6.824 lab1 笔记
1. 阅读论文
略
2. 官网rules & hints
2.1 rules
- map阶段每个worker应该把中间文件分成nReduce份,nReduce是reduce任务的数量
- worker完成reduce任务后生成文件名
mr-out-X mr-out-X文件每行应该是"%v %v"格式,参考main/mrsequential.go- worker处理完map任务,应该把生成的中间文件放到当前目录中,便于worker执行reduce任务时读取中间文件
- 当所有任务完成时,
Done()函数应该返回true,使得coordinator退出 - 所有任务完成时,worker应该退出,方法是:
- 当worker调用rpc向coordinator请求任务时,连接不上coordinator,此时可以认为coordinator已经退出因为所有任务已经完成了
- 当worker调用rpc向coordinator请求任务时,coordinator可以向其回复所有任务已经完成
2.2 hints
-
刚开始可以修改
mr/worker.go's ``Worker()向coordinator 发送一个RPC请求一个任务。然后修改coordinator回复一个文件名,代表空闲的map任务。然后worker根据文件名读取文件,调用wc.so-Map函数,调用Map函数可参考mrsequential.go` -
如果修改了
mr/目录下任何文件,应该重新build MapReduce plugins,go build -buildmode=plugin ../mrapps/wc.go -
worker处理完map任务后产生的中间文件命名格式
mr-X-Y,x是map任务的编号,y是reduce任务编号。// 初始文件,通过命令行传入的,如 // pg-being_ernest.txt pg-dorian_gray.txt pg-frankenstein.txt // len(files) = 3 nReduce = 4 // 中间文件 x:map任务的编号 y:reduce任务编号 // mr-0-0 mr-1-0 mr-2-0 // mr-0-1 mr-1-1 mr-2-1 // mr-0-2 mr-1-2 mr-2-2 // mr-0-3 mr-1-3 mr-2-3 -
map任务存储数据到文件可以使用json格式,便于reduce任务读取
// map enc := json.NewEncoder(file) for _, kv := ... { err := enc.Encode(&kv) // reduce dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) } -
map阶段使用
ihash(key)函数把key映射到哪个reduce任务,如某个worker取得了2号map任务,ihash("apple") = 1,那么就应该把该key放到mr-2-1文件中 -
可以参考
mrsequential.go代码:读取初始输入文件、排序key、存储reduce输出文件 -
coordinator是rpc server,将会被并发访问,需要对共享变量加锁
