InstructPix2Pix和Pix2Pix是两码事。Pix2Pix使用的是GAN,而InstructPix2Pix使用的是Diffusion。这个名字的由来可能出于两个方面,一方面InstructPix2Pix允许在image-translation的时候引入文本Instruction,另一方面InstructPix2Pix和Pix2Pix一样使用了成对的数据进行训练。鉴于目前图像生成与预训练大模型的飞速发展,即便是CycleGAN里所谓的“不可获取的”成对的数据,也可以通过预训练模型生成出来,作为数据集进行训练。InstructPix2Pix在这方面做了研究,并取得了非常不错的效果。

Resources and papers
InstructPix2Pix: Learning to Follow Image Editing Instructions
Read-through
Abstract
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models—a language model (GPT-3) and a text-to-image model (Stable Diffusion)—to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per-example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.
论文提出了一种利用文本引导图像编辑的方法,使用条件扩散模型,生成速度很快,不需要完全按照格式给出编辑需求的文本,且不需要针对某个数据集做微调。论文使用GPT-3和Stable Diffusion构建成对的训练集(和pix2pix类似),具体来说,通过GPT-3构建一对文本,一个是数据集本身的label(Input Caption),另一个是微调后的GPT-3生成的(Edited Caption)。通过Stable Diffusion以及Prompt2prompt生成成对的图像,由此构造出一组训练数据。
Introduction
We propose an approach for generating a paired dataset that combines multiple large models pretrained on different modalities: a large language model (GPT-3) and a text-to-image model (Stable Diffusion). These two models capture complementary knowledge about language and images that can be combined to create paired training data for a task spanning both modalities.
训练部分:训练数据全部来自于模型生成(人工构造了一部分数据用于微调GPT-3)。
Using our generated paired data, we train a conditional diffusion model that, given an input image and a text instruction for how to edit it, generates the edited image. Our model directly performs the image edit in the forward pass, and does not require any additional example images, full descriptions of the input/output images, or per-example finetuning. Despite being trained entirely on synthetic examples (i.e., both generated written instructions and generated imagery), our model achieves zero-shot generalization to both arbitrary real images and natural human-written instructions.
推理部分:虽然模型训练的时候用的都是生成的数据,但对于真实图像和文本具有zero-shot的能力(个人理解,这应该是Diffusion模型的特点)。
Prior work
Recent work has shown that large pretrained models can be combined to solve multimodal tasks that no one model can perform alone.
Our method is similar to prior work in that it leverages the complementary abilities of two pretrained models—GPT-3 and Stable Diffusion—but differs in that we use these models to generate paired multi-modal training data.
Deep models typically require large amounts of training data. **Internet data collections are often suitable, but may not exist in the form necessary for supervision, e.g., paired data of particular modalities. **As generative models continue to improve, there is growing interest in their use as a source of cheap and plentiful training data for downstream tasks.
先前的工作已经表明预训练大模型可以被用于解决多模态的任务(比如CLIP被大量用于CV领域各方向的任务,利用其对语义信息的理解提高模型表现,以及使模型具备zero-shot的能力)。这篇论文的一个亮点在于将预训练模型用于生成训练数据上,而没有用与训练。这仿佛是CycleGAN中讲到的“For many tasks, paired training data will not be available.”的一种解决方案。
Recent models have leveraged CLIP embeddings to guide image editing using text.
While some text-to-image models natively have the ability to edit images, using these models for targeted editing is non-trivial, because in most cases they offer no guarantees that similar text prompts will yield similar images.
Our model takes only a single image and an instruction for how to edit that image (i.e., not a full description of any image), and performs the edit directly in the forward pass without need for a user-drawn mask, additional images, or per-example inversion or finetuning.
A key benefit of following editing instructions is that the user can just tell the model exactly what to do in natural written text. There is no need for the user to provide extra information, such as example images or descriptions of visual content that remains constant between the input and output images.
有些文生图的模型本身就具备图像编辑的功能,但是用它们完成图像编辑的工作并不容易,因为大多数情况下这些模型无法确保类似的文字提示可以生成出类似的图像来。
之前也有一些关于文字引导图像编辑的工作,比如Text2Live,SDEdit(好几篇论文都拿SDEdit作为baselline去比较,但SDEdit本身并没有文字引导的功能,应该是指用SDEdit提出的方法,即选一个合适的 \(t_0\in (0,\,1)\) 构建的模型吧)。但论文的工作与它们不一样的地方在于,在这里用户只要用自然的语言告诉模型要做什么就行了,不需要按照固定的prompt格式,或者告诉模型什么地方应该保持不变。
Method

