发表时间:2021(ICML 2021)
文章要点:这篇文章提出了demonstration-conditioned reinforcement learning (DCRL)来做Few-Shot Imitation,将demonstration和当前状态作为输入,通过强化学习最大化任务相关的reward。
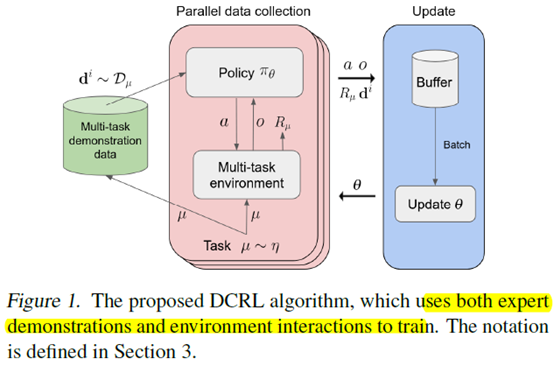
具体方式就是把demonstration放到buffer里面,然后agent还是和环境交互,用强化的方式进行训练,只是这个policy的输入会有当前的状态和要模仿的demonstration,然后训练的时候buffer里的样本都会用上,包括demonstration。强化的算法用的PPO,Policy的结构用的transformer

具体算法如下

总结:这个Few-Shot Imitation的假设有点强了,首先要有需要模仿的demonstration,然后还可以和环境交互做强化训练,而且还知道各个task的reward function。虽然说是few-shot了,但是放宽了很多其他条件。
疑问:这个真的是imitation learning吗,我怎么看怎么觉得是个强化学习的过程啊,又要和环境交互,又有reward function,真的可以吗?要说imitation,唯一的点也就是把demonstration放进buffer里了啊好像。
- Demonstration-Conditioned Demonstration Reinforcement Conditioned Imitationdemonstration-conditioned demonstration reinforcement demonstration-conditioned imitation demonstration conditioned camera-conditioned self-conditioned camera camera-conditioned re-identification self-conditioned representations conditioned reinforcement