-
若当前未有空闲的map任务可以分配,worker应该等待一段时间再请求任务,若worker频繁请求任务,coordinator就会频繁加锁、访问数据、释放锁,浪费资源和时间。如使用
time.Sleep(),worker可以每隔一秒发送一次请求任务rpc -
coordinator无法辨别某个worker是否crash,有可能某个worker还在运行,但是运行极其慢(由于硬件损坏等原因),最好的办法是:coordinator监控某个任务,若该任务未在规定时间内由worker报告完成,那么coordinator可以把该任务重新分配给其他worker,该lab规定超时时间是10s
-
为了确保某个worker在写入文件时,不会有其他worker同时写入;又或者是某个worker写入文件时中途退出了,只写了部分数据,不能让这个没写完的文件让其他worker看到。可以使用临时文件
ioutil.TempFile,当写入全部完成时,再使用原子重命名os.Rename。 -
Go RPC只能传struct中大写字母开头的变量
-
调用RPC
call()函数时,reply struct应该为空,不然会报错reply := SomeType{} call(..., &reply)
3. 架构设计
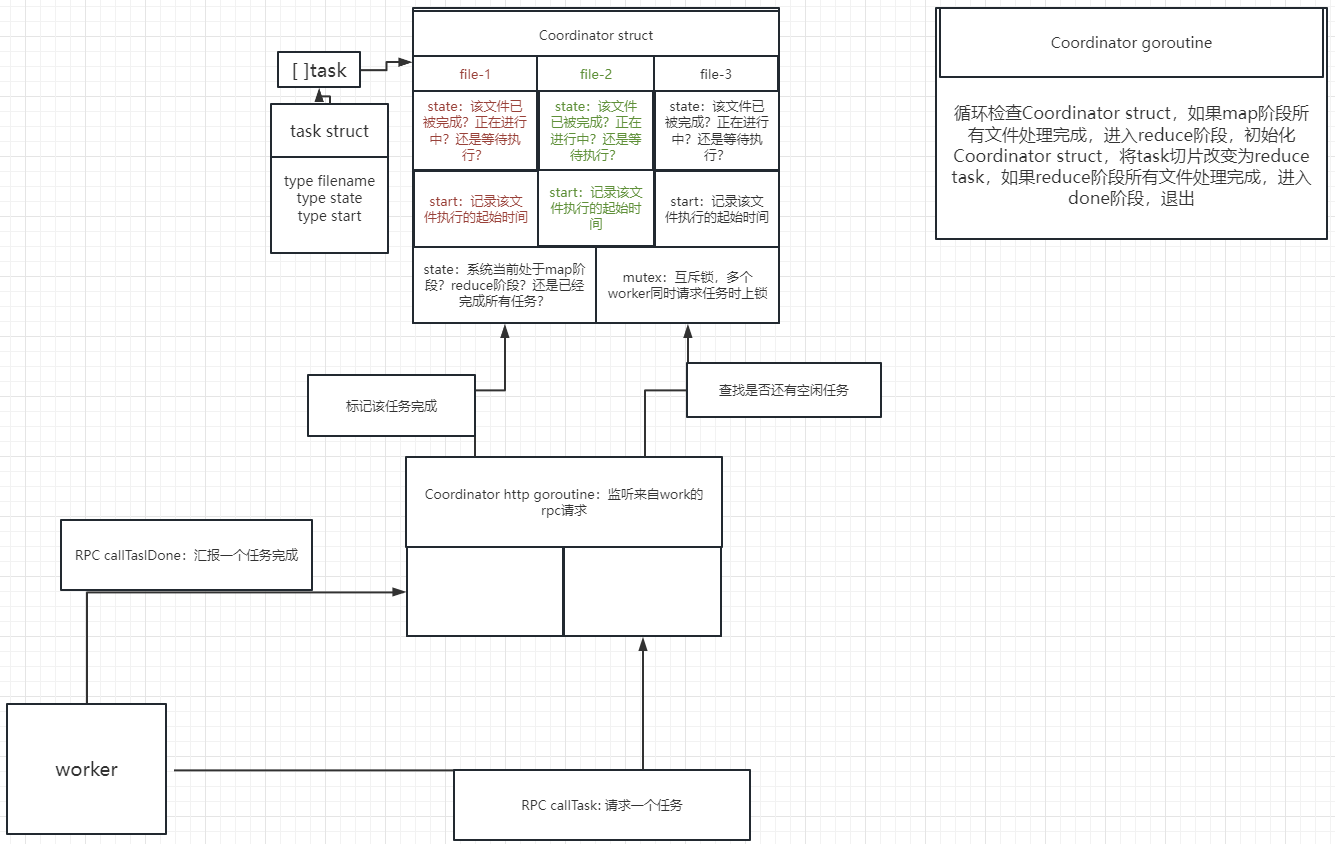
3.1 RPC设计
在该lab中,我们需要两个RPC,一个是callTask RPC向coordinator请求一个任务,一个是callTaskDone RPC向coordinator报告某个任务的完成,以下皆在rpc.go中定义
-
首先定义一个枚举变量,表示coordinator给worker分配的任务类型,也可用来表示coordinator当前的phase
type taskType int const ( // map任务 mapType taskType = iota // reduce任务 reduceType // 当前没有空闲任务,请等待 waitting // 已经完成全部任务,可以退出了 done ) -
定义拉取任务RPC的args和reply struct
CallTaskArgs中不需要包含变量,只需要让coordinator知道该worker正在请求一个任务,coordinator会随机选择空闲任务进行分配填入CallTaskReply中CallTaskReply包含以下变量:FileName:map阶段,worker需要知道具体的文件名才能解析该文件tp:指示该任务的具体类型TaskID:worker将该变量放入CallTaskDoneArgs中,coordinator可以迅速定位Task[TaskID],并且在reduce阶段中,搭配nFiles变量,worker读取mr-0-TaskID、mr-1-TaskID....mr-nFiles-1-TaskID文件nFiles:初始文件的数量,用于搭配TaskID,在上面已介绍nReduce:用于map阶段,ihash(key) % nReduce
type CallTaskArgs struct { } type CallTaskReply struct { FileName string TaskID int tp taskType nFiles int nReduce int } -