Generating a Multi-modal Training Dataset
Our model is trained by finetuning GPT-3 on a relatively small human-written dataset of editing triplets: (1) input captions, (2) edit instructions, (3) output captions. To produce the fine-tuning dataset, we sampled 700 input captions from the LAION-Aesthetics V2 6.5+ dataset and manually wrote instructions and output captions.
首先微调GPT-3生成成对的说明文字(paired caption)。
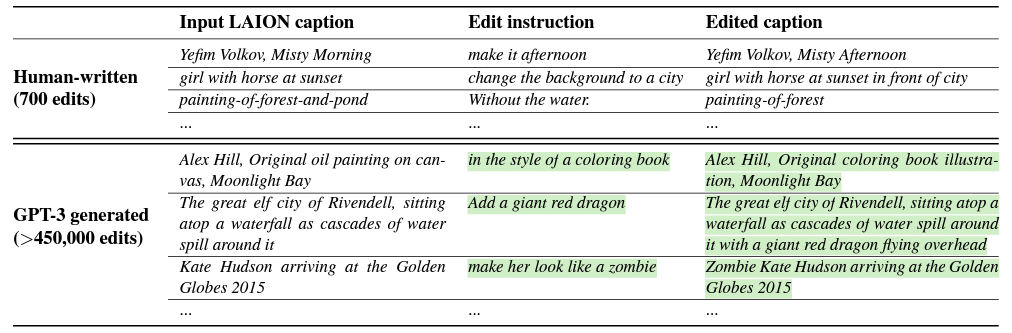
We label a small text dataset, finetune GPT-3, and use that finetuned model to generate a large dataset of text triplets. As the input caption for both the labeled and generated examples, we use real image captions from LAION. Highlighted text is generated by GPT-3.
微调的时候,只用了700组数据,包括LAION数据集自带的label(input captions),人工编写的编辑指令(edit instructions)以及人工编写的最终输出(output captions)。微调后的GPT-3只需要读入LAION数据集的label,即可成对地生成edit instruction和output caption。
A potential drawback of LAION is that it is quite noisy and contains a number of nonsensical or undescriptive captions—however, we found that dataset noise is mitigated through a combination of dataset filtering and classifier-free guidance.
论文也提到LAION数据集非常嘈杂,其中包含许多毫无意义或不相关的描述文本。然而,论文中也发现,通过数据集过滤和无分类器引导的组合方法,可以减轻数据集的噪声问题。"数据集过滤"是指使用一系列规则和启发式方法来删除不相关的图像文本对,而"无分类器引导"则是指Classifier-free diffusion guidance。
Next, we use a pretrained text-to-image model to transform a pair of captions (referring to the image before and after the edit) into a pair of images.
One challenge in turning a pair of captions into a pair of corresponding images is that text-to-image models provide no guarantees about image consistency, even under very minor changes of the conditioning prompt.
We therefore use Prompt-to-Prompt, a recent method aimed at encouraging multiple generations from a text-to-image diffusion model to be similar. This is done through borrowed cross attention weights in some number of denoising steps.
接下来利用Stable Diffusion以及Prompt2prompt技术把成对的文本变成成对的图像。
构造训练数据的时候,成对的文本指的应该是label(input caption)和最终输出(output captions)。
论文提到Diffusion模型本身无法保证生成图像的一致性,哪怕是非常相似的两个Prompt都可能生成完全不同的图像。因此论文在生成成对图像的时候使用了Prompt-to-Prompt技术,其在某些去噪的步骤中引入了交叉注意力机制,这可以使得多次迭代生成的图像更加相似。

