Abstract
自回归模型有效提高了RD表现,因为它有效减少了潜表示的空间冗余,但其解码时需要按照特定的顺序,而不能并行。本文的棋盘上下文模型,重新组织解码顺序,解码速度快了40倍。
Introduction
减少冗余的三个途径,空间、视觉和统计冗余。JPEG,JPEG2000 and BPG 都是用无损熵编码,内容损失只发生在量化阶段。
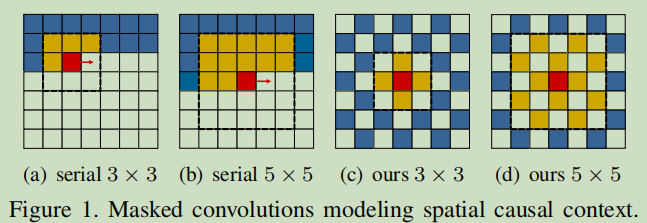
图1为空间因果上下文的掩码卷积模型,红色块代表要编码/解码的部分,Latents in yellowand blue locations are currently visible (all of them are visible during encoding, and those who have been decoded are visible during decoding).上下文模型可使用掩码卷积来进行上下文建模,以红色块为中心,与黄色块做卷积。
图(a)(b)是常用的串行上下文模型。(c)(d)是棋盘模型,当黄色与蓝色位置解码后,其他位置都可以并行解码。
Preliminary 初步介绍
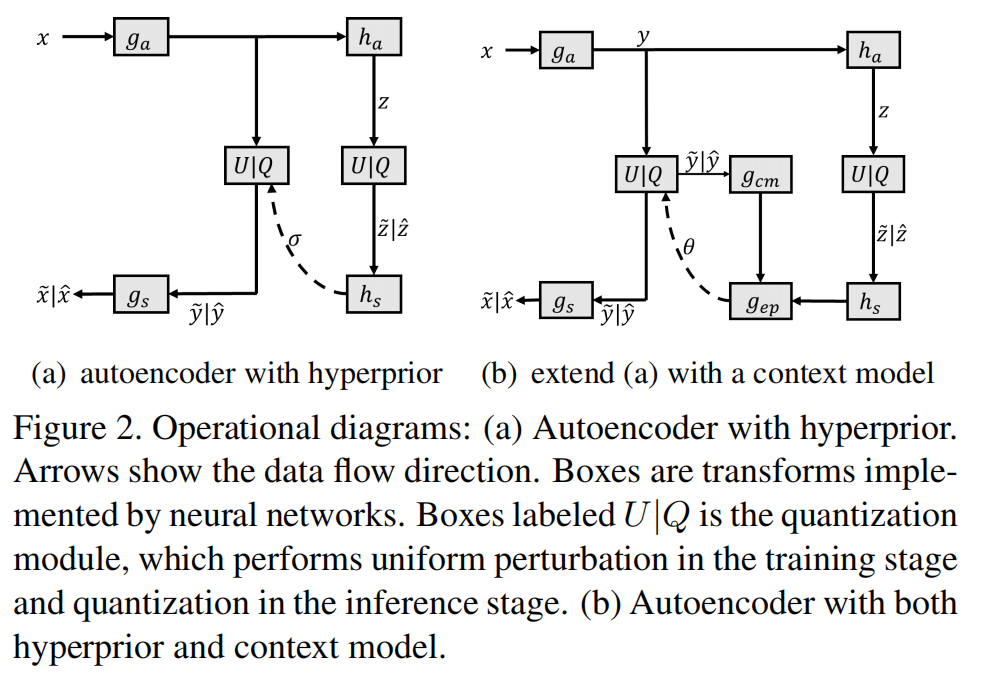
尺度超先验框架如图2所示,
\(\quad\) \(g_s\),\(h_a\),\(h_s\)是神经网络实现的nonlinear transforms
\(\quad\) \(x\)是原始图像
\(\quad\) \(y=g_a(x)\)和\(\hat{y}=Q(y)\),分别是量化前后的 latent representations
\(\quad\) \(\hat{x}=g_s(\hat{y})\)是重构图像。
\(\quad\) \(z=h_a(y)\)和\(\hat{z}=Q(z)\),分别是量化前后的hyper latent
\(\quad\) \(\hat{z}\)被用作边信息,为latent \(\hat{y}\)的熵模型估计尺度参数\(\sigma\)
在训练时,通过加均匀噪声来近似量化操作,得到可微的\(\tilde{y},\tilde{z},\tilde{x}\)
The tradeoff between rate and distortion(loss function):
其中,\(\hat{y}\) 和 hyper latent \(\hat{z}\)通过估计熵来预测, \(\lambda\) controls the bit rate,\(\lambda\)越大,图像重构质量越好。D通常用评价指标MSE或者MS-SSIM.E是指数分布
使用超先验尺度scale hyperprior,latents, \(\hat{y}\)的概率可以通过条件高斯尺度混合模型(GSM)来进行建模:
其中,位置参数\(\mu_i\)假设为0,尺度参数\(\sigma_i\)是\(\sigma=h_s(\hat{z})\)第i个元素,因为\(\hat{y}\)中每个代码给定了超先验。hyper latent \(\hat{z}\)的概率可以用为参数全因分解密度模型建模。
Variational Image Compression with Hyperprior(超先验变分图像压缩)
Autoregressive Context(自回归上下文模型)
Parallel Context Modeling 并行上下文模型
Random-Mask Model: Test Arbitrary Masks(随机掩码模型)
How Distance Influences Rate Saving
Parallel Decoding with Checkerboard Context(棋盘模型并行解码)
- Checkerboard Compression Efficient Context Learnedcheckerboard compression efficient context autoregressive hierarchical compression learned space-channel compression contextual efficient checkerboard learned learned_inertial_model_odometry learned_inertial_model_odometry inertial odometry augmenting decompiler variable learned alexandr learned what 2023 compression