乘法器
顺序乘法器
我们需要明确的是两个D_WIDTH位宽的数相乘,结果位宽为2*D_WIDTH, 对于负数乘法,可以利用乘数和被乘数的符号位进行异或得到积的符号位,通过判断符号位得到乘数和被乘数的绝对值,将负数乘法转为无符号数乘法进行运算,首先初始化乘数寄存器和被乘数寄存器Multiplicand,被乘数寄存器的低D_WIDTH位为输入的被乘数的绝对值,高D_WIDTH位为0,初始化乘积寄存器product[2*D_WIDTH-1:0]=0,
if (Multiplier>0)
product< = Multiplier[0]? Multiplicand+ product : product;
Multiplicand <={ Multiplicand [2*D_WIDTH-2:0] ,1’b0}
Multiplier<= {1’b0,Multiplier[D_WIDTH-1:1]};
end
上图中可以看到,二进制计算乘法比较简单,由于每一位上只有0和1,乘法计算其实就简化成了位移和加法,乘数每一位和被乘数相乘,结果不是完全复制就是0,只不过对应着不同的位移。
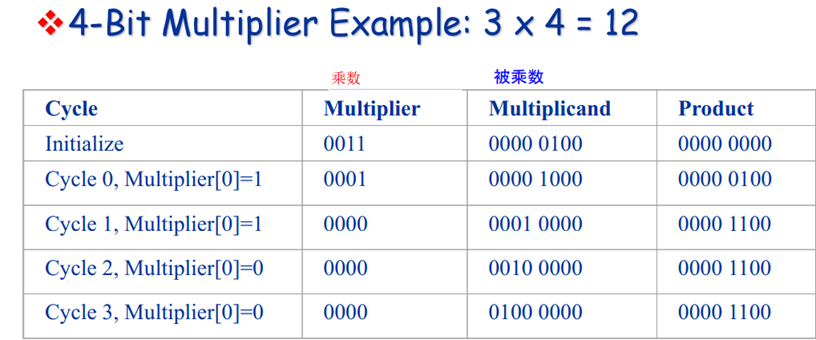
为了节约晶体管,只需从低位开始将被乘数逐次左移一位,乘数逐次右移一位,不断将计算结果加在上一步的结果上,直到乘数为0不能再右移为止。
这种方式虽然节约了电路但由于下一步加法依赖上一步加法计算结果,下一步位移也依赖上一步位移结果,因此只能顺序进行,结果就是运算比较慢。32位数的计算就比4位数运算多八倍执行时间。无法用单纯的组合逻辑电路形成,因为被乘数寄存器和乘积寄存器内容发生变化需要时序控制.

module multi_seq#(parameter D_WIDTH=8)(
input clk,
input rst_n,
input [D_WIDTH-1:0] mul_A,
//被乘数,5位,有符号补码
input [D_WIDTH-1:0] mul_B,
//乘数5位,有符号补码
input start,
output reg [2*D_WIDTH-1:0] result,
output reg done
);
reg[1:0] state;
reg[2*D_WIDTH-1:0] multi_A;
reg[D_WIDTH-1:0] multi_B;
reg[2*D_WIDTH-1:0] result_tmp;
reg neg;
wire [D_WIDTH-1:0] abs_A;
wire [D_WIDTH-1:0] abs_B;
assign abs_A = mul_A[D_WIDTH-1] ? ~mul_A+1 : mul_A ;
assign abs_B = mul_B[D_WIDTH-1] ? ~mul_B[D_WIDTH-1:0]+1 : mul_B ;
always@(posedge clk)
if(~rst_n) begin
multi_A <= 0;
multi_B <= 0;
neg <= 0;
done <= 0;
result_tmp <= 0;
state <= 0;
result <= 0;
end
else if(start)
case(state)
0: begin //{D_WIDTH{1'b0}}
multi_A <= {{D_WIDTH{1'b0}},abs_A};
multi_B <= abs_B;
neg <= mul_A[D_WIDTH-1]^mul_B[D_WIDTH-1];
done <= 0;
state <= state+1;
result_tmp <= 0;
end
1:begin
if(multi_B>0) begin
result_tmp<=multi_B[0]?(result_tmp + multi_A) : result_tmp;
multi_B <= {1'b0,multi_B[D_WIDTH-1:1]};
multi_A <={multi_A[2*D_WIDTH-2:0],1'b0};
end
else begin
state <= state + 1;
end
end
2:begin
done<=1'b1;
result<= neg ? (~result_tmp+1): result_tmp;
