一. Motivation
1. Transformer在解决全局表现很好,但是复杂度很高,主要体现在QK的乘积: (We note that the scaled dot-product attention computation is actually to estimate the correlation of one token from the query and all the tokens from the key)
在self-attention中:

二. Contribution
1. 使用逐点乘法操作来估计矩阵惩罚,基于频域的方法,用于高效计算自注意力,从而降低了计算的复杂性
2.简单使用FFN不能产生很好的结果,所以设计了一个基于鉴别频域的DFFN模块,在FFN中引入门控机制,以区分地确定应该保留哪些低频和高频信息以进行图像恢复
3. Network
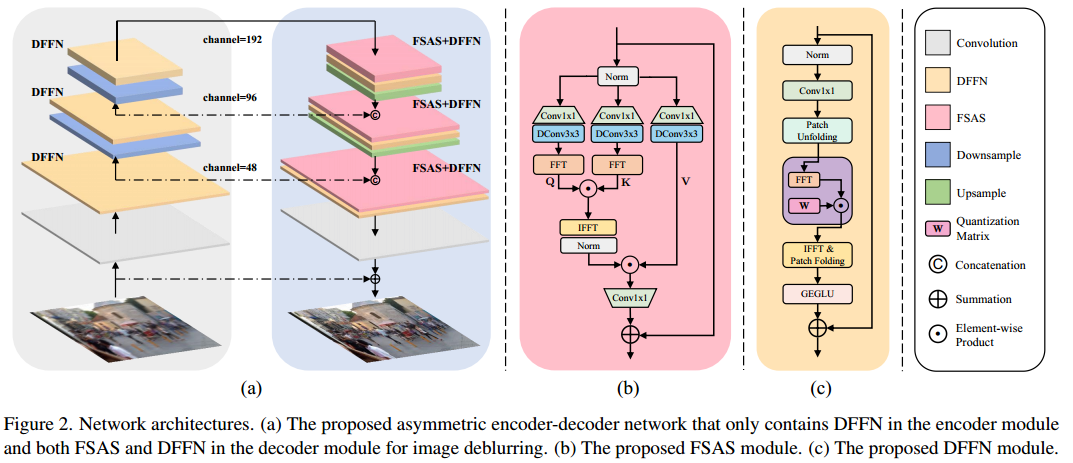
1.FSAS
class FSAS(nn.Module): def __init__(self, dim, bias): super(FSAS, self).__init__() self.to_hidden = nn.Conv2d(dim, dim * 6, kernel_size=1, bias=bias) self.to_hidden_dw = nn.Conv2d(dim * 6, dim * 6, kernel_size=3, stride=1, padding=1, groups=dim * 6, bias=bias) self.project_out = nn.Conv2d(dim * 2, dim, kernel_size=1, bias=bias) self.norm = LayerNorm(dim * 2, LayerNorm_type='WithBias') self.patch_size = 8 def forward(self, x): hidden = self.to_hidden(x) q, k, v = self.to_hidden_dw(hidden).chunk(3, dim=1) q_patch = rearrange(q, 'b c (h patch1) (w patch2) -> b c h w patch1 patch2', patch1=self.patch_size, patch2=self.patch_size) k_patch = rearrange(k, 'b c (h patch1) (w patch2) -> b c h w patch1 patch2', patch1=self.patch_size, patch2=self.patch_size) q_fft = torch.fft.rfft2(q_patch.float()) k_fft = torch.fft.rfft2(k_patch.float()) out = q_fft * k_fft out = torch.fft.irfft2(out, s=(self.patch_size, self.patch_size)) out = rearrange(out, 'b c h w patch1 patch2 -> b c (h patch1) (w patch2)', patch1=self.patch_size, patch2=self.patch_size) out = self.norm(out) output = v * out output = self.project_out(output) return output
2. DFFN
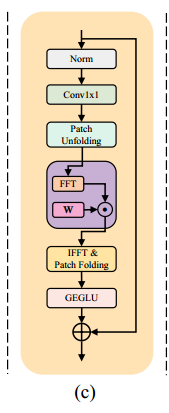
class DFFN(nn.Module): def __init__(self, dim, ffn_expansion_factor, bias): super(DFFN, self).__init__() hidden_features = int(dim * ffn_expansion_factor) self.patch_size = 8 self.dim = dim self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias) self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1, groups=hidden_features * 2, bias=bias) self.fft = nn.Parameter(torch.ones((hidden_features * 2, 1, 1, self.patch_size, self.patch_size // 2 + 1))) self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias) def forward(self, x): x = self.project_in(x) x_patch = rearrange(x, 'b c (h patch1) (w patch2) -> b c h w patch1 patch2', patch1=self.patch_size, patch2=self.patch_size) x_patch_fft = torch.fft.rfft2(x_patch.float()) x_patch_fft = x_patch_fft * self.fft x_patch = torch.fft.irfft2(x_patch_fft, s=(self.patch_size, self.patch_size)) x = rearrange(x_patch, 'b c h w patch1 patch2 -> b c (h patch1) (w patch2)', patch1=self.patch_size, patch2=self.patch_size) x1, x2 = self.dwconv(x).chunk(2, dim=1) x = F.gelu(x1) * x2 x = self.project_out(x) return x
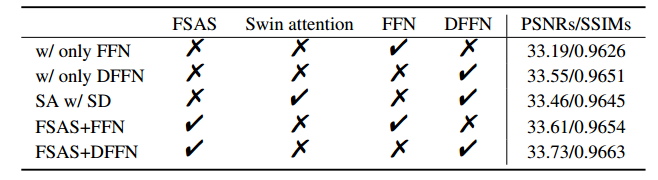
消融实验: