Anomaly detection via reverse distillation from one-class embedding
Introduction
在知识蒸馏(KD)中,知识是在教师-学生(T-S)对中传递的。在无监督异常检测的背景下,由于学生在训练过程中只接触到正常样本,所以当查询是异常的时候,学生很可能会产生与教师不一致的表示。
然而,在实际情况下,这个假设并不总是成立,原因包括
- 教师和学生网络的相同或相似的架构(non-distinguishing filters )
- 在知识传递/蒸馏过程中T-S模型中的数据流相同。
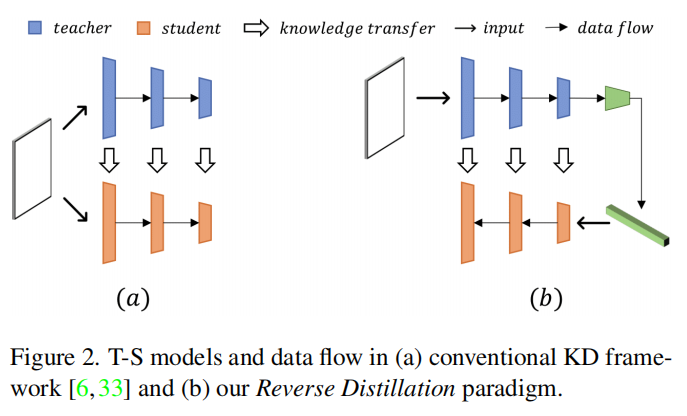
反向蒸馏如图2所示。
从回归的角度来看,我们的反向蒸馏使用学生网络来预测教师模型的表示。因此,“反向”在这里既指的是教师编码器和学生解码器的反向形状,也指的是不同的知识蒸馏顺序,其中首先蒸馏高级别表示,然后是低级别特征。
值得注意的是,我们的反向蒸馏具有两个显著的优点:
- 非相似结构。在所提出的T-S模型中,可以将教师编码器视为降采样滤波器,将学生解码器视为上采样滤波器。这种“反向结构”避免了我们上面讨论的non-distinguishing filters引起的混淆。
- 紧凑嵌入。馈送给学生解码器的低维嵌入充当了正常模式恢复的信息瓶颈。
我们将异常特征形式化为对正常模式的扰动。然后,紧凑的嵌入有助于阻止这种异常扰动传播到学生模型,从而增强了T-S模型在异常情况下的表示差异。在图像中,作为区域感知描述符的深度特征提供比逐像素更有效的区分信息。
传统的基于自动编码器(AE)的方法使用像素差异来检测异常,而我们使用密集的描述性特征进行区分。在图像中,作为区域感知描述符的深度特征提供比逐像素更有效的区分信息。
我们引入了一个单类瓶颈嵌入(OCBE)模块,进一步压缩特征编码。我们的OCBE模块包括多尺度特征融合(MFF)块和one-class嵌入(OCE)块,两者与学生解码器一起进行联合优化。值得注意的是,前者聚合低级别和高级别特征以构建用于正常模式重建的丰富嵌入。而后者旨在保留有利于学生解码教师响应的基本信息。
contribution
-
