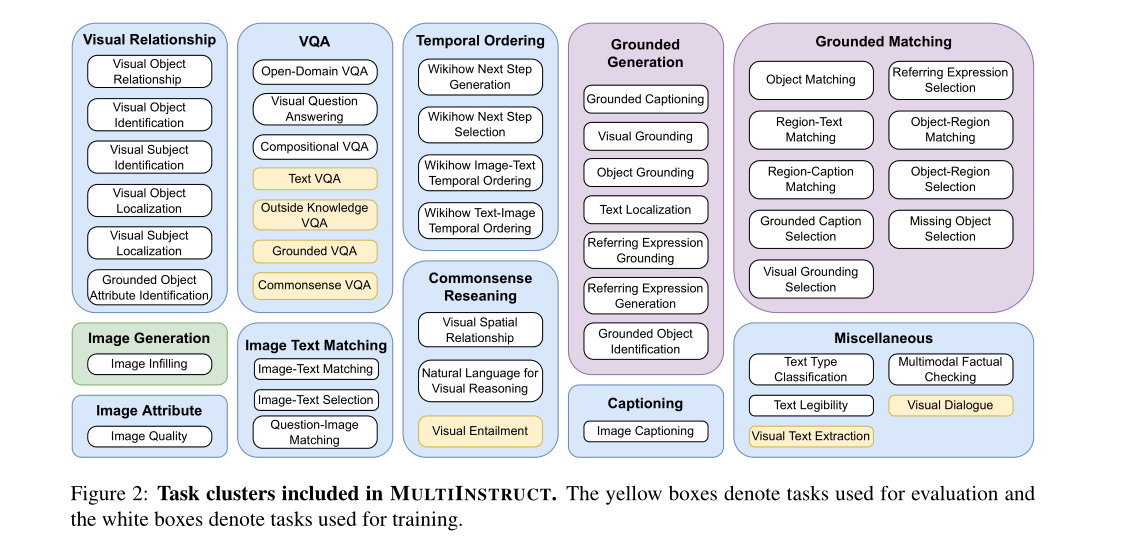
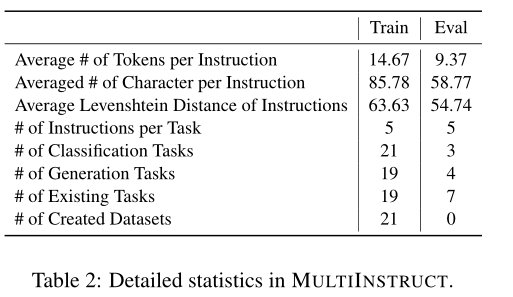
指令调优是一种新的学习范式,它可以根据指令指定的任务对预先训练好的语言模型进行微调,在各种自然语言处理任务中显示出良好的零目标性能。然而,对于视觉和多模态任务,它仍然没有被探索。在这项工作中,我们介绍了multiinstruction,这是第一个多模态指令调优基准数据集,由47个不同的多模态任务组成,涵盖11个大类。每个任务都设计了至少5000个来自现有开源数据集的实例(输入-输出对)和5个专家编写的指令。我们将OFA (Wang et al, 2022a)作为多模态指令调优的基础预训练模型,为了提高其性能,我们探索了多种迁移学习策略来利用大规模NATURAL INSTRUCTIONS数据集(Mishra et al, 2022)。实验结果表明,该算法在各种看不见的多模态任务上具有较强的零镜头性能,并且具有纯文本指令迁移学习的优势。我们还设计了一个新的评价指标-灵敏度,以评估模型对指令种类的敏感性。我们的结果表明,在对不同的任务集和每个任务的指令进行微调后,模型对不同的指令不那么敏感。
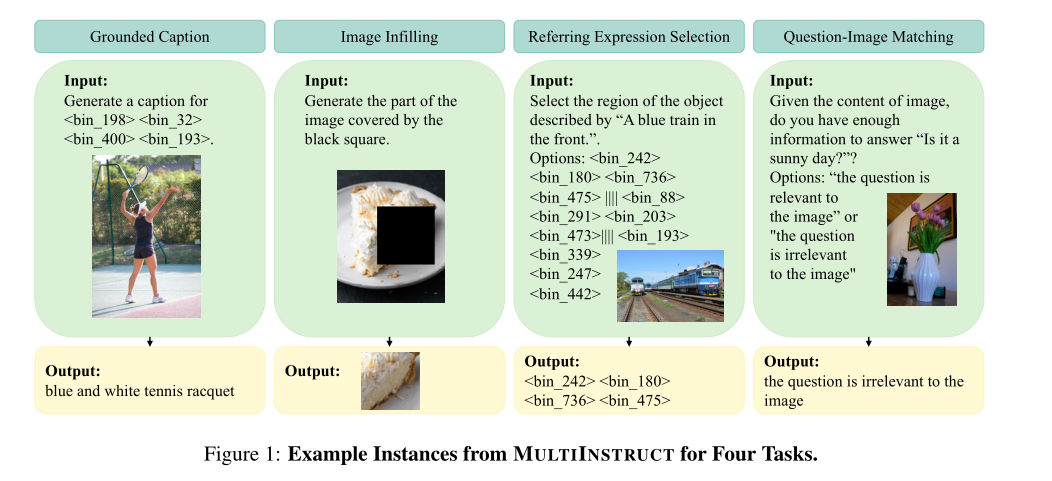
在这项工作中,我们提出了multiinstruction,这是用于多模态指令调优的第一个基准数据集,具有来自11个大类的47个不同任务。multiinstruction涵盖了大多数需要视觉理解和多模态推理的多模态任务,例如视觉问题回答(Goyal等人,2017;Zhu等,2016;Suhr等人,2017),图像字幕(Lin等人,2014),图像生成(Changpinyo等人,2021),视觉关系理解(Krishna等人,2017)等。对于每个任务,我们创建至少5000个实例(即输入-输出对)和5条指令,这些指令由两位自然语言处理专家手动编写。如图1所示,我们将所有任务制定为统一的序列到序列格式,其中输入文本、图像、指令和边界框表示在相同的标记空间中。
我们使用OFA (Wang et al, 2022a),这是一个统一的模型,在一个基于transformer的序列到序列框架中,在不同的交叉模型和单模态任务集上进行预训练,作为基础预训练的多模态语言模型,并在multiinstruction上对其进行微调。考虑到NATURAL INSTRUCTIONS (Mishra et al, 2022)(一个纯文本指令调优数据集)的规模比multiinstruction大得多,我们进一步探索了几种迁移学习策略,包括混合指令调优、顺序指令调优和基于适配器的顺序指令调优。