定义报告任务完成RPC的args和reply struct
TaskID变量作用在CallTaskReply: TaskID中提及tp的作用是用于coordinator判断该RPC是否是合法的,举例:worker-1成功请求到map-1任务,但是因为worker-1节点硬件问题处理缓慢而导致coordinator检测到该map-1任务超时,于是把map-1任务分配给了worker-2。等到某个时间点,已经完成所有map任务,coordinator进入到了reduce阶段,但此时worker-1节点才刚运行完map-1任务并报告给coordinator,coordinator检测到当前是reduce阶段,但收到报告完成的rpc是map类型,不会对其进行任何操作。type CallTaskDoneArgs struct { TaskID int tp taskType } type CallTaskDoneReply struct { }
3.2 Coordinator
3.2.1 结构体设计
type taskState int
const (
spare taskState = iota
executing
finish
)
type task struct {
fileName string
id int
state taskState
start time.Time
}
首先设计一个task struct,该结构体代表一个任务
filename:在map阶段,用于coordinator告知worker要读取的初始文件id: 该任务的id,传给worker,作用在RPC设计中提及state:任务有三个状态:空闲、执行中、已完成。若空闲则可以分配给worker;若执行中,则监视该任务是否超时start:任务刚开始执行的时间
type Coordinator struct {
// Your definitions here.
mu sync.Mutex
state taskType
tasks []*task
mapChan chan *task
reduceChan chan *task
nReduce int
nFiles int
finished int
}
接着设计主要Coordinator结构体
state:当前系统的状态,map阶段(分配map任务)、reduce阶段(分配reduce任务)、全部完成done(可以结束系统运行)tasks: *task的切片,维护了一组任务mapChan、reduceChan:用于分发map、reduce任务的channel。map阶段,若有空闲map任务,则放至channel中,当有worker请求任务时,则可取出来。reduce阶段同理finished:当前已完成任务的数量。map阶段,若finished == nFiles,则表示所有map任务完成,可以进入reduce阶段。reduce阶段同理,进入done
3.2.2 初始化
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{}
// Your code here.