我们引入了一种简单但有效的反向蒸馏范式,用于异常检测。编码器-解码器结构和反向知识蒸馏策略在整体上解决了传统KD模型中的non-distinguishing filters问题,提高了T-S模型在异常情况下的区分能力。
-
我们提出了一个one-class瓶颈嵌入模块,将教师的高维特征投影到紧凑的单类嵌入空间。这一创新有助于在学生端保留丰富而紧凑的代码,用于还原无异常表示。
-
我们进行了大量实验,并展示了我们的方法实现了新的SOTA性能。
Related work
AutoEncoder或者GAN通过重构样本来进行异常检测。这些方法依赖于一个假设,即在正常样本上训练的生成模型只能成功地重建无异常区域,而不能重建异常区域。最近的研究表明,深度模型具有很好的泛化性,甚至可以很好地恢复异常区域。
值得注意的是,所提出的反向知识蒸馏同样采用了编码器-解码器架构,但与基于构造的方法有两个关键不同之处。首先,在生成模型中,编码器与解码器是联合训练的,而我们的反向蒸馏将一个预训练模型冻结为教师模型。其次,与像素级重构误差不同,它在语义特征空间上执行异常检测。
Approach
problem formulation
anomaly-free images : \(\mathcal{I}^t=\{\mathcal{I}^t_1,\dots,\mathcal{I}^t_n\}\)
a query set containing both normal and anomaly samples \(\mathcal{I}^q=\{\mathcal{I}^q_1,\dots,\mathcal{I}^q_n\}\)
目标是训练一个模型来识别和定位查询集中的异常。
在异常检测的情境中,\(\mathcal{I}^t\) 和 \(\mathcal{I}^q\) 中的正常样本都遵循相同的分布。超出分布的样本被视为异常。
system overview
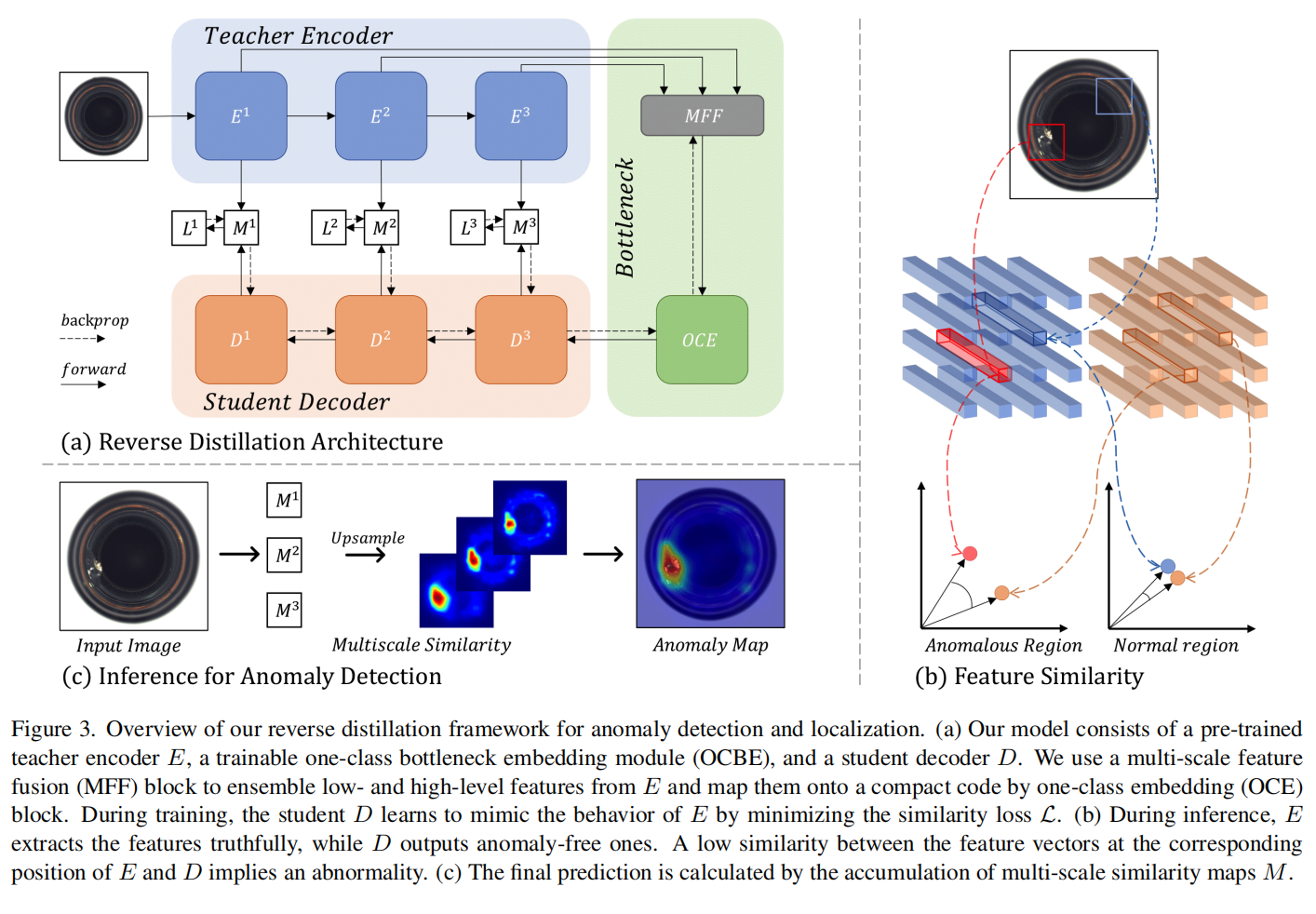
teacher E提取多尺度表征,student D从bottleneck的嵌入中还原特征。
在测试/推理过程中,教师E提取的表示可以捕获异常样本中异常的、分布外的特征。然而,学生解码器D无法从相应的嵌入中重建这些异常特征。在所提出的T-S模型中,异常表征的低相似性意味着较高的异常得分。
3.1. Reverse Distillation
