1 前言
1.1 标题
Detecting Unknown Encrypted Malicious Traffic in Real Time via Flow Interaction Graph Analysis
1.2 摘要
为了保护网络的机密性和隐私性,目前互联网上的流量被广泛地加密。然而,流量加密技术经常被攻击者滥用,以掩盖其恶意行为。由于加密的恶意流量具有与良性流量相似的特征,因此可以很容易地逃避传统的检测方法。特别是,现有的加密恶意流量检测方法是受监督的,它们依赖于已知攻击的先验知识(例如,标记数据集)。实时检测未知加密恶意流量,不需要先验的领域知识,仍然是一个悬而未决的问题。
在本文中,我们提出了 HyperVision,一种基于实时无监督机器学习(ML)的恶意流量检测系统。特别是,HyperVision 能够通过利用基于流量模式构建的小型内存图来检测未知的加密恶意流量模式。该图捕获由图结构特征表示的流交互模式,而不是特定已知攻击的特征。我们开发了一种无监督图学习方法,通过分析图的连通性、稀疏性和统计特征来检测异常交互模式,这允许 HyperVision 检测各种加密攻击流量,而不需要任何已知攻击的标记数据集。此外,我们建立了一个信息论模型,证明图所保存的信息接近理想的理论边界。
我们通过 92 个数据集(包括 48 个加密恶意流量攻击)的实际实验展示了 HyperVision 的性能。实验结果表明,HyperVision 的 AUC 至少为 0.92,F1 为 0.86,明显优于现有方法。特别是在我们的实验中,超过 50%的攻击可以逃避所有这些方法。此外,HyperVision 的检测吞吐量至少为 80.6 Gb/s,平均检测时延为 0.83s。
————————————————
- 提出 HyperVision,一种基于无监督机器学习的实时的恶意流量检测系统。(无监督、机器学习、实时)
- 图捕获的是图结构特征表示的流交互模式,不是已知攻击的特征。
- 利用了图的连通性、稀疏性和统计特征。使用的是紧凑图。
- 建立了一个信息模型证明图保存的信息接近理想的理论界限。
1.3 introduce
- 传统的基于签名的利用深度包检测( Deep Packet Inspection,DPI )的方法在加密载荷的攻击下是无效的
对比现有恶意流量监测方法
与明文恶意流量不同,加密流量具有类似于良性流的特征,因此可以逃避现有的基于机器学习( Machine Learning,ML )的检测系统。特别地,现有的加密流量检测方法是有监督的,即依赖于已知攻击的先验知识,并且只能检测具有已知流量模式的攻击。它们提取特定已知攻击的特征,并使用已知恶意流量的标记数据集进行模型训练。
现有方法无法实现无监督检测,且无法检测模式未知的加密恶意流量。特别地,加密的恶意流量具有隐蔽性行为,这些方法无法根据单个流的模式检测攻击。然而,检测此类攻击流量仍然是可行的,因为这些攻击涉及多个攻击步骤,攻击者和受害者之间的流交互不同,这不同于良性的流交互模式。例如,垃圾邮件机器人和 SMTP 服务器之间的加密流交互显著不同于合法通信,即使攻击的单个流是相似的。
通过分析流之间的交互模式来捕获加密恶意流量的足迹。特别地,它可以通过识别异常的流交互,即与良性流不同的交互模式,来检测具有未知足迹的加密恶意流。为了实现这一点,我们构建了一个紧凑的图来捕获各种流交互模式,以便 HyperVision 可以根据该图对各种加密流量进行检测。该图允许我们在不访问数据包负载的情况下检测攻击,同时保留了使用明文流量检测传统(已知)攻击的能力。因此,HyperVision 可以通过学习来检测未知模式的恶意流量。同时,通过学习图结构特征,实现无监督检测,不需要有标记数据集进行模型训练。
- 不能使用简单的五元组来构图:
ip 为顶点,四元组为边
因为生成的稠密图无法保持各种流之间的交互模式,例如,引发了依赖爆炸问题。受流大小分布研究的启发,即互联网上的大多数流是短流,而大多数数据包与长流相关联,我们采用两种策略记录不同大小的流,并在图中分别处理短流和长流的交互模式。具体来说,它基于互联网上海量短流的相似性对短流进行聚合,降低了图的密度,并对长流进行分布拟合,可以有效地保留流交互信息 - 四步轻量级无监督学习方法,利用图上维护的丰富的流交互信息来检测加密的恶意流量
- 首先,通过提取连通成分来分析图的连通性,通过对高层统计特征进行聚类来识别异常成分。通过排除良性成分,我们也显著降低了学习开销。
- 其次,我们根据观察到的边缘特征中的局部邻接关系对边缘进行预聚类。预聚类操作显著降低了特征处理开销,保证了检测的实时性。
- 第三,我们通过使用 Z3 SMT 求解器求解顶点覆盖问题来提取关键顶点,以最小化聚类的数量。
- 最后,我们根据每个关键顶点的连边对其进行聚类,这些连边位于预聚类产生的簇的中心,从而获得表示加密恶意流量的异常边
量化基于图的 HyperVision 流记录对现有方法的好处的框架- -流记录熵模型,从理论上分析了恶意流量检测系统现有数据源保留的信息量。通过使用该框架,我们表明现有的基于抽样和基于事件的交通数据源(例如, netflow 技术和 Zeek )无法保留高保真的流量信息,因此,它们无法记录用于检测的流交互信息。但是,HyperVision 中的图为基于图学习的检测捕获了接近最优的流量信息,并且根据数据处理不等式,图中保持的信息量接近无限存储的理想化数据源的理论上行[ 85 ]。此外,分析结果表明,HyperVision 中的图比现有的所有数据源获得了更高的信息密度(也就是说,单位存储的流量信息),这是准确和高效检测的基础
- 使用 DPDK 进行原型开发
- VPC 中重放 92 个攻击数据集,其中包含 80 个新的数据集
- 加密泛洪流量,例如泛洪目标链接
- 网络攻击,例如利用 Web 漏洞
- 恶意软件活动,包括连接测试、依赖更新和下载
在存在背景流量的情况下,通过重放骨干网流量[ 80 ],HyperVision 实现了 13.9 % ~ 36.1 %的精度提高,超过了 5 个先进的方法。它以超过 0.92 AUC,0.86 F1 的无监督方式检测所有加密的恶意流量,其中 44 个真实的隐秘流量无法被所有基线识别,例如利用 CVE - 2020 - 36516 的高级侧信道攻击[ 26 ]和许多新发现的强制挖矿攻击[ 7 ]。此外,HyperVision 平均实现了超过 100 Gb / s 的检测吞吐量,平均检测延迟为 0.83 s。
1.4 威胁模型和设计目标
- 实时系统
流量来源
路由器通过端口镜像复制的流量,保证了系统不会干扰流量转发,可以配合现有的路径上恶意流量防御[ 48 ]、[ 49 ]、[ 88 ],对检测到的流量进行节流。为了对加密流量进行检测,我们无法解析和分析应用层报头和负载。
重点研究利用加密流量构造的主动攻击检测问题。我们不考虑不给受害者产生流量的被动攻击,例如流量窃听[ 68 ]和被动流量分析[ 70 ]。根据现有的研究[ 10 ],[ 24 ],[ 29 ],[ 40 ],[ 46 ],[ 81 ],攻击者利用侦察步骤探测受害者的信息,例如受害者的密码[ 39 ],TLS 连接的 TCP 序列号[ 26 ],[ 27 ],以及 Web 服务器的随机内存布局[ 75 ],这些信息由于缺乏先验知识而无法被攻击者直接访问。值得注意的是,这些攻击通常是由攻击者拥有或伪造的许多地址构造的
HyperVision 的设计目标如下:
