[VLDBJ 2019]Distributed Subgraph Matching on Timely Dataflow
只关注这篇中的subgraph matching的内容
定义
\(g = (V_g, E_g, L_g)\)分别表示点、边,以及把任意点或边映射成label的函数。如果是无标签图则会映射为空。
对于任意点\(\mu \in V_g\),定义\(N_g(\mu)\)为它的邻居节点,\(d_g(\mu) = |N_g(\mu)|\)为它的度,\(d_g\)和\(D_g\)为一张图的平均度和最大度。
定义\(g' \in g\)是一张子图。如果给一个\(V' \in V_g\),则可以得到一个induced subgraph \(g(V')\),即保留\(V'\)中所有点以及这些点之间的所有边的子图。
vertex cover: 是指图中的一个顶点子集,该子集包含图中每条边的至少一个端点。匹配时先匹配vertex cover可以减少中间结果。
TwinTwin: 包含中心节点和至多两个叶子节点的小树结构。
spanning tree:覆盖树,包含图的所有点,但不包含任何环路
subgraph matching
文章研究了在分布式环境下的subgraph matching,这里我们只关注匹配方法,以及相关实现。
-
将subgraph matching问题转为连接(join query)
文章将查询子图Q的每个点看作一个属性,数据图G中的边和匹配结果看作关系表,从而将匹配问题转为这些关系表进行多路连接查询。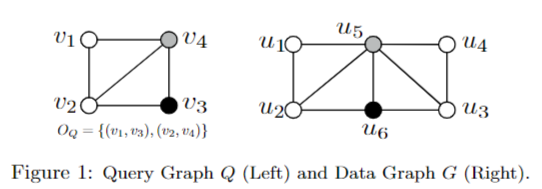
该图的查询可以表示为:
\(R(Q) = E(v1, v2) \Join E(v2, v3) \Join E(v3, v4) \Join E(v1, v4) \Join E(v2, v4)\)
这样的分解方法是Spark、Flink这种分布式数据库引擎原生支持的。
-
利用不同的连接策略。文章实现了四种:BinJoin,将查询分解为多个二元连接后,按顺序连接;WOptJoin,按固定顺序逐个匹配查询图的顶点;ShrCube,将查询看成超立方体,将计算任务分配给工作节点后本地计算;FullRep,每个分区都完整保存数据图,并行匹配查询图。
-
通用的优化手段。文章提出了批处理(Batching)、三角索引(TrIndexing)和压缩(Compression)三种,可以组合使用优化BinJoin和WOptJoin
-
基于Timely数据流系统实现。忽略这块内容。
BinJoin
- 将查询图Q分解成多个连接单元(join unit)。常见的如star, TwinTwin, Clique。需要保证分解后的子图的点和边的并集等于原始图。
- 针对每一个连接单元,可以在每个数据分区内独立并行地计算出他的匹配结果,这些匹配结果可以看作基础关系表,然后将这些基础关系表按一定顺序进行二元连接,最终得到查询图Q的匹配。
- 定义连接顺序。文中使用左深树连接顺序,该顺序要求每次连接中至少有一个基础关系。此外还可以用布什连接。
模型会动态优化连接计划。
WOptJoin
- 定义顶点匹配顺序。
- 逐步扩展匹配。按照得到的顺序,第一次匹配第一个点,第二次匹配前两个点,依次类推直到全部匹配完成。
- 候选集计算。计算第i轮时需要保证候选点和钱i-1个已匹配点在data图中也连通。
- Timely上的分布候选集计算(BigJoin)以及优化。
ShrCube
- 将查询图看成一个n维的超立方,其中n是查询图的顶点数。为每个查询图的点分配一个bucket number \(b_i\),使得所有bucket number相乘等于w。
- 将数据图的每个点u利用哈希函数映射到1到\(b_i\)的编号\(z_i\)上 (\(1 \leq z_i \leq b_i\))。
- 每个n元组\((z_1, z_2, \dots, z_n)\)表示一个计算任务,分配给一个worker
- 将超立方的计算均匀地分配给集群中的w个工作节点
- 每个工作节点无需通信
其他
- PSgL,通过广度优先遍历进行子图匹配。从初始点开始逐步扩展,每次选择代价最小的查询顶点。可以看作是StarJoin的变种
- CrystalJoin,通过压缩中间结果来减少“输出危机”,先计算查询图的顶点覆盖匹配,再压缩其他顶点,然后组合成最后的结果。可以看作是OptJoin的一种执行计划
- FullRep,对于某一查询图的点,每个worker分别匹配一个不同的数据图点
通用优化
- Batching,将整个任务分成多批次进行,每批次彼此独立。对于BinJoin选择参与最多join unit的点v作为batching顶点。对于WOptJoin,在第一个点\(v_1\)上做batching
- Triangle Indexing,对数据图G的所有三角形进行预计算,存储每个三角形的三条边,在数据图分区时,保证每个三角形的三条边都在同一个分区中。这样能让BinJoin支持Clique作为连接单元,也能让WOptJoin减少交叉分区的通信。但需要额外30%的存储开销。
- Compression,通过压缩中间结果来减少子图匹配的存储和通信成本。存储上会将完整结果展开的形式压缩成数组存储。对于BinJoin,可以对clique压缩non-key点,对star可以压缩non-root点。其中,key点是指键值点,也就是从这个点引出的整个join unit。而对于WOptJoin,对于查询图Q中的点\(v_i\),如果不存在\(v_j, j>i\)使得\((v_i, v_j) \in E_Q\),则可以压缩\(v_i\)不进行后续的计算