为了提高T-S模型在未知的、超出分布的样本上的表征多样性,我们提出了一种新颖的反向蒸馏范式,其中T-S模型采用编码器-解码器架构,知识从教师模型的深层传递到学生模型的前几层,即首先将高级语义知识传递给学生模型。
在反向蒸馏范式中,教师编码器E的目标是提取全面的表示。我们遵循之前的工作,并使用在ImageNet上预训练的编码器作为我们的骨干网络E。为了避免T-S模型收敛到平凡解,在知识蒸馏过程中,教师E的所有参数被冻结。
为了匹配E的中间表示,学生解码器D的架构与E相比是对称的但是相反的。这种反向设计有助于消除学生网络对异常的响应,而对称性使其具有与教师网络相同的表示维度。
在我们的反向蒸馏中,学生解码器D在训练过程中旨在模仿教师编码器E的行为。在这项工作中,我们探索了基于多尺度特征的蒸馏用于异常检测。背后的动机是神经网络的浅层提取低级信息的局部描述符(例如,颜色、边缘、纹理等),而深层具有更广泛的感受野,能够表征区域/全局语义和结构信息。也就是说,在T-S模型中低级和高级特征的低相似性分别表示局部异常和区域/全局结构异常。
数学上,让 \(\phi\) 表示从原始数据 \(I\) 到one-class bottleneck嵌入空间的投影,我们的T-S模型中的配对激活对应关系是 \(\left\{f_E^k=E^k(I), f_D^k=D^k(\phi)\right\}\),其中 \(E^k\) 和 \(D^k\) 分别代表教师模型和学生模型中的第 \(k\) 个编码和解码块。\(f_E^k, f_D^k \in \mathbb{R}^{C_k \times H_k \times W_k}\),其中 \(C_k, H_k\) 和 \(W_k\) 分别表示第 \(k\) 层激活张量的通道数、高度和宽度。在T-S模型中的知识传递中,余弦相似度被作为KD损失,因为它更精确地捕捉了高维和低维信息之间的关系。具体来说,对于特征张量 \(f_E^k\) 和 \(f_D^k\),我们沿通道轴计算它们的向量级余弦相似性损失,并得到一个2-D异常图 \(M^k \in \mathbb{R}^{H_k \times W_k}\):
\(M^k\) 中的大值表示该位置具有很高的异常。考虑到多尺度知识蒸馏,学生优化的标量损失函数通过累积多尺度异常图获得:
其中 \(K\) 表示在实验中使用的特征层的数量。
3.2. One-Class Bottleneck Embedding
直接将E中最后一个编码块的激活输出馈送给D存在两个不足之处。
- 知识蒸馏中的教师模型通常具有较高的容量。尽管高容量模型有助于提取丰富的特征,但所获得的高维描述符可能存在相当多的冗余。表示的高自由度和冗余对于学生模型来解码关键的无异常特征是有害的。
- 骨干网络中最后一个编码块的激活通常表征输入数据的语义和结构信息。由于知识蒸馏的反向顺序,直接将这种高级表示馈送到学生解码器对于低级特征的重建构成了挑战。
为了解决上述 one-class 蒸馏中的第一个不足,我们引入了一个可训练的one-class嵌入块,将教师模型的高维表示投影到低维空间。我们将异常特征定义为正常模式上的扰动。然后,这个紧凑的嵌入块充当了信息瓶颈,有助于阻止不寻常的扰动传播到学生模型,从而增强了T-S模型对异常的表示差异。
为了解决解码器D中低级特征恢复的问题,MFF块在进行one-class嵌入之前将多尺度表示进行拼接。为了在拼接特征中实现表示对齐,我们通过一个或多个步长为2的3×3卷积层对浅层特征进行降采样,然后进行batch normalization和ReLU激活函数。接下来,我们利用一个步幅为1的1×1卷积层和一个带有ReLU激活的批量归一化层,以获得富含信息但紧凑的特征。
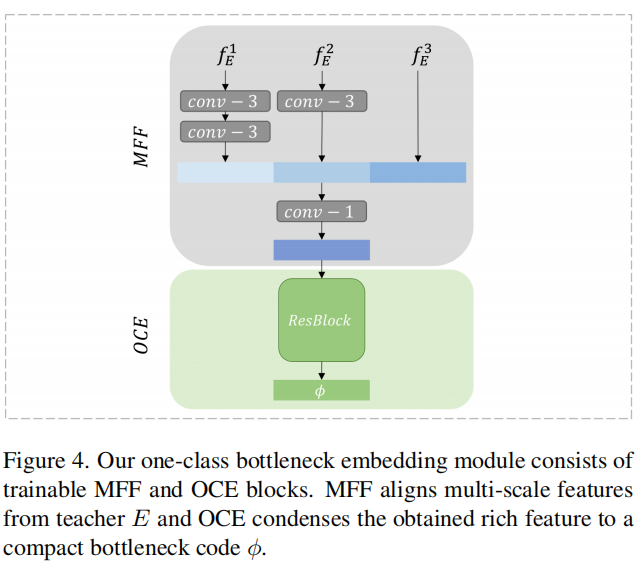
我们在图4中描述了OCBE模块,其中MFF聚合了低级和高级特征,以构建一个富含信息的嵌入,用于正常模式的重构,而OCE则旨在保留有利于学生解码教师响应的关键信息。在图4中,灰色的卷积层和绿色的ResBlock是可训练的,在正常样本上进行知识蒸馏时与学生模型D一起进行优化。
3.3. Anomaly Scoring
根据公式1,我们从T-S表示对中获得一组异常映射,其中映射\(M_k\)中的值反映了第\(k\)个特征张量的点异常情况。为了定位查询图像中的异常,我们将\(M^k\)上采样到图像大小。\(\Psi\) 表示本研究中使用的双线性上采样操作。然后,像素级地累积所有异常映射,形成精确的分数图\(S_{I^q}\):
为了去除分数图中的噪声,我们通过高斯滤波对\(S_{A L}\)进行平滑处理。
对于异常检测来说,对分数图\(S_{A L}\)中的所有值进行平均对于具有小异常区域的样本来说是不公平的。最具响应性的点存在于任何大小的异常区域中。因此,我们将\(S_{A L}\)中的最大值定义为样本级别的异常分数\(S_{A D}\)。这背后的直觉是,在正常样本的异常分数图中不存在显著的响应。
4. Experiments and Discussionsx
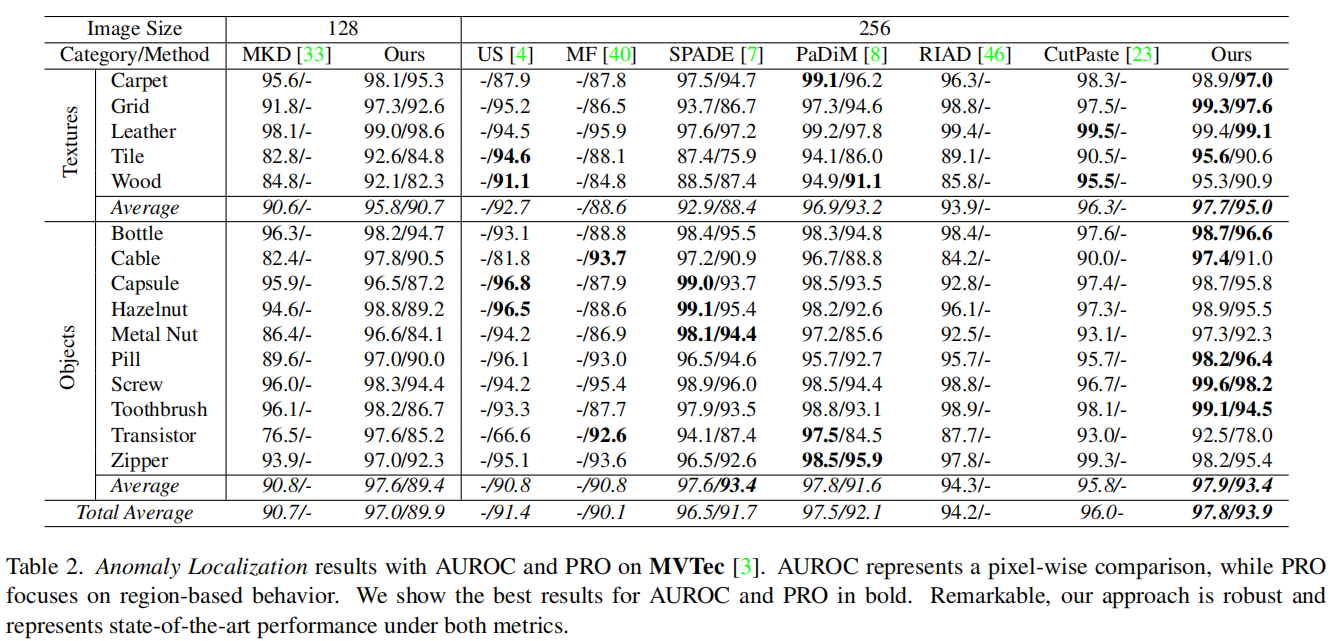
4.1. Anomaly Detection and Localization
对于异常检测,我们将(AUROC)作为评估指标。
对于异常定位,我们报告了AUROC和per-region-overlap(PRO)。
Experimental results and discussions.

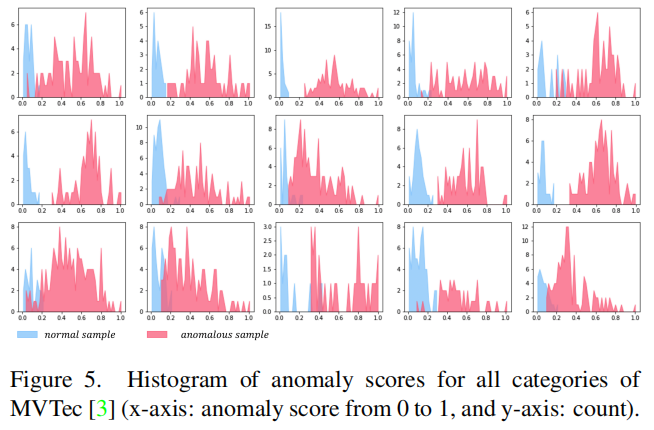
异常分数的统计数据如图5所示。正常样本(蓝色)和异常样本(红色)的非重叠分布表明了我们T-S模型在异常检测方面的强大性能。

Complexity analysis
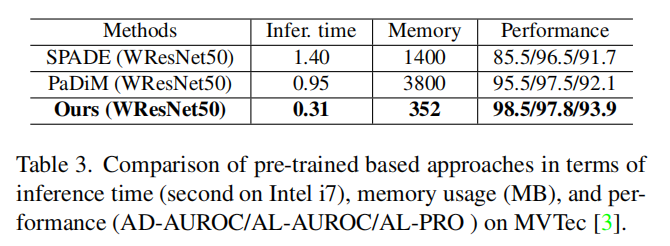
最近基于预训练模型的方法通过从无异常样本中提取特征作为度量标准,取得了较好的性能表现[7, 8]。然而,存储特征模型会导致大量的内存消耗。相比之下,我们的方法只依赖于额外的卷积神经网络模型,却取得了更好的性能。如表3所示,我们的模型在时间和内存复杂性较低的情况下获得了性能提升。
Limitations
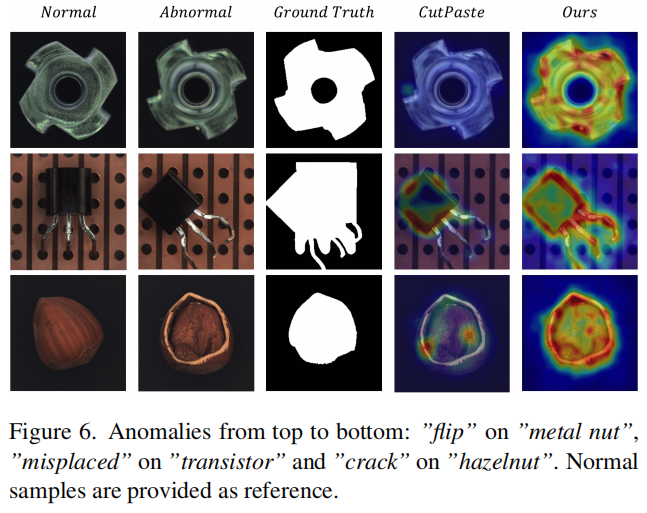
我们观察到,在晶体管数据集上的定位性能相对较弱,尽管异常检测性能良好。这种性能下降是由于预测和注释之间的误解所致。如图6所示,我们的方法定位了错误放置的区域,而真实情况包括了错误放置和原始区域。缓解这个问题需要将更多特征与上下文关系关联起来。
我们经验性地发现,具有更广泛感知范围的高级特征层可以提高性能。例如,使用第二和第三层特征进行异常检测可以实现94.5%的AUROC,而仅使用第三层可以将性能提高到97.3%。此外,将图像分辨率减小到128×128也可以实现97.6%的AUROC。我们在补充材料中展示了更多正面和负面的异常检测和定位案例。