由于指令调优高度依赖于对各种任务的指令解释,我们还开发了一个新的度量标准-灵敏度,来衡量模型对同一任务的各种指令的敏感性。实验结果表明:(1)指令调优显著降低了OFA对指令措辞变化的敏感性;(2)采用多样化的指令集和任务进行指令调优也有利于降低灵敏度。
自然指令(Mishra等人,2022;Wang等人,2022d)是一个元数据集,包含61个不同的任务,这些任务有人类编写的定义、要避免的事情和演示。研究人员(Mishra等人,2022;Wang等人,2022d)已经表明,即使在语言模型的大小相对较小(例如BART_base)时,NATURAL INSTRUCTIONS也可以极大地提高语言模型的泛化性。Webson和Pavlick(2022)调查了语言模型是否以人类的方式理解任务指令,并表明在不相关和具有误导性的指令下,模型在少镜头学习设置下仍然可以实现与良好指令相似的性能。InstructDial (Gupta et al, 2022)将指令调优应用于对话域,并在未见的对话任务上显示出显著的零镜头性能。虽然这些研究在纯文本领域取得了成功,但还没有广泛地探索视觉或多模态任务。

第一种方式是要求模型从给定区域的多个候选标题中选择相应的标题(给定区域选择caption),第二种是模型根据给定的标题从提供的候选区域中选择相应的区域(给定caption选择区域)


我们遵循与以往研究相同的指令调优设置(Wei et al, 2021),主要评估经过微调的大型语言模型的零镜头学习能力。具体来说,给定一个预先训练好的多模态语言模型M,我们的目标是在指令任务T的集合上对其进行微调。每个任务t∈t与若干个训练实例Dt = {(It, xtj, ytj)∈It × X t × Yt}Nj=1,其中xtj表示输入的文本、图像、区域和提供的选项,ytj表示每个实例的输出,它表示专家编写的5个任务指令的集合。来自xtj的输入信息将用于填充指令中的占位符。我们确保multiinstruction中的评估任务不与OFA中的训练前任务或multiinstruction中的训练任务重叠。
从自然指令迁移学习
我们注意到NATURAL INSTRUCTIONS (Mishra et al, 2022;Wang et al, 2022d)明显大于multiinstruction,这表明将指令学习能力从更大的自然语言任务集(即自然指令(Mishra et al, 2022)中定义的894个英语任务)转移到多模态任务的潜力。在这里,我们将探讨几种简单的策略:
Mixed Instruction Tuning:
混合指令调优:我们结合了自然指令和多指令的实例,并随机洗牌它们,然后用指令对OFA进行微调。注意,NATURAL INSTRUCTIONS中的每个任务只与一条指令相关联,而multiinstruction中的每个实例,我们总是从每个训练实例的五条指令中随机抽取一条指令。