首先,它应该能够实现通用检测,即检测由加密或非加密流量构造的攻击,这确保了攻击不能通过流量加密来逃避检测[ 2 ],[ 77 ]。其次,它能够实现实时高速的流量处理,这意味着它可以识别经过加密的流量是否为恶意的,同时具有较低的检测延迟。第三,HyperVision 执行的检测是无监督的,这意味着它不需要任何加密恶意流量的先验知识。也就是说,它应该能够处理未知模式的攻击,即零日攻击,而这些攻击尚未被公开[ 30 ]。因此,我们不使用任何带标签的流量数据集进行 ML 训练。现有的检测方法不能很好地处理这些问题。
1.5 HYPERVISION 概述
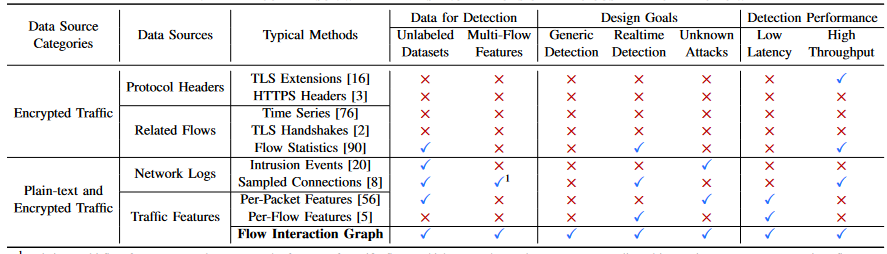
图 1 显示了 HyperVision 的三个关键部分,即图构建、图预处理和异常交互检测。
图形构造
HyperVision 收集网络流用于图形构建。同时,将流动分为短流和长流,并分别记录它们的交互模式,以降低图的密度。在图中,它使用不同的地址作为顶点,分别连接与短流和长流关联的边。它聚合了大量相似的短流,为一组短流构建一条边,从而减少了维持流交互模式的开销。此外,该方法还拟合了长流中数据包特征的分布,构建了与长流相关的边缘,从而保证了高保真记录的流交互模式,同时解决了传统方法中粗粒度流特征的问题[36]。我们将在第四节中详细介绍 HyperVision 如何在内存图中维护高保真流交互模式。
图形预处理
我们对构建的交互图进行预处理,通过提取连接的组件并使用高级统计信息对组件进行聚类来减少处理图的开销。特别是,聚类可以准确地检测仅具有良互模式的组件,从而过滤这些良性组件以减小图的规模。此外,我们执行预聚类,并使用生成的聚类中心来表示已识别集群的边。
基于图的恶意流量检测
我们通过分析图特征,实现无监督加密的恶意流量检测。我们通过求解顶点覆盖问题来识别图中的关键顶点,这确保了基于聚类的图学习以最少的聚类次数处理所有边。对于每个选定的顶点,我们根据其流动特征和代表流动相互作用模式的结构特征对所有连接的边进行聚类。HyperVision 可以通过计算聚类的损失函数来实时识别异常边缘。我们将在第六节中描述基于图学习的检测的细节
2 系统构建
2.1 图形构建
2.1.1 流量分类
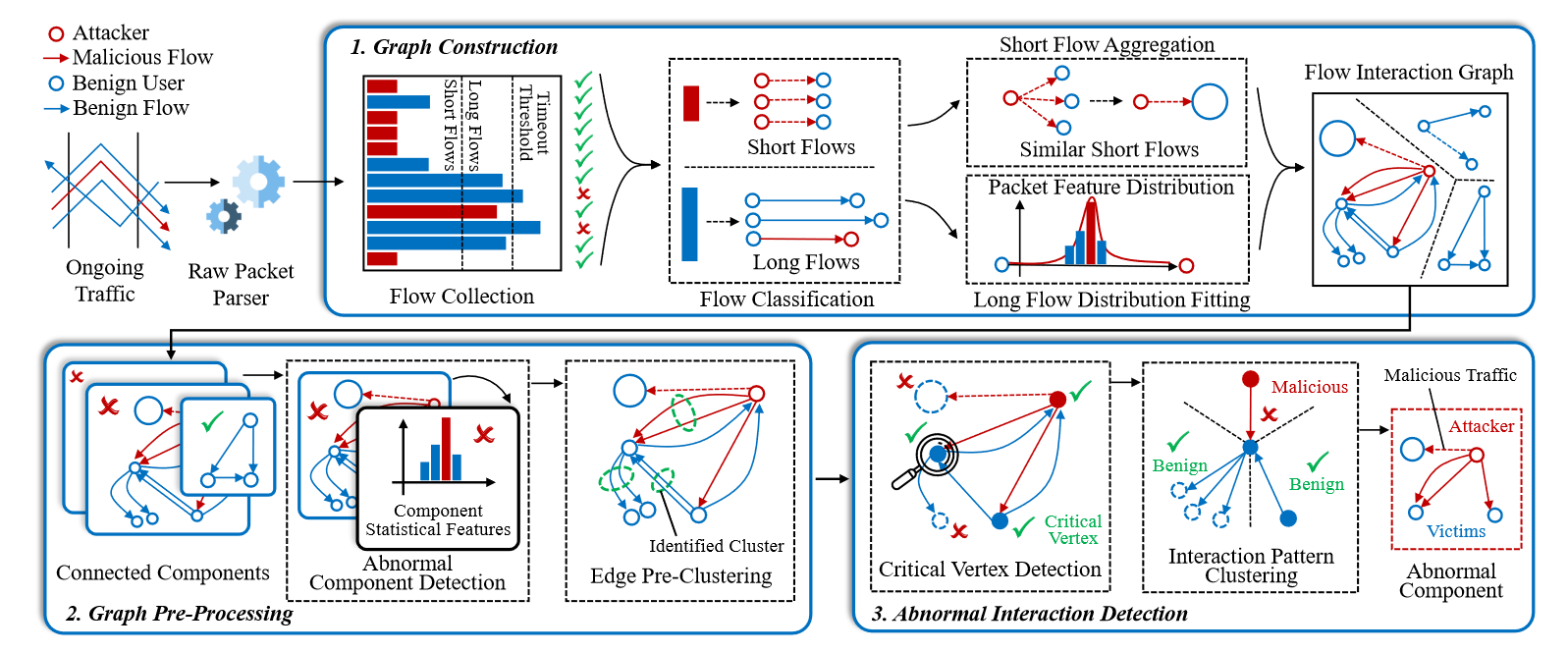
为了有效地分析在互联网上捕获的流,我们需要避免图构建过程中流之间的依赖爆炸。我们根据流量大小分布[25]将收集到的流量分为短流量和长流量(见图 2),然后降低图形的密度
图 2 显示了 2020 年 1 月 MAWI 互联网流量数据集[80]的流完成时间(FCT)和流长分布。为简单起见,我们使用前 13 × 1e6 个数据包来绘制该图。根据该图,我们观察到只有 5.52% 的流量具有 FCT > 2.0s。然而,数据集中 93.70%的数据包是长流,只有 2.36%的比例。受观察结果的启发,我们对短流和长流应用了不同的流量收集策略
我们从数据平面高速数据包解析引擎轮询每个数据包的信息,并获取它们的源地址和目标地址、端口号和每个数据包的特征,包括协议、长度和到达间隔。这些特征可以从加密和纯文本流量中提取,以进行通用检测。我们开发了一种流量分类算法来对流量进行分类(参见附录 A 中的算法 1)。它维护一个计时器 TIME NOW,这是一个哈希表,它使用 HASH(SRC, DST, SRC PORT, DST PORT) 作为键,并将收集的流由其每个数据包特征的序列指示为值。它根据 TIME NOW 每 JUDGE INTERVAL 秒遍历一次哈希表,并在 TIME NOW 的 PKT TIMEOUT 秒之前判断最后一个数据包到达时的流完成情况。流完成后,如果流的数据包超过 FLOW LINE,我们会将其归类为长流。否则,我们将它们归类为短流。如图 2(b)所示,我们可以准确地对短流和长流进行分类。超参数的定义见表七(见附录 A)。请注意,我们从数据平面轮询每个数据包的无状态信息,同时不在数据平面上维护流状态(例如,状态机 [89]),以防止攻击者操纵状态,例如,侧信道攻击 [65] 并逃避检测
2.1.2 短流量聚合
我们需要降低图的密度进行分析。如图 3(a)所示,如果我们使用传统的四元组流作为边,则该图将非常密集,这类似于来源分析中的依赖爆炸问题[83],[87]。我们观察到,大多数短流具有几乎相同的每个数据包的特征序列。例如,重复 SSH 破解尝试的加密流来自特定的攻击者[39]。因此,我们执行短流聚合,以在分类后使用一条边来表示相似的流。我们设计了一种聚合短流量的算法(参见附录 A 中的算法 2)。当满足以下所有要求时,可以聚合一组流:
- (i) 流具有相同的源地址和/或目标地址,这意味着从地址生成的类似行为;
- (ii) 流程具有相同的协议类型;
- (iii) 流量的数量足够大,即当短流量的数量达到阈值 AGG LINE 时,这确保了流量的重复性。
接下来,我们为短流构造一条边,它为所有流及其四元组保留了一个特征序列(即协议、长度和到达间隔)。因此,图上存在四种与短流相关的边类型,即源地址聚合、目标地址聚合、两个地址聚合和不聚合。因此,连接到边的顶点可以表示一组地址或单个地址。
比较使用传统流作为边的图和使用真实世界骨干流量数据集的聚合图,这与图 2 中使用的相同。顶点的直径表示表示的地址数由顶点和颜色的深度表示重复的边缘。在图 3(b) 中,我们观察到该算法减少了 93.94% 的顶点和 94.04% 的边。以绿色突出显示的边缘表示利用漏洞的短流量(即 2.38 Kpps,来自 PH)。请注意,流聚合减少了存储开销,这使得维护内存图以进行实时检测变得可行
2.1.3 长流量的特征分布拟合
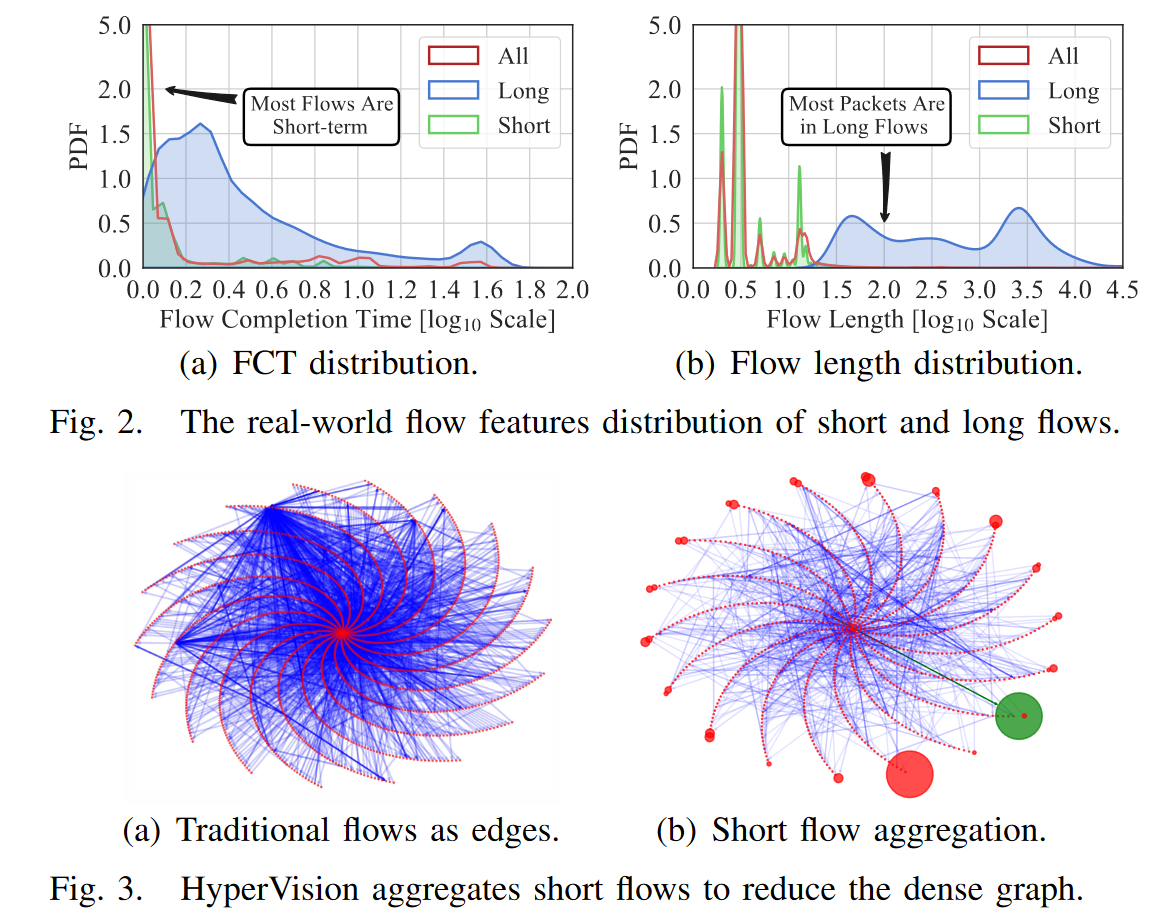
现在,我们使用直方图来表示长流的每包特征分布,从而避免保留其长的每包特征序列,因为长流中的特征是集中分布的。具体来说,我们维护一个哈希表来构建每个长流中每个数据包特征序列的直方图。根据我们的实证研究,我们将数据包长度和到达间隔的桶宽度分别设置为 10 字节和 1 毫秒,以在拟合精度和开销之间进行权衡。我们通过将每个数据包的特征除以存储桶宽度来计算哈希代码,并增加由哈希代码索引的计数器。最后,我们将哈希码和相关的计数器记录为直方图。请注意,粗粒度的流量统计信息,例如数据包数量[36],不足以进行加密的恶意流量检测[76],这也会丢失流交互信息
图 4 显示了图 2 所示的同一数据集中已使用的存储桶数量和长流的最大存储桶大小。我们确认了集中式特征分布,即长流中的大多数数据包具有相似的数据包长度和到达间隔。具体来说,在图 4(a) 中,我们平均仅使用 11 个存储桶来拟合数据包长度的分布,并且大多数存储桶收集的数据包超过 200 个(参见图 4(b)),这表明基于直方图的拟合在低存储开销下是有效的。同样,到达间隔的拟合平均使用 121 个桶,实现每个桶 71 个数据包的高利用率。此外,我们对协议使用相同的方法。由于协议类型数量有限,我们使用协议掩码作为哈希码,并使用较少数量的桶来实现更高效的拟合。请注意,Flowlens [5] 使用类似的直方图来有效地利用 P4 交换机上的硬件流量表。相反,我们构建直方图来准确分析长流
2.2 图预处理
2.2.1 连通性分析
DFS + 按组件拆分图形
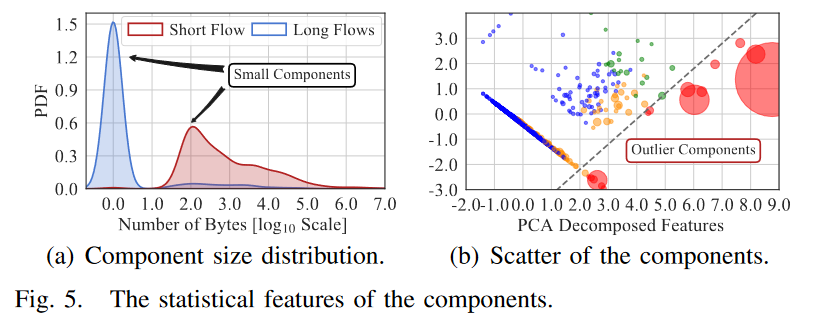
F5 a 展示了 2020 年 1 月收集的 MAWI 交通数据集[80]中已识别组件的大小分布。我们观察到,大多数组件包含很少具有相似交互模式的边缘。因此,我们对连接组件的高级统计数据进行聚类分析,以捕获比正常组件聚类损失超过一个数量级的异常组件作为聚类异常值。具体来说,我们提取了五个特征来分析组件,包括:(i)长流的数量;(ii)短流量的次数;(iii) 表示短流量的边缘数目;(iv) 长流中的字节数;以及 (v) 短流中的字节数。我们进行最小-最大归一化,并使用基于密度的聚类(即 DBSCAN)[32]获取中心。对于每个分量,我们计算到其最近中心的欧几里得距离。根据我们的实证研究,当异常分量的距离超过所有距离的第 99 个百分位数时,我们会检测到异常分量
