, 即\(L_r\).
3.自训练聚类:
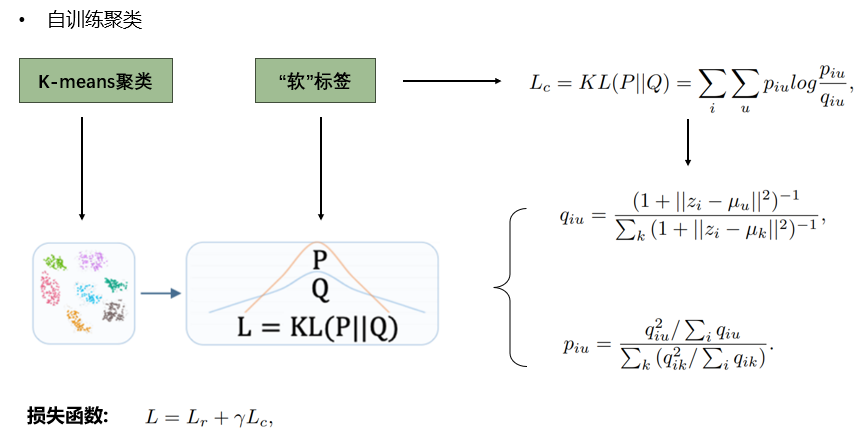
-
如今我们已经得到了可以表示图结构的拓扑结构和属性特征的图嵌入矩阵\(Z\)了, 下面要进行的就是聚类的操作.
-
由于聚类是无监督学习, 本文的改变之处就是为聚类设置了一个目标导向, 也就是提到的"软标签", 使得聚类结果更好地为嵌入过程提供反馈, 从而优化嵌入向量, 再由嵌入向量再次进行聚类, 如此迭代, 最终优化两种情况的目标损失函数的和最小即可.
-
这里无监督学习用的损失函数是\(L_c\)即为\(KL\)散度, 聚类算法用的是经典的k-means算法,\(u\)表示的是已经生成的最好的第u个中心点, \(q_{iu}\)表示的是第i个点属于第u个簇的概率, 这里借鉴了t-SNE算法映射概率的方式, 可以参考论文:Visualizing Data using t-SNE.
-
\(p_{iu}\)表示的是目标导向, 即用\(q_{iu}\)定义了另一组概率分布, 我们的目标是让\(p_{iu}\)和\(q_{iu}\)尽可能差距较小.
-
如何理解\(q_{iu}\), qiu即对每一个点都算出它属于每个簇的概率, 假设我们有3个簇, 那么我们可以认为给了第i个点一个3维的向量, 第u维表示它属于第u个簇的概率(u=1,2,3).
-
如何理解\(p_{iu}\), 我们先固定一个簇u, 然后对所有点进行进行第u维的叠加, 即\(\sum_{i}{q_{iu}}\), 接着我们先假如分子上是\(q_{iu}\), 而不是平方项, 那么我们所得到的\(q_{iu}\)即为:
\[p_{ij} = \frac{q_{iu}\sum_{i}{q_{iu}}}{\sum_{k}({q_{ik}/{\sum_{i}{q_{ik}}}})} \]下面我们同时给分子和分母乘上\(q_{iu}\), 该概率不变, 但是我们知道如果对于分母的每一项求和而言, 肯定有一项\(q_{ik}\)要大于其他的 \(q_{ik}\), 假设就是\(q_{iu}\)就是那项最大的概率, 那么分母的其他项本应该乘上的\(q_{ik}\)是要比\(q_{iu}\)小的, 所以变成\(q_{ik}^2\)之后就会分母变小, 分子不变, 从而原来属于第u簇的节点此时得到的\(p_{iu}\)更大, 起到了"强调"的作用.
-
最后要同时优化\(KL\)散度和\(L_r\), 即最后的损失函数如上图.
4.算法总流程:

实验结果:
查看论文: Attributed Graph Clustering: A Deep Attentional Embedding Approach
- Attentional Attributed Clustering Embedding Approachattentional attributed clustering embedding attributed clustering network mutual attentional attributed segmentation attentional semantic network representation heterogeneous attributed multiplex approach organizational behavioral management approach generating approach what best flow-based odometry approach scanner