c.mapPhase(files, nReduce)
go c.watch()
c.server()
return &c
}
func (c *Coordinator) mapPhase(files []string, nReduce int) {
c.state = mapType //设置系统状态为map阶段
c.nReduce = nReduce
c.nFiles = len(files)
c.tasks = make([]*task, c.nFiles)
c.mapChan = make(chan *task, c.nFiles) // c.nFiles长度的map channel
for i := 0; i < c.nFiles; i++ {
c.tasks[i] = &task{fileName: files[i], id: i}
c.mapChan <- c.tasks[i] // 刚开始所有任务都是空闲状态,放入channel中
}
}
系统刚开始时即map阶段,mapPhase初始化Coordinator结构体。然后启动c.watch()协程,用于监视任务是否超时,放后面讲
3.2.3 分配任务
func (c *Coordinator) CallTask(args *CallTaskArgs, reply *CallTaskReply) error {
c.mu.Lock()
defer c.mu.Unlock()
if c.state == done {
reply.Tp = done
} else if c.state == mapType {
switch len(c.mapChan) > 0 {
case true:
task := <-c.mapChan
c.setReply(task, reply)
case false:
reply.Tp = waitting
}
} else {
switch len(c.reduceChan) > 0 {
case true:
task := <-c.reduceChan
c.setReply(task, reply)
case false:
reply.Tp = waitting
}
}
return nil
}
func (c *Coordinator) setReply(t *task, reply *CallTaskReply) {
if t.state == finish {
reply.Tp = waitting
return
}
reply.Tp = c.state
reply.TaskID = t.id
reply.NReduce = c.nReduce
reply.NFiles = c.nFiles
reply.FileName = t.fileName
t.state = executing
t.start = time.Now()
}
分配任务的主要函数,worker处会调用call("Coordinator.CallTask", &args, &reply)。
- 若当前系统状态为done,则返回done,告知worker可以退出了
- 若当前系统状态为map阶段:如果当前有任务可以分配
len(c.mapChan) > 0,则取出一个task,调用c.setReply(task, reply),将任务的相关信息填入reply中,并把task的当前状态设为执行中,开始时间设为time.Now()。如果没有可分配的任务,则设reply.Tp = waitting,让worker等待一会再请求任务 - 若当前系统状态为reduce阶段:同上
3.2.4 任务完成
func (c *Coordinator) CallTaskDone(args *CallTaskDoneArgs, reply *CallTaskDoneReply) error {
c.mu.Lock()
defer c.mu.Unlock()
if c.state != args.Tp || c.state == done {
return nil
}
if c.tasks[args.TaskID].state != finish {
c.tasks[args.TaskID].state = finish
c.finished++
//fmt.Printf("task %v done\n", args.TaskID)
if c.state == mapType && c.finished == c.nFiles {
c.reducePhase()
} else if c.state == reduceType && c.finished == c.nReduce {
close(c.reduceChan)
c.state = done
}
}
return nil
}
func (c *Coordinator) reducePhase() {
//fmt.Printf("reduce phase\n")
close(c.mapChan)
c.state = reduceType
c.tasks = make([]*task, c.nReduce)
c.finished = 0
c.reduceChan = make(chan *task, c.nReduce)
for i := 0; i < c.nReduce; i++ {
c.tasks[i] = &task{id: i}
c.reduceChan <- c.tasks[i]
}
}
worker处会调用call("Coordinator.CallTaskDone", &args, &reply)来报告某任务的完成
首先判断c.state != args.Tp,即报告完成的任务类型和当前系统状态不匹配,可能发生在该情况:work-1请求了map-1任务,但是work-1运行太缓慢导致Coordinator监测到map-1任务超时,于是把map-1任务分配给了work-2。当所有map任务完成时,Coordinator进入了reduce阶段,这时work-1才报告map-1任务完成,与当前系统状态不匹配,故会直接返回
若该任务未完成,则将该任务标记未已完成,c.finished++。
- 如果当前为map阶段并且所有map任务已完成
c.state == mapType && c.finished == c.nFiles,则进入reduce阶段:- 关闭map channel
- 将系统状态设为reduce
- 重置c.tasks为一系列reduce任务
- 创建长度为c.nReduce的reduce channel
- 放入任务
- 如果当前为reduce阶段并且所有map任务已完成
c.state == reduceType && c.finished == c.nReduce,则进入done阶段:- 关闭reduce channel
- 将系统状态设为done
3.2.5 监测超时任务goroutine
func (c *Coordinator) watch() {
for {
time.Sleep(time.Second)
c.mu.Lock()
if c.state == done {
return
}
for _, task := range c.tasks {
if task.state == executing && time.Since(task.start) > timeout {
task.state = spare
switch c.state {
case mapType:
c.mapChan <- task
case reduceType:
c.reduceChan <- task
}
}
}
c.mu.Unlock()
}
}
如果当前系统状态为done了,可以退出协程了
循环任务列表,如果该任务状态是正在执行但是超时了time.Since(task.start) > timeout(time.Since可以计算系统当前时间距离start过去了多少时间),将该任务状态重置为空闲状态,并且根据系统当前状态,把该任务重新放入对应的channel中
3.3 Worker
3.3.1 主流程
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for {
args := CallTaskArgs{}
reply := CallTaskReply{}
ok := call("Coordinator.CallTask", &args, &reply)
//now := time.Now()
if ok {
switch reply.Tp {
case mapType:
executeMap(reply.FileName, reply.NReduce, reply.TaskID, mapf)
case reduceType:
executeReduce(reply.NFiles, reply.TaskID, reducef)
case waitting:
time.Sleep(time.Second * 2)
continue
case done:
os.Exit(0)
}
} else {
time.Sleep(time.Second * 2)
continue
}
//fmt.Printf("finish task: %v %v use %v\n", reply.TaskID, rs(reply.Tp), time.Since(now).Seconds())
a := CallTaskDoneArgs{reply.TaskID, reply.Tp}
r := CallTaskDoneReply{}
call("Coordinator.CallTaskDone", &a, &r)
time.Sleep(time.Second * 2)
}
}
首先向Coordinator发送请求任务rpc:
- map任务:执行
- reduce任务:执行
- waitting:当前Coordinator没有空闲任务,sleep一段时间再请求
- done:所有任务已完成,退出
任务执行完成后,报告任务完成
3.3.2 执行map任务
func executeMap(fileName string, nReduce, taskID int, mapf func(string, string) []KeyValue) {
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("cannot open %v", fileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", fileName)
}
file.Close()
kva := mapf(fileName, string(content))
// 上面的代码参考mrsequential.go
files := []*os.File{}
tmpFileNames := []string{}
encoders := []*json.Encoder{}
for i := 0; i < nReduce; i++ {
tempFile, err := ioutil.TempFile("./", "")
if err != nil {
log.Fatalf("cannot open temp file")
}
files = append(files, tempFile)
tmpFileNames = append(tmpFileNames, tempFile.Name())
encoders = append(encoders, json.NewEncoder(tempFile))
}
for _, kv := range kva {
n := ihash(kv.Key) % nReduce
encoders[n].Encode(kv)
}
for i := 0; i < nReduce; i++ {
files[i].Close()
os.Rename(tmpFileNames[i], "./"+intermediateFileName(taskID, i))
}
}
在当前目录创建nReduce个临时文件ioutil.TempFile("./", ""),使用该临时文件创建json.Encoder(在hints第四条),使用ihash函数把每个key映射到哪个文件,写入json格式,然后对每个临时文件重命名为mr-x-y格式
生成中间文件名函数:
func intermediateFileName(x, y int) string {
return fmt.Sprintf("mr-%v-%v", x, y)
}
3.3.3 执行reduce
func executeReduce(nFiles, taskID int, reducef func(string, []string) string) {
kvs := []KeyValue{}
for i := 0; i < nFiles; i++ {
filename := intermediateFileName(i, taskID)
// 读取每个中间文件
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
// 参考hints第四条,从文件中取出json格式的每条数据
decoder := json.NewDecoder(file)
for {
var kv KeyValue
// 已读到文件末尾
if err := decoder.Decode(&kv); err != nil {
break
}
kvs = append(kvs, kv)
}
file.Close()
}
// 参考mrsequential.go
oname := fmt.Sprintf("mr-out-%v", taskID)
tempFile, _ := ioutil.TempFile("./", "")
tempFileName := tempFile.Name()
sort.Sort(ByKey(kvs))
for i := 0; i < len(kvs); {
j := i + 1
for j < len(kvs) && kvs[j].Key == kvs[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, kvs[k].Value)
}
output := reducef(kvs[i].Key, values)
fmt.Fprintf(tempFile, "%v %v\n", kvs[i].Key, output)
i = j
}
tempFile.Close()
os.Rename(tempFileName, "./"+oname)
}