Sequential Instruction Tuning
我们提出了一种两阶段顺序指令调优策略,首先对NATURAL INSTRUCTIONS数据集上的OFA进行微调,以鼓励模型遵循指令执行仅语言任务,然后在multiinstruction上进一步微调,以使指令学习能力适应多模态任务。为了最好地利用NATURAL INSTRUCTIONS数据集,我们在第一个训练阶段使用英语任务中的所有实例来调整模型。
Adapter-based Sequential Instruction Tuning
随着模型和训练任务/实例的增长,调优整个大型预训练语言模型的计算成本很高,而且不切实际。考虑到这一点,我们通过引入适配器进一步提出了一种参数高效的指令调优策略(Houlsby等人,2019)。具体地说,我们在OFA的解码器和编码器的每个变压器层的前馈层之后插入一个适配器。适配器基于附录中的表10列出了OFA预训练中使用的多模态任务和数据集。多层感知器结构,由前馈层、非线性激活层和前馈层组成。为了减少训练参数的数量,我们将输入特征大小缩小了四倍,即OFA中1024个特征维度的256。在训练过程中,我们冻结OFA的参数,并在NATURAL INSTRUCTIONS和multiinstruction上依次优化适配器的参数。在推理过程中,我们直接应用基于适配器的OFA对各种看不见的任务进行零镜头预测。
灵敏度
指的是模型在预期任务不变的情况下,无论指令措辞是否有细微变化,都能始终产生相同结果的能力。具体而言,对于每一个任务t∈t,给定其关联实例Dt = {(xtj, ytj)∈X t × Yt}Nj=1和任务指令It,我们将任务内灵敏度定义为:
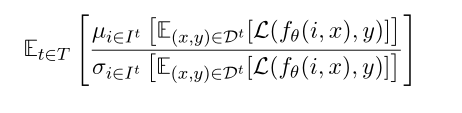
- MULTIINSTRUCT Instruction Multi-Modal Improving Zero-Shotmultiinstruct instruction multi-modal improving multiinstruct multi-modal recommendation personalized convolution multi-modal multi-modal attention retrieval learning zero-shot improving understanding pre-training generative improving translation augmentation robustness improving convolutions improving computer accuracy