Pair of images generated using Stable-Diffusion with and without Prompt-to-Prompt. For both, the corresponding captions are “photograph of a girl riding a horse” and “photograph of a girl riding a dragon”.
Fortunately, Prompt-to-Prompt has as a parameter that can control the similarity between the two images: the fraction of denoising steps \(p\) with shared attention weights. Unfortunately, identifying an optimal value of \(p\) from only the captions and edit text is difficult. We therefore generate \(100\) sample pairs of images per caption-pair, each with a random \(p\sim U(0.1,\,0.9)\), and filter these samples by using a CLIP-based metric: the directional similarity in CLIP space as introduced by Gal et al. . This metric measures the consistency of the change between the two images (in CLIP space) with the change between the two image captions. Performing this filtering not only helps maximize the diversity and quality of our image pairs, but also makes our data generation more robust to failures of Prompt-to-Prompt and Stable Diffusion.
幸运的是,Prompt-to-Prompt具有一个参数 \(p\) 可以控制两个图像之间的相似性。不幸的是,仅通过标题和编辑文本来确定 \(p\) 的最佳值是困难的。
因此,论文对每个标题对生成 \(100\) 组样本图像对,每个图像对使用随机的 \(p\sim U(0.1,\,0.9)\),并通过CLIP计算相似度来过滤这些样本。通过执行此过滤操作,不仅可以最大程度地增加图像对的多样性和质量,而且还可以使我们的数据生成更加健壮,以应对Prompt-to-Prompt和Stable Diffusion的失效。
InstructPix2Pix
We use our generated training data to train a conditional diffusion model that edits images from written instructions.
We learn a network \(\theta\) that predicts the noise added to the noisy latent \(z_t\) given image conditioning \(c_I\) and text instruction conditioning \(c_T\) . We minimize the following latent diffusion objective:
\[\begin{equation}L = \mathbb{E}_{\mathcal{E}(x), \mathcal{E}(c_I), c_T, \epsilon \sim \mathcal{N}(0, 1), t }\Big[ \Vert \epsilon - \epsilon_\theta(z_{t}, t, \mathcal{E}(c_I), c_T)) \Vert_{2}^{2}\Big]\end{equation} \]To support image conditioning, we add additional input channels to the first convolutional layer, concatenating \(z_t\) and \(\mathcal{E}(c_I)\).
\(c_I\) 和 \(c_T\) 分别是图像和文本条件。目标函数即条件扩散模型的目标函数。为了支持图像条件,论文提到他们在第一个卷积层中添加了额外的输入通道,将 \(z_t\) 和 \(\mathcal{E}(c_I)\) 连接在一起。
At inference time, with a guidance scale \(s\ge1\), the modified score estimate \(\tilde{e_{\theta}}(z_t, c)\) is extrapolated in the direction toward the conditional \(e_{\theta}(z_t, c)\) and away from the unconditional \(e_{\theta}(z_t, \varnothing)\).
\[\begin{equation}\tilde{e_{\theta}}(z_t, c) = e_{\theta}(z_t, \varnothing) + s \cdot (e_{\theta}(z_t, c) - e_{\theta}(z_t, \varnothing))\end{equation} \]For our task, the score network \(e_{\theta}(z_t, c_I, c_T)\) has two conditionings: the input image \(c_I\) and text instruction \(c_T\). We find if beneficial to leverage classifier-free guidance with respect to both conditionings.
During training, we randomly set only \(c_I=\varnothing_I\) for \(5\%\) of examples, only \(c_T=\varnothing_T\) for 5% of examples, and both \(c_I=\varnothing_I\) and \(c_T=\varnothing_T\) for \(5\%\) of examples. Our model is therefore capable of conditional or unconditional denoising with respect to both or either conditional inputs. We introduce two guidance scales, \(s_I\) and \(s_T\), which can be adjusted to trade off how strongly the generated samples correspond with the input image and how strongly they correspond with the edit instruction.
Our modified score estimate is as follows:\[\begin{equation} \begin{split} \tilde{e_{\theta}}(z_t, c_I, c_T) = &\: e_{\theta}(z_t, \varnothing, \varnothing) \\ &+ s_I \cdot (e_{\theta}(z_t, c_I, \varnothing) - e_{\theta}(z_t, \varnothing, \varnothing)) \\ &+ s_T \cdot (e_{\theta}(z_t, c_I, c_T) - e_{\theta}(z_t, c_I, \varnothing)) \end{split} \end{equation}\]
论文指出他们在训练期间对随机选取的 \(5\%\) 的示例设置 \(c_I=\varnothing_I\),\(5\%\) 的示例设置 \(c_T=\varnothing_T\),以及 \(5\%\) 的示例设置 \(c_I=\varnothing_I,\,c_T=\varnothing_T\)。因此,InstructPix2Pix的模型能够针对单个或两个条件输入进行有条件或无条件去噪。模型中引入了两个超参 \(s_I\) 和 \(s_T\),可以调整如何平衡生成的样本与输入图像和编辑指令相对应的强度。
生成的分数估计值 \(\tilde{e_{\theta}}(z_t, c_I, c_T)\) 由三部分组成:第一部分是基础分数估计值 \(e_{\theta}(z_t, \varnothing, \varnothing)\),它不考虑任何条件输入;第二部分是基于输入图像的分数估计值 \(e_{\theta}(z_t, c_I, \varnothing)\) 与基础分数估计值之间的差异,乘以一个指导系数 \(s_I\),用来调整生成样本与输入图像之间的相似度;第三部分是基于输入文本指令的分数估计值 \(e_{\theta}(z_t, c_I, c_T)\) 与基于输入图像的分数估计值之间的差异,乘以一个指导系数 \(s_T\),用来调整生成样本与文本指令之间的相似度。这样,生成的分数估计值就会同时考虑输入图像和文本指令两个条件,而且可以通过指导系数来调整相似度的权重。
Classifier-free guidance weights over two conditional inputs. \(s_I\) controls similarity with the input image, while \(s_T\) controls consistency with the edit instruction.
Result
We notice that while SDEdit works reasonably well for cases where content remains approximately constant and style is changed, it struggles to preserve identity and isolate individual objects, especially when larger changes are desired. Additionally, it requires a full output description of the desired image, rather than an editing instruction.
On the other hand, while Text2Live is able to produce convincing results for edits involving additive layers, its formulation limits the categories of edits that it can handle.
虽然SDEdit在内容大致不变而风格改变的情况下效果还不错,但在保留个体和单独分离个体对象方面存在困难,特别是在需要进行较大改变时这种问题比较明显。这应该是因为SDEdit通过选择合适的 \(t_0\in(0,\,1)\) 开始推理,用这种方式权衡图像的真实性和忠于编辑指令的能力。这种方式对图像的影响是全图的。此外,它需要一个关于所需图像的完整输出描述,而不是一个编辑指令。
另一方面,虽然Text2Live能够产生真实度比较高的编辑结果,但它的算法限制了它能够处理的编辑类型。具体来说,Text2Live是基于生成颜色和透明度层的方式进行图像编辑,因此它在编辑涉及添加层的情况下表现良好。但是这也限制了它在处理其他类型的编辑(例如需要删除或修改原始图像中的特定对象等)的能力。