图 5(b) 显示了聚类的一个实例,其中直径表示组件上的流量规模(以字节为单位)。我们观察到大多数成分都是小的,高比例的大成分被归类为异常。所有与正常组件关联的 Edge 都被标记为良性流量,与异常组件关联的 Edge 将按照以下步骤进行进一步处理。
2.2.2 边缘预集群
现在,我们需要进一步处理和预聚类图,以实现高效检测。如图 5 所示,图中的异常分量具有大量的顶点和边。特别是,我们不能直接应用图表示学习,例如图神经网络(GNN)进行实时检测。图 6 显示了图结构特征空间中组件的边缘。我们观察到边的分布是稀疏的,即大多数边与特征空间中的大量相似边相邻。为了利用稀疏性,我们使用 DBSCAN [32]进行预聚类,利用 KD-Tree 进行有效的局部搜索,并选择已识别聚类的聚类中心来表示每个聚类中的所有边,以减少图处理的开销。具体来说,我们分别提取了与短流和长流相关的边的八个和四个图形结构特征(见附录 A 中的表 V),例如,与长流相关的边的源顶点的度数。

恶意流量的这些程度特征与良性流量明显不同,例如,表示垃圾邮件机器人的顶点由于与服务器频繁交互而比良性客户端具有更高的外度。然后,我们对特征进行最小-最大归一化,并采用较小的搜索范围 ε 和较大的最小点数进行 DBSCAN 聚类(有关超参数的设置,请参阅第 VIII-A 节),以避免在聚类中包含不相关的边,这可能会产生误报。此外,某些边不能聚类,应被视为异常值,这些异常值将作为只有一条边的聚类进行处理。
2.3 恶意流量检测
我们通过识别图表上的异常交互模式来检测加密的恶意流量。特别是,我们将连接到同一关键顶点的边缘进行聚类,并将异常值检测为恶意流量
2.3.1 识别关键顶点
为了有效地了解流量的交互模式,我们不会直接对所有边执行聚类,而是对连接到关键顶点的边进行聚类。对于每个连接的组件,我们根据以下条件选择连接组件中所有顶点的子集作为关键顶点:(i)组件中每条边的源顶点和/或目标顶点都在子集中,这确保了所有边都连接到多个关键顶点并至少聚类一次;(ii)最小化子集中选定的顶点数量,旨在最小化聚类数量,以减少图学习的开销。找到这样一个顶点子集是一个优化问题,等价于顶点覆盖问题[33],它被证明是 NP 完备(NPC)。我们选择每个组件上的所有边和所有顶点来解决问题。我们将该问题重新表述为可满足性模理论(SMT)问题,该问题可以通过使用 Z3 SMT 求解器[55]有效解决。由于我们对大量边进行了预聚类并缩小了问题的规模(参见第 V-B 节),因此可以实时解决 NPC 问题
2.3.2 用于检测的边缘特征聚类
现在,我们将连接到每个关键顶点的边聚类,以识别异常的交互模式。在此步骤中,我们使用第 V-B 节中的结构特征,以及从短流的每数据包特征序列或长流的拟合特征分布中提取的流特征。所有功能均见表 V(见附录 A)。我们使用轻量级的 K-Means 算法分别对短流和长流相关的边缘进行聚类,并计算出表示恶意流检测恶意程度的聚类损失。
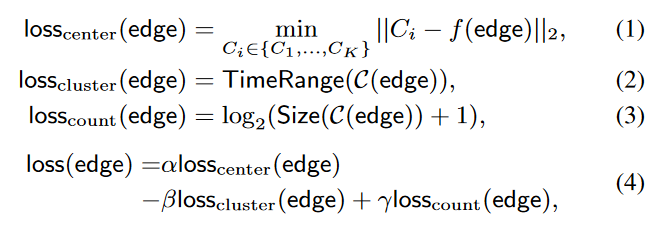
其中 K 是获得的聚类中心的数量,Ci 是第 i 个中心,f(edge)是特征向量,C(edge) 包含预聚类产生的边簇中的所有边,TimeRange 计算由边表示的流所覆盖的时间范围。根据等式(4),损失分为三个部分:(i)(1)中的损失中心是到聚类中心的欧氏距离,表示与连接到临界顶点的其他边的差异;(ii)(2)中的损失聚类表示由第 V-B 节中的预聚类确定的聚类所涵盖的时间范围,这意味着长期的相互作用模式往往是良性的;(iii) (3) 中的 losscount 是用边表示的流数,这意味着大量流的爆发意味着恶意行为。此外,我们使用权重:α、β γ 来平衡损失项。最后,当边缘的损失函数大于阈值时,它会将关联的流检测为恶意流
