Kaggle:Titanc Survived
数据处理
对于这个问题,在训练集中给了10列作为特征。其中有一些对结果预测并没有太大影响的PassengerId、Name、Cabin、Ticket。
PassengerId可以直接作为pandas读取cvs文件时候的index_col。
train_data = pd.read_csv("dataset/train.csv", index_col="PassengerId")
test_data = pd.read_csv("dataset/test.csv", index_col="PassengerId")
Ticket是票号样本中每个都是不同的离散结果对于预测没有帮助,所以直接用dataframe.drop()删除即可。
Name这一列虽然我认为对预测结果影响并不大,但是根据kaggle网站上一些的code,将这一列包含的预测信息分成两个方向,一个方向是名字的长度;另一个是名字称呼(Mr、Miss这些,但是我实际测试并没有太大的影响,也可能是模型的问题。)
Cabin这一列有很多空值,可以删除这一里,也可以用每一项上的首字母来进行分类,如果是null值,就给分成n这一类,然后在使用one-hot编码。
所以对于这三列,直接删除掉了。
train_data.drop(['Name','Ticket','Cabin'], axis=1, inplace=True)
test_data.drop(['Name','Ticket','Cabin'], axis=1, inplace=True)
可以用info、describe、value_counts等函数,输出一些信息看看。
all_features = pd.concat((train_data.iloc[:, 1:], test_data))
print(all_features.shape)
all_features.info()
all_features.describe()
all_features['Embarked'].value_counts(normalize=True)
大致的分析以下,对于Age中的空值使用平均年龄代替;列Embarked中缺失的值使用出现频率最高的S代替。
all_features['Age'] = all_features['Age'].fillna(all_features['Age'].mean())
all_features['Fare'] = all_features['Fare'].fillna(0)
all_features['Embarked'] = all_features['Embarked'].fillna('S')
最后还要将这些不是数值的特征转换成ont-hot编码,或者是用数字代替其类别。
sex_mapping = {'male':0,'female':1}
embarked_mapping = {'S':0,'C':1,'Q':2}
all_features['Sex'] = all_features['Sex'].replace(sex_mapping)
all_features['Embarked'] = all_features['Embarked'].replace(embarked_mapping)
all_features.describe()
至此数据就如此“粗略”地处理完了。
定义模型、损失和优化
定义了一个三层的网络模型,并对每层的权重自定义了初始化。
# 7 -> 5 -> 1
class TNet(nn.Module):
def __init__(self):
super(TNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_features, 7),
nn.BatchNorm1d(7),
nn.ReLU())
self.layer2 = nn.Sequential(
nn.Linear(7, 5),
nn.BatchNorm1d(5),
nn.ReLU())
self.layer3 = nn.Sequential(
nn.Linear(5, 1),
nn.Sigmoid())
self.init_weights()
def init_weights(self):
# 使用正态分布初始化第一二三层权重
nn.init.kaiming_normal_(self.layer1[0].weight, nonlinearity='relu')
nn.init.kaiming_normal_(self.layer2[0].weight, nonlinearity='relu')
# 使用常数值初始化第四层权重
nn.init.xavier_normal_(self.layer3[0].weight)
def forward(self, X):
out = self.layer1(X)
out = self.layer2(out)
out = self.layer3(out)
return out
这个案例相当于是一个二分类问题,所以用的损失函数是BCELoss,也可以按照多分类问题使用CrossEntropyLoss作为损失函数。
这个案例中用以训练的数据比较少,所以还是要用到K折交叉验证,具体的训练和之前做过房价预测的案例相似,不再赘述了。
在训练中,将保存验证集中损失最低的模型,用以后续的预测。
if test_ls[epoch] < model_loss:
model_loss = test_ls[epoch]
torch.save(net.state_dict(), 'model.ckpt')
图中左侧为base_bine在第一折的表现,右侧为上述TNet的表现。
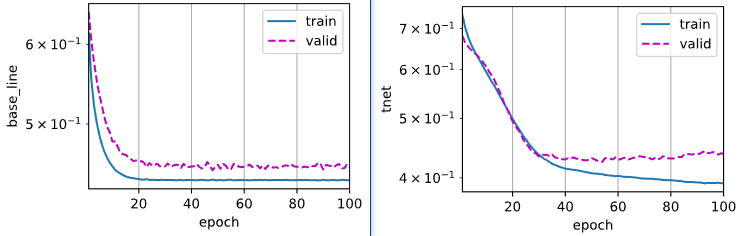
最终用了很长的时间,在kaggle上的评分也没超过0.79。即使是在将name和cabin这两列的特征也进行处理之后加入训练之后,对训练数据过拟合了,也没能在提高评分。(似乎一些评分高得使用了fastai这个库)
总结
通过这个案例学到了一些对数据处理的思路和pandas中的函数。
比如对年龄的空值,使用0填充空值的效果未必会很好,可以使用平均值和中值,其他该类型的数据也可以如此处理。对于类别的空值,可以用最高概率出现的类别代替。
对于一些类别如性别,可以使用pandas中的map()或replace()函数将其换成数值,而不一定非要使用独热编码。
以及对torch中module参数初始化的方式。