We plot the tradeoff between two metrics, cosine similarity of CLIP image embeddings (how much the edited image agrees with the input image) and the directional CLIP similarity.
We find that when comparing our method with SDEdit, our results have notably higher image consistency (CLIP image similarity) for the same directional similarity values.

横轴CLIP Text-Image Direction Similarity表征图像与文本的相似度,纵轴CLIP Image Similarity表征图像和输入的原图的相似度。在取得同样的文本相似度的条件下,InstructPix2Pix更加忠于原图。
We find that decreasing the size of the dataset typically results in decreased ability to perform larger (i.e., more significant) image edits, instead only performing subtle or stylistic image adjustments (and thus, maintaining a high image similarity score, but a low directional score). Removing the CLIP filtering from our dataset generation has a different effect: the overall image consistency with the input image is reduced.
We also provide an analysis of the effect of our two classifier-free guidance scales. Increasing \(s_T\) results in a stronger edit applied to the image (i.e., the output agrees more with the instruction), and increasing \(s_I\) can help preserve the spatial structure of the input image (i.e., the output agrees more with the input image).
论文做了一系列消融实验。减小数据集的大小通常会导致较小的图像编辑能力下降,而只能进行细微或风格上的图像调整(同纵轴下,横轴值较低,不太忠于文本要求);删除CLIP过滤会使得生成图片与输入图像的整体一致性降低;增加 \(s_T\) 会对图像做更强的编辑,使得其更符合文本指示;增加 \(s_I\) 对保留输入图像的空间结构有利,会生成更加忠于原图的图像。论文给出的合适范围是 \(s_T\in (5,\,10),\,s_I\in (1,\,1.5)\)。


Discussion
Our model struggles with counting numbers of objects and with spatial reasoning (e.g., “move it to the left of the image”, “swap their positions”, or “put two cups on the table and one on the chair”), just as in Stable Diffusion and Prompt-to-Prompt.
InstructPix2Pix在计数和空间推理相关的问题上表现不是很好,这大概是Diffusion模型都有的通病了。

There are well-documented biases in the data and the pretrained models that our method is based upon, and therefore the edited images from our method may inherit these biases or introduce other biases.
InstructPix2Pix训练中使用了GPT-3和Stable Diffusion,因此也继承了这些预训练大模型的偏见,例如将职业和性别挂钩等。

Aside from mitigating the above limitations, our work also opens up questions, such as: how to follow instructions for spatial reasoning, how to combine instructions with other conditioning modalities like user interaction, and how to evaluate instruction-based image editing. Incorporating human feedback to improve the model is another important area of future work, and strategies like human-in-the-loop reinforcement learning could be applied to improve alignment between our model and human intentions.
论文最后也抛出了一系列可能的改进点:“如何根据空间推理遵循指令,如何将指令与其他调节方式(如用户交互)结合起来,以及如何评估基于指令的图像编辑”。将人类反馈纳入模型(RLHF)以改进其性能是未来工作的另一个重要领域。