Efficient GPU-Accelerated Subgraph Matching
总结
核心在利用GPU并行计算,为此设计了更适合GPU查询的数据结构,并混合BFS-DFS(先广度过滤再深度匹配)实现更好的时空复杂度
动机
现有的算法都是先过滤再枚举。常规的CPU算法一次只能计算一个点,而现有的最好的GPU算法难以动态维护候选集,有些过滤步骤任然需要在cpu上进行等等,效率上仍然有优化空间。此外,广度优先遍历也导致他们的空间复杂度很高、BFS策略需要大量的内存访问策略,而显存的延迟又会比内存高。为此,文章针对GPU优化实现了更好的子图匹配算法.
基本思路
- 设计新的数据结构(Cuckoo tries)实现更高效的边插入和删除来辅助过滤过程,以及更高效的随机邻居访问辅助实现枚举过程。
- 使用index而不是原图
- 基于新数据结构设计了GPU上的三步并行剪枝
- 混合BFS-DFS,及广度优先分组,深度优先匹配,从而减少内存占用
Cuckoo tries有三层,哈希表、offsets和邻居集。查询时,每个线程都可以在顶层的哈希表中找一个点,再在最后一层找不同的邻居。
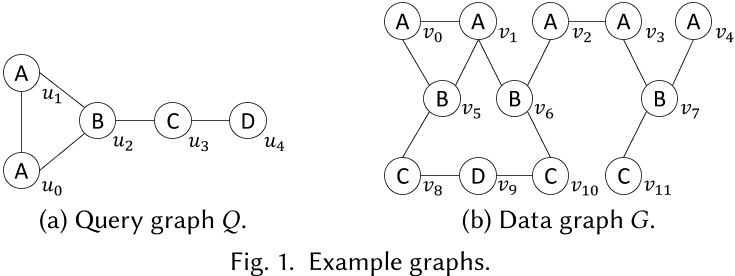
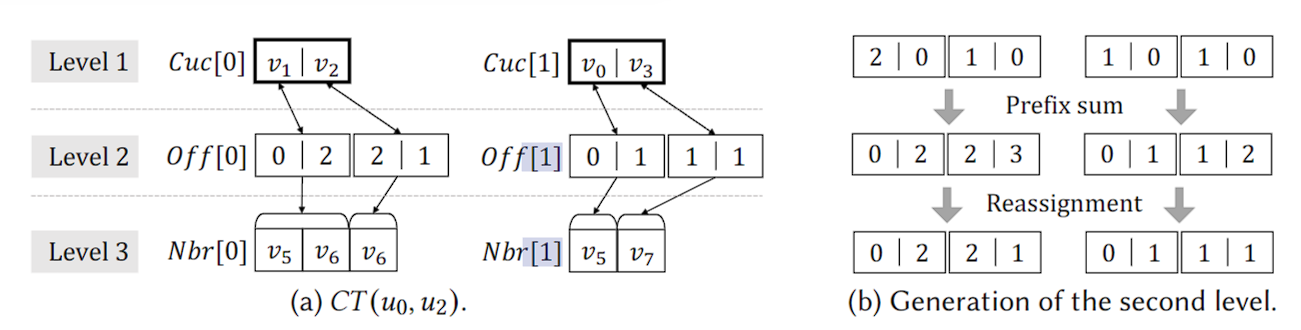
第一层的\(v_1\), \(v_2\)是\(u_0\)的候选点。然后\(v_1\)有三个邻居,把他们根据度进行排序,0号开始的前两个满足,映射得到\(v_5\), \(v_6\),也就是\(u_2\)的候选点。通过这样的结构来进行点的匹配搜索。后面还会将这些结果矩阵化。
问题定义
使用点有标签的图,Q为查询图(小),G为数据图(大)。最终目的是确定两图之间的点匹配情况。
定义wedge,及u'-u-u'',包含两边三点的一个开三角
以前的方法是做点的候选集合C(u)(看后面的伪代码还是用到了点候选),这里设立查询图的边候选合集R(u, u'),并且其中的元组t(v, v')可以找到数据图中的对应:\(e(v, v') \in E(G)\)。
定义R(u, u')中的v的邻居集为N(v, u, u'),也就是只在这个集合内的邻居集合。
\(\phi\)表示匹配顺序,排在u之前的点集为\(N_+(u)\),之后的是\(N_-(u)\)
伪代码
GPU上BFS匹配部分:

- 先生成候选集和排序,再把排序最靠前的放入匹配集M中(排序是如何初始化的?)
- 不断地将排序下一个点进行匹配。具体说是之前那些高排位的点的候选点的邻居以及当前点的候选点集,再提出最小集合。最后判断最小集合的点是否在大的候选集里,是就加入
过滤部分:

其实就是建立Cuckoo Tries的过程。每次取一个点,比较标签和邻居。其中的NLC是邻居标签向量(每有一个邻居有标签n,则在n维+1)。
GPU上的DFS部分:

利用递归实现广度优先。
GPU上两部分合并:

会先用BFS,做一波匹配,再用DFS进行进一步的匹配
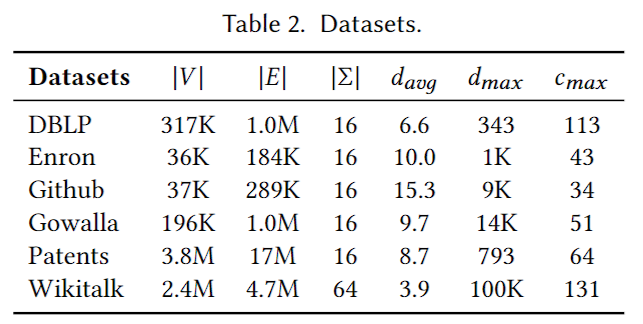
数据集
实验
能够解决的匹配数量

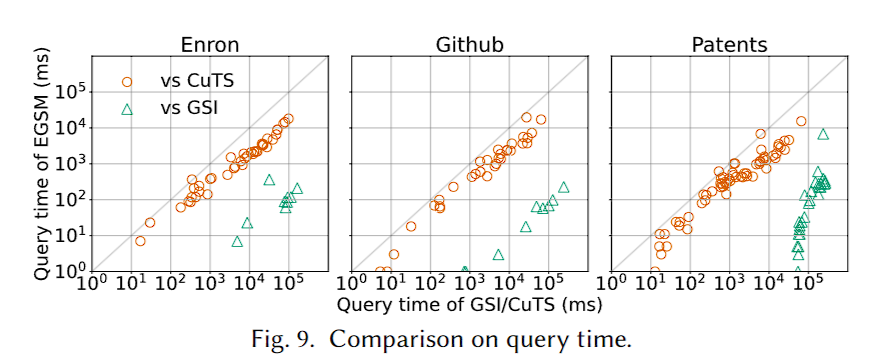
效率
空间占用

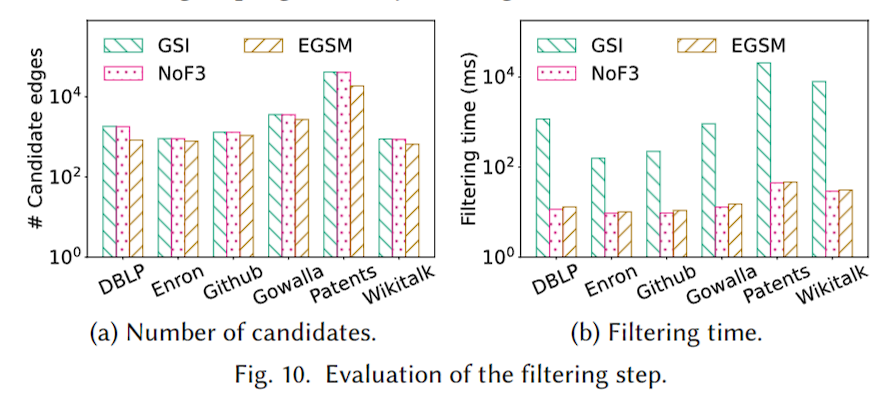
过滤效果
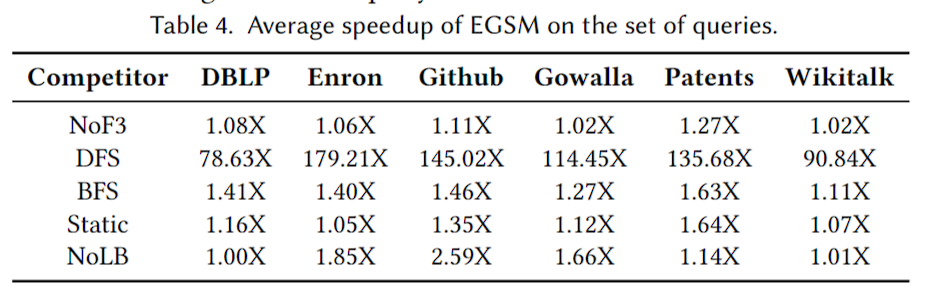
加速效果
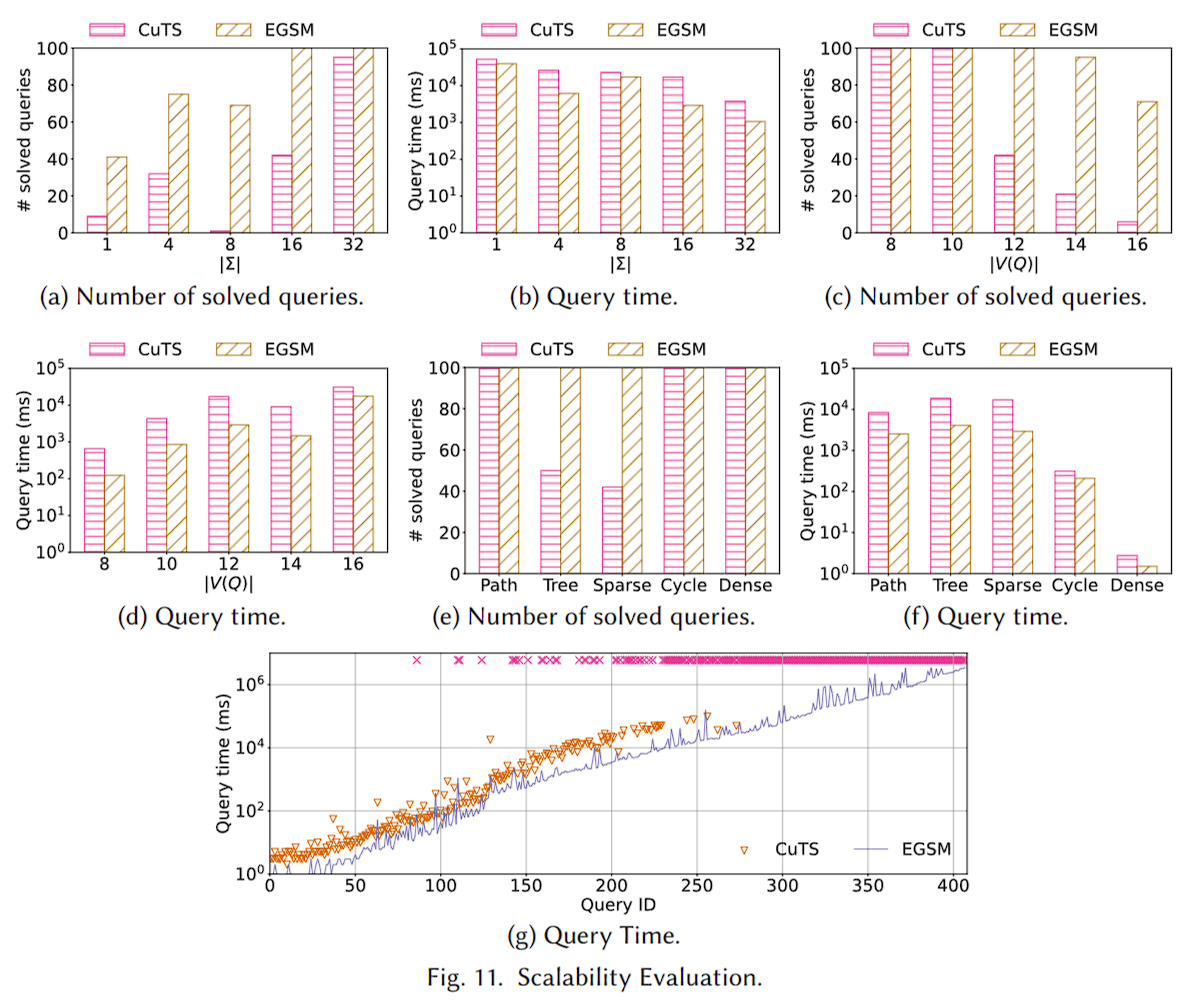
可拓展性
- GPU-Accelerated Accelerated Efficient Subgraph Matchinggpu-accelerated accelerated efficient subgraph efficient subgraph matching billion gpu-accelerated efficiency guaranteed matching subgraph in-memory matching in-depth subgraph matching subgraph neural distributed dataflow subgraph matching accelerated subgraph prediction sketching networks subgraph