2.4 理论分析
在本节中,我们开发了一个理论分析框架,即流动记录熵模型,用于分析 HyperVision 图中保存的信息,用于基于图学习的检测。详细分析见附录 C
2.4.1 基于信息熵的分析
我们开发的框架旨在通过使用三个指标来定量评估现有流量记录模式保留的信息,这些模式决定了恶意流量检测的数据表示:(i)信息量,即记录一个数据包获得的平均香农熵;(ii) 数据的规模,即用于存储信息的空间;(iii) 信息密度,即存储单位上的信息量。通过使用该框架,我们对 HyperVision 使用的基于图的流量记录模式以及三种典型的流记录模式进行了建模,即(i)记录和存储整个每个数据包特征序列的理想化模式;(ii)记录特定事件的基于事件的模式(例如 Zeek)[2],[20];(iii)基于采样的模式(例如 NetFlow),记录粗粒度的流动信息[8],[51]
我们将一个流,即每个数据包的特征序列建模为由非周期性不可约离散时间马尔可夫链 (DTMC) 表示的随机变量序列。设 G = {V, E} 表示 DTMC 的状态图,其中 V 是状态集(即变量的值),E 表示边。我们定义 s = |V|作为不同状态的数量,并使用 W = [wij]s×s 来表示 G 的权重矩阵。所有权重都相等且归一化:
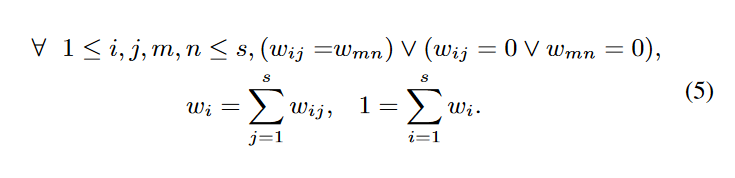
状态转换基于权重执行,即转换概率矩阵 P = [Pij],Pij = wij/wi。因此,DTMC 具有固定分布 μ:
我们进行了数值研究,以比较真实环境中的流量记录模式。我们选择三个每个数据包的特征:协议、长度和到达间隔(以毫秒为单位)作为 DTMC 的实例,然后我们测量 DTMC 的参数,即 |E|以及 |五|根据 2020 年 1 月 MAWI 数据集中的前 106 个数据包 [80]。我们还测量了 K、C,并通过第二个矩估计几何分布参数 q。我们有以下三个关键结果。
(1) 与现有方法相比,HyperVision 使用图形保留了更多的信息。图 8 显示了可行区域的结果 (F = {0.1 ≤ p ≤ 0.9, 0.5 ≤ q ≤ 0.9})。我们观察到,HyperVision 保持的信息熵至少是传统流采样和基于事件的流记录的 2.37 倍和 1.34 倍。因此,传统的检测方法无法保留高保真度的流动交互信息。实际上,它们只分析单个流的特征,这些特征可以通过加密流量来规避。根据图 8(b),基于采样的模式 HyperVision 的数据规模为 69.69%.这意味着数据尺度是现有方法利用流交互模式的关键挑战。我们通过使用紧凑图来维护流之间的相互作用,从而很好地解决了这个问题
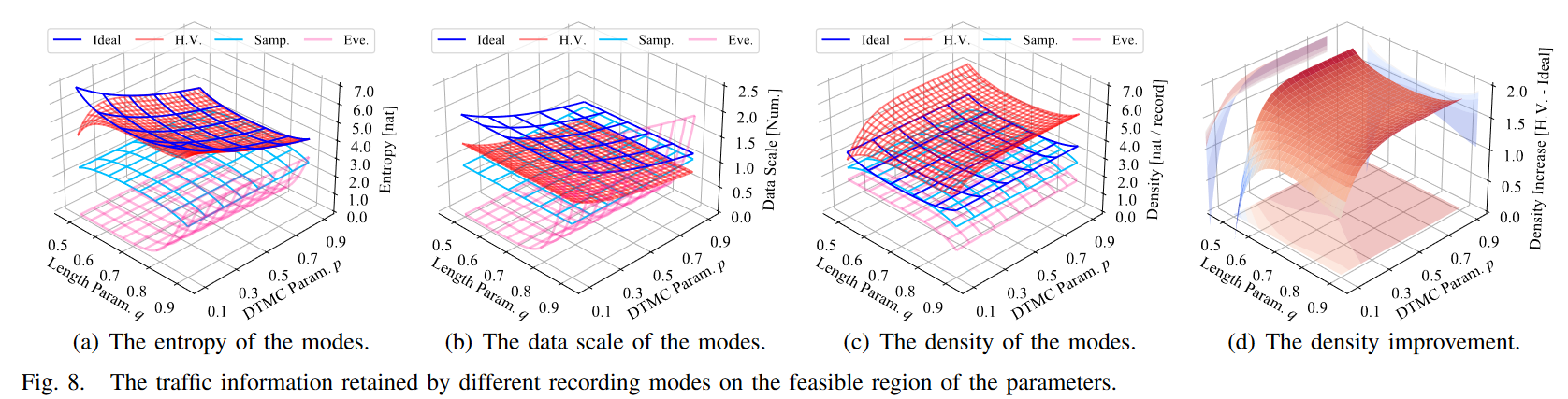
(2) HyperVision 使用图形保持接近最优的信息。根据图 8(a),我们观察到该图所维护的信息几乎等于理论最优值,差异范围为 4.6 × 10−9 至 2.6 nat。当 L 的几何分布参数趋近于 0.9 时,由于长流的比例越大,导致的信息损失越大,流动信息损失就越大。图 9 比较了 HyperVision 中的信息,以及 q = 0.59 和 p = 0.8 时的理想化系统。我们也有类似的结果。图模式和最优模式之间的差距仅为 0.056 和 0.021。
(3)HyperVision 比现有方法具有更高的信息密度。图 8(c)显示,HyperVision 的信息密度分别是现有方法的 1.46 倍、1.54 倍和 2.39 倍。理想化系统虽然实现了最优的交通信息量,但在最坏情况下,密度仅为 HyperVision 的 78.55%,如图 8(d)所示。从表二中,我们发现,对于各种每包特征,由于短流和长流的记录策略不同,HyperVision 可以增加 35.51%至 47.27%的密度。
综上所述,流交互图提供了高保真、低冗余的流量信息,具有明显的流交互模式,保证了 HyperVision 实现实时、无监督的检测,特别是对未知模式的加密恶意流量进行检测。
2.5 评价
数据。我们使用来自 AS2500 的 WIDE MAWI 项目[80]的 vantage-G 的真实骨干网络流量数据集,日本东京,2020 年 1 月 ∼6 月作为背景流量。有利位置使用连接到其 IXP (DIX-IE) 的 10 Gb/s 光纤传输流量,并使用端口镜像收集流量,这与上述威胁模型和物理测试平台一致。我们根据现有研究[22]、[43]、[66]定义的规则,在后台流量数据集中去除了具有明显模式的攻击流量,例如,如果流量扫描了超过 10%的 IPv4 地址[22],则流量将被检测为扫描流量。我们通过构建真实攻击或重放测试平台中的现有跟踪来生成恶意流量。具体来说,我们在具有 1500 多个实例的 Virtual Private Cloud (VPC) 中收集恶意流量。我们根据真实世界的测量结果[22]、[24]、[40]、[42]、[43]、[54]、[66]和现有研究[11]、[26]、[41]、[44]中的相同设置来操纵实例进行攻击。我们将实验中使用的 80 个新数据集(详见表 VI)分为四组,其中三组是加密的恶意流量:
-
传统的暴力攻击。虽然 HyperVision 专注于加密流量,但我们生成了 28 种传统的洪水攻击,以验证其通用检测和基线的正确性,包括 18 种高速率攻击和 10 种低速率攻击:(i)使用真实数据包进行暴力破解率 [22];(ii) 以不同速率欺骗 DDoS 的来源 [40];(iii)放大攻击[43];(iv)探测易受攻击的应用程序[21]、[22]。我们在 VPC 中收集流量,以避免对实际服务的干扰。
-
加密的泛洪流量。与暴力泛洪不同,加密泛洪是由针对特定应用的重复攻击行为产生的:(i)链路泛洪产生加密的低速率流,例如低速率 TCP 攻击[44]、[52]和 Crossfire 攻击[41],以拥塞链路;(ii)注入加密流,利用协议漏洞,淹没攻击流量,并将数据包注入信道[11]、[26]、[28];(iii)密码破解会缓慢地尝试劫持加密的通信协议[39],[50]。我们在 VPC 中执行 SSH 破解,ASes 中的 SSH 服务器规模可达 AS2500。
-
加密的 Web 恶意流量。Web 恶意流量通常由 HTTPS 加密。我们收集了七种广泛使用的网络攻击产生的流量,包括自动漏洞发现(包括 XSS、CSRF、各种注入)[64]、SSL 漏洞检测 [53] 和爬虫。我们还收集 SMTP-over-TLS 垃圾邮件流量,引诱受害者访问网络钓鱼网站[61]。
-
恶意软件生成的加密流量。恶意软件活动的流量是低速率和加密的,例如恶意软件组件更新或交付[9]、命令和控制(C&C)通道[8]和数据泄露[77]。我们使用 2020 年发布的恶意软件感染统计数据 [42] 和从采用的有利位置探测的活跃地址 [23]、[59] 来估计可见受害者的数量。我们使用相同数量的实例来重放公共恶意软件流量数据集[13],[73]来模拟恶意软件活动,这与现有研究[58]相似。
恶意流量根据其原始数据包速率[80]与物理测试台上的后台流量数据集同时重放,这与现有研究[30],[47],[51]相同。具体来说,每个数据集包含 12∼1500 万个数据包,回放持续 45s,前 75% 的时间不包含用于收集流交互和训练基线的恶意流量。请注意,我们数据集中的加密攻击流速率仅为 0.01 ∼ 8.79 Kpps,仅消耗 0.01% ∼ 0.72% 的带宽。我们将证明这些隐蔽的攻击规避了大多数基线