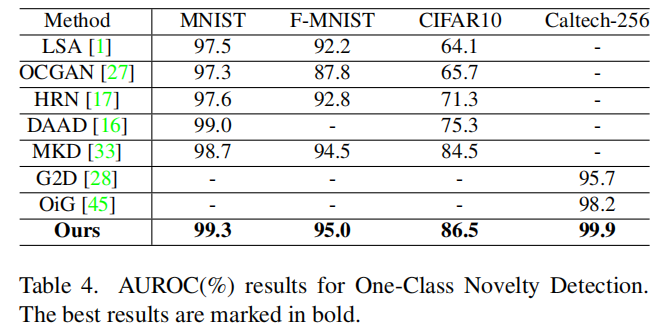
4.2. One-Class Novelty Detection
我们使用来自单一类别的样本来训练模型,并检测新样本。需要注意的是,新颖性分数定义为相似性映射中分数的总和。(不懂它怎么算的)
4.3. Ablation analysis
我们研究了OCE和MFF块对异常检测的有效性,并在表5中报告了数值结果。我们以预训练的残差块作为基线。
来自预训练残差块的嵌入可能包含异常特征,这会降低T-S模型的表示差异。我们的可训练OCE块压缩特征代码,而MFF块融合丰富的特征到嵌入中,从而实现更精确的异常检测和定位。

表6显示了不同骨干网络作为教师模型的定性比较。直观地,更深和更宽的网络通常具有更强的表示能力,有助于精确检测异常。值得注意的是,即使使用较小的神经网络,比如ResNet18,我们的反向蒸馏方法仍然能够实现出色的性能。
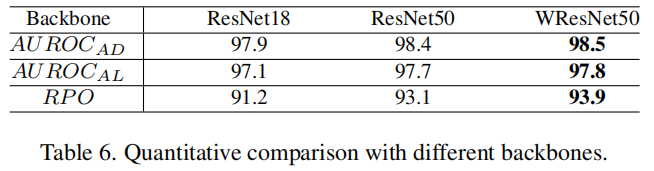
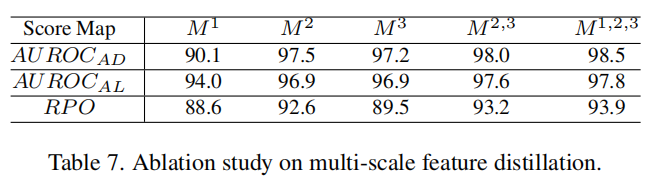
此外,我们还探讨了不同网络层对异常检测的影响,并在表7中展示了结果。对于单层特征,M2的结果最好,因为它权衡了局部纹理和全局结构信息。多尺度特征融合有助于覆盖更多类型的异常情况。
- distillation detection embedding one-class Anomalydistillation detection embedding one-class detection机器anomaly mean-shifted contrastive detection anomaly distribution detection anomaly论文 isolation detection anomaly forest discrimination distribution detection anomaly multi-class detection unified anomaly detection learning anomaly survey code embeddings automatic detection one-class