state <= state+1;
end
3: begin
done<=1'b0;
state<=0;
end
endcase
endmodule
阵列乘法器
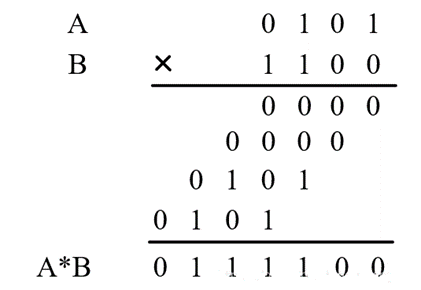
4比特的AB两数相乘的竖式计算表示成如下,为了区分,方便在阵列格式中看出差异,图中标记了不同的颜色,每组颜色表示一组部分和,每一列将使用半加器或者全加器两两相加,其结果表示为Si,如:S0 = a0b0,S1 = ( a1b0+a0b1 )mod 2,……,每一列每两个数产生的进位将传递至相邻高的一列参与计算。所以,将其结构表示为如下结构,即阵列乘法器(Array Multiplier)。
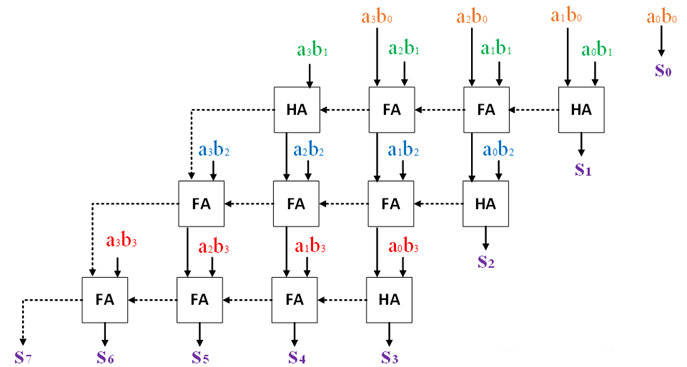
其中ai,bi表示A和B的某个比特,aibi表示ai与bi相与,使用与门电路生成,aibi的值只有0和1。S表示AB相乘的结果。
其中HA表示半加器,FA表示全加器,虚线箭头表示进位传播的路线。使用行波进位加法器RCA搭建如上的阵列乘法器即RCA阵列乘法器。
对于m*n的RCA阵列乘法器,将消耗资源如下:
m*n个与门,n个半加器,mn - m – n个全加器
根据进位传播链,可以看出RCA阵列乘法器的关键路径如下:

上图中红线和紫线是该阵列乘法器中由于累加造成的进位链的最长路径。
另外,通过使用不同结构的加法器可缩短该进位链的传播延时,如使用进位保留加法器(Carry Save Adder, CSA)。

将RCA阵列乘法器的进位连接至斜下角的加法器,变成上图结构即CSA阵列乘法器,CSA结构的阵列乘法器将进位与和分别计算,不必计算该层的进位,省去了行波进位加法器进位链的依赖,只在最后一级通过RCA结构(上图绿色虚框)传递进位合并最后的结果。
将两种结构的阵列乘法器面积与关键路径对比如下:
RCA结构乘法器使用了8个FA,4个HA,关键路径经过5个FA,2个HA。
CSA结构乘法器使用了8个FA,4个HA,关键路径经过3个FA,3个HA。
CSA结构使用相同的资源却有更优的性能。
Wallace tree 与阵列乘法器
传统的全加器因为有三个输入(A,B,Cin),产生2个输出(S,Cout),故常把全加器也称为3-2压缩器Wallance tree便是基于3-2压缩器构成的,Wallace结构将部分和分组,并同时计算,在最后一级使用加法器传播进位。这就构成了 Wallace Tree乘法器。以下是8*8比特的阵列乘法器Wallace树结构例子:
1.每3个加数一组,分组,进行进位保存加法的运算,求出3个数的和与进位,不足3个的保持下一次计算。如图左到右所示。
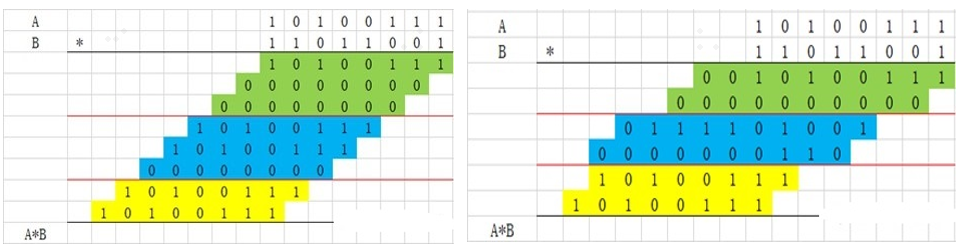
2. 继续每3个加数分组, 求出3个数的和与进位

3.分组, 求出3个数的和与进位

继续计算和以及进位,最后利用进位行波进位加法器计算最终的乘积结果。

module Wallace_tree#(parameter width=8)(
input [width-1:0]mul_A,
input [width-1:0]mul_B,
output [2*width-1:0]P
);
wire [width*2-1:0]xy[0:width-1];
genvar i,j;
generate
for(i=0;i<width;i=i+1)begin
for(j=0;j<width;j=j+1) begin
assign xy[i][j]=mul_A[j]&mul_B[i];
//B对应列为乘数
end
assign xy[i][2*width-1:width]={width{1'b0}};
//每一行都补8位到输出位宽
end
endgenerate
wire [width*2-1:0]c_lev00,s_lev00,c_lev01,s_lev01;
wire [width*2-1:0]c_lev10,s_lev10,c_lev11,s_lev11;
wire [width*2-1:0]c_lev20,s_lev20,c_lev30,s_lev30;
//第0级
csa_add #(.width(2width)) u0_csa(
.add_A(xy[0]),
.add_B(xy[1]<<1),
.add_C(xy[2]<<2),
.c(c_lev00),
.s(s_lev00)
);
csa_add #(.width(2width)) u1_csa(
.add_A(xy[3]<<3),
.add_B(xy[4]<<4),
.add_C(xy[5]<<5),
.c(c_lev01),
.s(s_lev01)
) ; //第1级
csa_add #(.width(2width)) u2_csa(
.add_A(c_lev00<<1),
.add_B(s_lev00),
.add_C(s_lev01),
.c(c_lev10),
.s(s_lev10)
);
csa_add #(.width(2width)) u3_csa(
.add_A(xy[6]<<6),
.add_B(xy[7]<<7),
.add_C(c_lev01<<1),
.c(c_lev11),
.s(s_lev11)
);
//第2级
csa_add #(.width(2width)) u4_csa(
.add_A(c_lev10<<1),
.add_B(s_lev10),
.add_C(s_lev11),
.c(c_lev20),
.s(s_lev20)
);
//第3级
csa_add #(.width(2width)) u5_csa(
.add_A(c_lev11<<1),
.add_B(c_lev20<<1),
.add_C(s_lev20),
.c(c_lev30),
.s(s_lev30)
);
//行波进位
rca_add #(.width(2*width)) u_rca(
.add_A(c_lev30<<1),
.add_B(s_lev30),
.CI(1'b0),
.SUM(P),
.CO( )
);
endmodule
进位保留加法器,行波进位加法器
module csa_add #(width=4) (
input [width-1:0] add_A,
input [width-1:0] add_B,
input [width-1:0] add_C,
output [width-1:0] c,
output [width-1:0] s
);
genvar i;
generate
for(i=0; i<width; i=i+1) begin
full_adder u_full_adder(
.A ( add_A[i] ),
.B ( add_B[i] ),
.CI ( add_C[i] ),
.CO ( c[i] ),
.S ( s[i] )
);
end
endgenerate
endmodule module rca_add#(parameter width=4)(
input [width-1:0] add_A,
input [width-1:0]add_B,
input CI,
output [width-1:0] SUM,
output CO);
wire [width:0] C_temp;
assign C_temp[0]=CI;
assign CO=C_temp[width];
generate
genvar i;
for(i=0;i<width;i=i+1) begin
full_adder u(
.A(add_A[i]),
.B(add_B[i]),
.CI(C_temp[i]),
.S(SUM[i]),
.CO(C_temp[i+1])
);
end
endgenerate
endmodule
全加器
module full_adder(
input A,
input B,
input CI,
output CO,
output S); assign CO= CI&(A^B)|A&B;
assign S=A^B^CI;
endmodule//verlog
booth 编码乘法器
Booth编码
首先理解下面一个等式:
$Y=-2^{n-1}y_{n-1}+2^{n-2} y_{n-2}+2^{n-3} y_{n-3}+…+2^1 y_1+y_0+y_{-1} (其中y_{-1}=0) $(公式1)
$=2^{n-1} (-y_{n-1}+y_{n-2})+ 2^{n-2} (-y_{n-2}+y_{n-3})+…+(-y_0+y_{-1})$ (公式2)
$= (-2y_{n-1}+y_{n-2}+y_{n-3})2^{n-2}+(-2y_{n-3}+y_{n-4}+y_{n-5}) 2^{n-4}+…+(-2y_1+y_0+y_{-1}) $(公式3)
可以证明的是,这三个公式是相等的,一个有符号的二进制数的补码用公式1来表示,可以等价地写成公式2和公式3。
这个过程就是对Y进行编码的过程。编码之后,乘数Y中的位被划分为不同的组, 每一组包括3位,这些组互相交叠。
Booth编码可以减少部分积的数目(即减少乘数中1的个数),用来计算有符号乘法,提高乘法运算的速度。

如上图所示为二进制乘法的过程,也是符合我们正常计算时的逻辑,我们假设有一个8位乘数(Multiplier),它的二进制值为0111_1110,它将产生6行非零的部分积,因为它有6个非零值(即1)。如果我们利用公式2:$Y=2^{n-1} (-y_{n-1}+y_{n-2})+ 2^{n-2} (-y_{n-2}+y_{n-3})+…+(-y_0+y_{-1})$ (公式2)
将这个二进制值改为1000_00-10,其中低四位中的-1表示负1,可以证明两个值是相等的。可以这样简单理解,那就是在原值的末尾加辅助位0,变为0111_1110_0,然后利用低位减去高位,即得到1000_00-10。这样一变换可以减少0的数目,从而减少加的次数,我们只需相加两个部分积,但是最终的加法器必须也能执行减法。这种形式的变换称为booth encoding(即booth编码),它保证了在每两个连续位中最多只有一个是1或-1。部分积数目的减少意味着相加次数的减少,从而加快了运算速度(并减少了面积)。从形式上来说,这一变换相当于把乘数变换成一个四进制形式。
booth乘法过程
|
B[i] |
B[i-1] |
加码结果(B[i-1]-B[i]) |
|
0 |
0 |
0(无操作) |
|
0 |
1 |
1(加被乘数) |
|
1 |
0 |
-1(减被乘数) |
|
1 |
1 |
0(无操作) |
上图是BOOTH算法的数学表达。由于FPGA擅长进行并行移位计算,所以BOOTH算法倒也好实现。
我们以6*14为例,对booth乘法运算进行举例:6的有符号二进制表示为00110,14的有符号二进制表示为01110,01110的booth编码表示为100-10,乘累加结果表示为P:
|
一开始的时候在乘数2的“负一位”加上一个默认0值 |
01110 0(乘数) |
|
先判断[0:-1],结果是2’b00,表示‘0’,亦即无操作 |
P=00000,被乘数左移1位,12 |
|
判断[1:0],结果是2’b10,表示‘-1’,亦即减左移后的被乘数操作 |
减去左移一位后的被乘数:P=-12,被乘数左移2位:24 |
|
判断[2:1],结果是2’b00,表示‘0’,亦即无操作 |
P=-12:被乘数左移3位,48 |
|
判断[3:2],结果是2’b10,表示‘0’,亦即无操作 |
P=-12,被乘数左移4位,96 |
|
判断[4:3],结果是2’b00,表示‘1’,亦即加左移后的被乘数操作 |
P=-12+96=84 |
verilog代码
`timescale 1ns / 1p
module booth_mult#(parameter D_IN=8)(
input clk,
input rst_n,
input start,
input [D_IN-1:0]mul_A,
input [D_IN-1:0]mul_B,
output reg done,
output reg [2*D_IN-1:0]Product
);
reg [1:0] state;
reg [2*D_IN-1:0] mult_A; // result of mul_A
reg [D_IN:0] mult_B; // result of mul_A
reg [2*D_IN-1:0] inv_A; // reverse result of mul_A
reg [2*D_IN-1:0] result_tmp; // operation register
wire [1:0] booth_code;
assign booth_code = mult_B[1:0];
assign stop=(~|mult_B)||(&mult_B);
always @ ( posedge clk or negedge rst_n )
if( !rst_n ) begin
state <= 0;
mult_A <= 0;
inv_A <= 0;
result_tmp <= 0;
done <= 0;
Product<=0;
end
else if( start )
case( state )
0: begin
mult_A <= {{D_IN{mul_A[D_IN-1]}},mul_A};
inv_A <= ~{{D_IN{mul_A[D_IN-1]}},mul_A} + 1'b1 ;
result_tmp <= 0;
mult_B <= {mul_B,1'b0};
state <= state + 1'b1;
end
1: begin
if(~stop) begin
case(booth_code)
2'b01 : result_tmp <= result_tmp + mult_A;
2'b10 : result_tmp <= result_tmp + inv_A;
default: result_tmp <= result_tmp;
endcase
mult_A <= {mult_A[14:0],1'b0};
inv_A <= {inv_A[14:0],1'b0};
mult_B <= {mult_B[8],mult_B[8:1]};
end
else
state <= state + 1'b1;
end
2:begin
done<=1'b1;
Product<= result_tmp;
state <= state+1;
end
3: begin
done<=1'b0;
state<=0;
end
endcase
endmodule
3.5 改进的booth编码
最经常使用的是改进的booth编码。乘数按三位一组进行划分,相互重叠一位。其实就是把公式1重写为公式3。每一组按下表编码,并形成一个部分积。
基4 Booth编码将使得乘法累积的部分和数减少一半,只涉及到移位和补码计算。对于二进制码为1010…1010的乘数(1与0交替),如果采用基2 Booth编码,则部分和累积的输入有几乎一半为被乘数的补码,所以,相比于普通的阵列乘法器,基2 Booth编码的乘法器性能不升反降,基4 Booth编码可以避免以上问题。
编码原则其实就是:$-2x_{2i+1}+x_{2i}+x_{2i-1}$
$Y=-2^{n-1} y_{n-1}+2^{n-2} y_{n-2}+2^{n-3} y_{n-3}+…+2^1 y_1+y_0+y_{-1} (其中y_(-1)=0) $
$= (-2y_{n-1}+y_{n-2}+y_{n-3})2^{n-2}+(-2y_{n-3}+y_{n-4}+y_{n-5}) 2^{n-4}+…+(-2y_1+y_0+y_{-1}) $
假设输入被乘数为X,乘数为Y,所以X*Y为:
$X*Y= X*(-2y_{n-1}+y_{n-2}+y_{n-3})2^{n-2} +X*(-2y_{n-3}+y_{n-4}+y_{n-5}) 2^{n-4}+X*(-2y_1+y_0+y_{-1})$
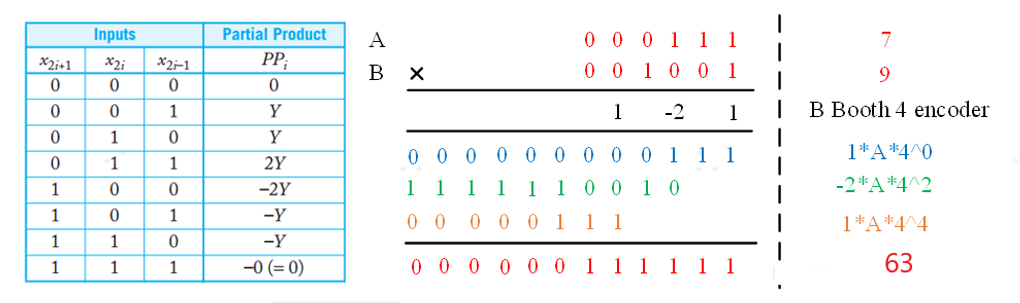
如上所示,是7*9的基4booth编码的运算过程。
1.B[2]决定了输出系数的符号位,定义为neg;
2.当输入码字为011和100时,输出绝对值为2,定义为two;
3.当输入码字为000和111时,输出绝对值为0,定义为zero;
4.除了以上码字,输出绝对值为1,定义为one。
5.生成部分和,根据编码器输出,与被乘数相乘,生成部分和: 如果编码器zero为1,则输出部分和为0;如果编码器one为1,则输出部分和为被乘数;如果编码器two为1,则输出部分和为被乘数左移1位;如果是负数,则生成补码输出。
16比特乘法器,从高位起,每三个一组,相互重叠一位,需要8个Booth编码器Booth Enc和8个生成部分和GenProd模块。根据Wallace树结构、CSA和行波进位加法器RCA,设计框图如下:
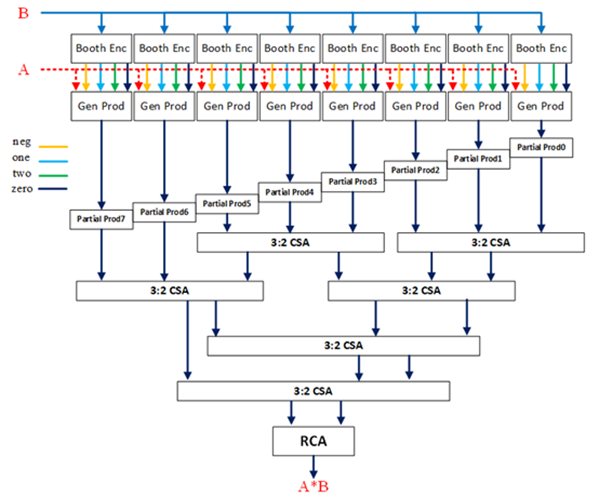
由于verilog 不支持数组传递进行例化,所以采用sverilog文件.v作为文件扩展名
module booth2_top#(parameter width=16)(
input [width-1:0] A,
input [width-1:0] B,
output [2*width-1:0] P
);
wire [7:0] neg, zero ,one, two;
wire [7:0][2*width-1:0] prod ;
genvar i;
generate
for(i=0; i<8; i=i+1)begin
if(i==0)
booth_enc u_booth_enc(
.code ({B[1:0],1'b0}),
.neg (neg[i] ),
.zero (zero[i] ),
.one (one[i] ),
.two (two[i] )
);
else
booth_enc u_booth_enc(
.code (B[i*2+1:i*2-1]),
.neg (neg[i] ),
.zero (zero[i] ),
.one (one[i] ),
.two (two[i] )
);
end
endgenerate
generate
for(i=0; i<8; i=i+1)begin
prod_gen u_prod_gen (
.A ( A ),
.neg ( neg[i] ),
.zero ( zero[i] ),
.one ( one[i] ),
.two ( two[i] ),
.prod ( prod[i] )
);
end
endgenerate
wallace_tree u_watree(
.prod(prod),
.P(P)
);
endmodule module booth_enc(
input [2:0]code,
output neg,
output zero,
output one,
output two
);
assign neg = code[2];
assign zero = (code==3'b000) || (code==3'b111);
assign two = (code==3'b100) || (code==3'b011);
assign one = !zero & !two;
endmodule
module prod_gen #(parameter width=16)(
input [width-1:0] A,
input neg,
input zero,
input one,
input two,
output [2width-1:0] prod
);
reg [2width-1:0] prod_tmp;
always @ () begin
prod_tmp = {(2width){1'b0}};
if (zero)
prod_tmp = {(2*width){1'b0}};
else if (one)
prod_tmp = { { width{A[width-1]} }, A};
else if (two)
prod_tmp = { { (width-1){A[width-1]} } , A, 1'b0};
end
assign prod = neg ? ( ~prod_tmp+1'b1 ) : prod_tmp;
endmodule
module full_adder(
input a,
input b,
input cin,
output cout,
output s
);
assign cout= cin&(a^b)|a&b;
assign s=abcin;
endmodule//verlog
wallace_tree加法器
module wallace_tree #(width=16) ( input [7:0][2*width-1:0] prod, output [2*width-1:0] P ); wire [2*width-1:0] s_level_11; wire [2*width-1:0] c_level_11; wire [2*width-1:0] s_level_12; wire [2*width-1:0] c_level_12; wire [2*width-1:0] s_level_21; wire [2*width-1:0] c_level_21;
compressor42 #(2width)
compressor42_level_11(
.in1 (prod[0] ),
.in2 (prod[1] << 2 ),
.in3 (prod[2] << 4 ),
.in4 (prod[3] << 6 ),
.sum (s_level_11 ),
.carry (c_level_11)
);
compressor42 #(2width)
compressor42_level_12(
.in1 (prod[4] << 8 ),
.in2 (prod[5] << 10 ),
.in3 (prod[6] << 12 ),
.in4 (prod[7] << 14 ),
.sum (s_level_12 ),
.carry(c_level_12) );
compressor42 #(2width)
compressor42_level_21(
.in1 (s_level_11 ),
.in2 (c_level_11 << 1),
.in3 (s_level_12 ),
.in4 (c_level_12 << 1),
.sum (s_level_21 ),
.carry (c_level_21)
);
rca_add #(2width) u_lca(
.a (s_level_21),
.b (c_level_21 << 1),
.cin (1'b0 ),
.sum (P ),
.cout ( )
);
endmodule
4-2压缩编码器
module compressor42 #(width=16) ( input [width-1:0] in1, input [width-1:0] in2, input [width-1:0] in3, input [width-1:0] in4, output [width-1:0] sum, output [width-1:0] carry ); wire [width-1:0] s_tmp; wire [width-1:0] c_tmp; genvar i; generate for(i=0; i<width; i=i+1) begin if(i == width-1) full_adder u_full_adder_1( .a(in1[i]), .b(in2[i]), .cin(in3[i]), .cout(), .s(s_tmp[i]) ); else full_adder u_full_adder_1( .a(in1[i]), .b(in2[i]), .cin(in3[i]), .cout(c_tmp[i+1]), .s(s_tmp[i]) ); end endgenerate //第二级加法操作 genvar j; generate for(j=0; j<width; j=j+1) begin if(j == 0) full_adder u_full_adder_2( .a(1'b0), .b(in4[j]), .cin(s_tmp[j]), .cout(carry[j]), .s(sum[j]) ); else full_adder u_full_adder_2( .a(c_tmp[j]), .b(in4[j]), .cin(s_tmp[j]), .cout(carry[j]), .s(sum[j]) ); end endgenerate endmodule
行波进位加法器
module rca_add#(parameter width=4)( input [width-1:0] a, input [width-1:0]b, input cin, output [width-1:0] sum, output cout ); wire [width:0] C_temp; assign C_temp[0]=cin; assign cout=C_temp[width]; genvar i; generate for(i=0;i<width;i=i+1) begin full_adder u( .a(a[i]), .b(b[i]), .cin(C_temp[i]), .s(sum[i]), .cout(C_temp[i+1]) ); end endgenerate endmodule