为了消除数据集偏差的影响,我们还使用了 12 个现有数据集,包括 Kitsune 数据集 [56]、CICDDoS2019 数据集 [14] 和 CIC-IDS2017 数据集 [15],这些数据集是在现实世界中收集的。这些详细结果可在附录 B2 中找到。特别是,两个 CIC 数据集[14]、[15]中的流量在多次攻击下持续 6∼8 小时,旨在验证 HyperVision 的长期性能(见附录 B3)。此外,我们通过混淆技术验证了 HyperVision 对规避攻击的鲁棒性,这可以在附录 B4 中找到。
基线。我们使用五种最先进的通用恶意流量检测方法作为基线:
• Jaqen(基于采样的记录和基于签名的检测)。Jaqen [51] 使用 Sketches 来获取流量统计数据,并应用基于阈值的检测。我们在测试平台上对 Jaqen 进行原型设计,并调整每个统计数据和每个攻击的特征以获得最佳准确性。
• FlowLens(基于采样的记录和基于 ML 的检测)。FlowLens [5] 使用采样流分布和监督学习,即随机森林。我们使用本文中使用的具有最佳准确性的超参数设置来重新训练 ML 模型。
• Whisper(流量级特征和基于 ML 的检测)。Whisper[30],[31]提取了流动的频域特征,并使用聚类来学习这些特征。我们在物理测试平台上部署 Whisper,无需修改,然后重新训练聚类模型。
• Kitsune(数据包级功能和基于 DL 的检测)。Kitsune 提取每个数据包的特征,并使用自动编码器来学习特征,这是一种无监督方法[56]。我们使用其默认的超参数并重新训练模型。
• DeepLog(基于事件的记录和基于深度学习的检测)。DeepLog 是一个使用 LSTN RNN 的通用日志分析器[20]。我们使用连接日志进行检测,并利用其独创的超参数设置来达到最佳精度。
请注意,在上面的基线中,我们不包括基于 DPI 的加密恶意流量检测,因为它们无法调查加密的有效负载 [34]。此外,我们没有比较特定任务的检测方法[3],[76],因为它们无法达到可接受的检测精度。FlowLens、Kitsune 和 Whisper 中的功能与它们类似,例如流特征 [3]、数据包标头特征 [2] 和时间序列 [76]。
指标。我们主要使用 AUC 和 F1 评分,因为它们在文献中使用最广泛[8],[20],[30],[35],[56],[75],[91]。此外,我们还使用其他六个指标来验证 HyperVision 的改进,包括精确率、召回率、F2、ACC、FPR 和 EER。
超参数选择。我们进行四重交叉验证,以避免过度拟合和超参数偏差。具体来说,数据集平均分为四个子集。每个子集用作一次验证集,通过实证研究调整超参数,其余三个子集用作测试集。最后,对四个结果进行平均以产生最终结果。此外,我们的消融研究表明,不同的阈值设置最多会导致 5.2% 的精度损失。因此,超参数选择对检测结果的影响有限。
- Interaction Detecting Encrypted Malicious Analysisinteraction detecting encrypted malicious malicious encrypted detecting 脚本encrypted证书let probabilistic perspective geometric detecting detecting provider allowed代码 biomarkers detecting external systemic interaction interaction prediction eulernet adaptive