1 introduction
确定任务:TALL(Temporal Activity Localization via Language):基于文本的时间活动定位,具体来说就是给定给定一个未修剪的视频和一个自然语言查询,目标是确定视频中所描述活动的开始和结束时间。
将视觉和文本特征嵌入到公共空间以获得更好效果,但是这样对齐任务(alignment task)更难了,并且对于提取视觉特征的模型和如何预测开始和结束的位置的高精度方法都不清楚。
为了解决这些问题,设计一个跨膜态处理模块CRTL,CNN提取视频特征,LSTM提取文本特征,对两部分特征进行元素加、乘、全连接的简单的多模态处理。
2 相关工作
Action classification and temporal localization
动作分类和时间定位
Sentence-based image/video retrieval
基于文本的图像/视频检索
Object detection
目标检测
3 模型方法
模型如下图:
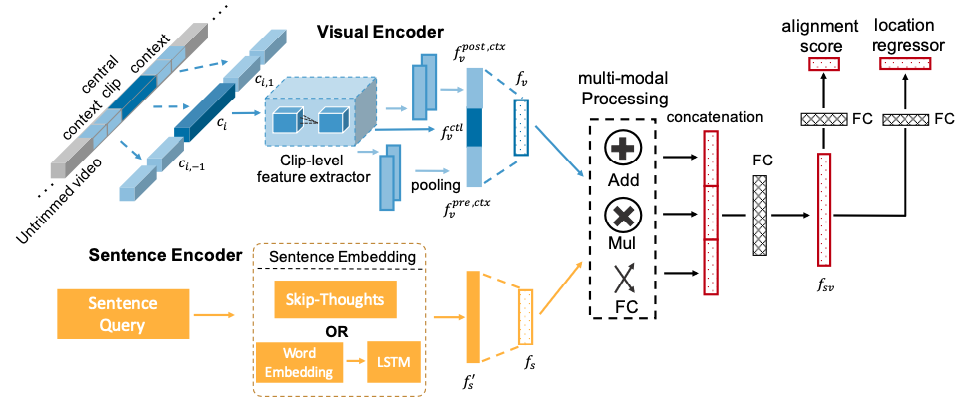
分四个部分:
- 视频特征提取
- 视频方面采用滑动窗口,对视频\(V\)进行分割成一组视频片段(video clips)\(C=\{(c_i,t^s_i,t^e_i)\}^H_{i=1}\),其中H为视频总片段数,\(t^s_i,t^e_i\)分别是一个视频片段\(c_i\)的开始和结束时间。
- 定义视觉编码器为\(F_{vc}(c_i)\),它将一个\(c_i\)映射为特征\(f_v\),其维度为\(d_s\)。在\(F_{vc}(c_i)\),使用特征提取器\(E_v\)提取片段级特征向量,其输入为\(n_f\)帧,输出为维数\(d_v\)的向量。对于一个视频片段\(c_i\),我们认为它自己(作为中心片段)和它周围的片段(作为上下文片段)\(c_{i,q},q∈[-n,n]\),\(j\)是片段的位移,\(n\)是位移边界。
- 我们从每个片段(中心片段和上下文片段)中统一采样\(n_f\)帧。中心片段的特征向量记为\(f^{ctl}_v\)。对于上下文片段,我们使用池化层来计算前上下文特征\(f^{pre}_v = \frac{1}{n}\sum^{-1}_{q=-n} {E(c_{i,q})}\)和\(f^{post}_v = \frac{1}{n}\sum^{n}_{q=1} {E(c_{i,q})}\)。前上下文特征和后上下文特征是分开的,因为活动的结束和开始可能是完全不同的,两者对于时间定位都是至关重要的。将\(f^{ctl}_v\), \(f^{pre}_v\) 和\(f^{post}_v\)串联起来,然后线性变换为维数为\(d_s\)的特征向量\(f_v\),作为片段\(c_i\)的视觉表示。
- 文本特征提取
- \(F_{se}(s_j)\)为文本编码器,将文本描述\(s_j\)转换到维度为\(d_s\)的嵌入空间(跟视频相同)。
- 具体而言,使用句子嵌入提取器\(E_s\)提取句子级嵌入\(f'_s\),然后使用线性变换层将\(f'_s\)映射到维度为\(d_s\)的\(f_s\),与视觉表示\(f_v\)相同。
- 使用LSTM和现成的Skip-thought编码器
- 多模态处理模块
- 输入为\(f_v\)和\(f_s\),其维数都是\(d_s\)
- 使用向量加法,向量乘法,向量拼接,然后一个FC组合两种模式的信息。
- 用公式表示如下:
\(f_{sv}=(f_s\times f_v)||(f_s+f_v)||FC(f_s||f_v)\)
- 时间回归网络
时间定位回归网络以多模态表示 fsv 作为输入,并具有两个兄弟输出层。 第一个输出句子 sj 和视频剪辑 ci 之间的对齐分数 csi,j。 第二个输出剪辑位置回归偏移。 我们设计了两个位置偏移,第一个是参数化偏移:t = (tc,tl),其中tc和tl分别是参数化中心点偏移和长度偏移。 参数化如下:
4 实验
-
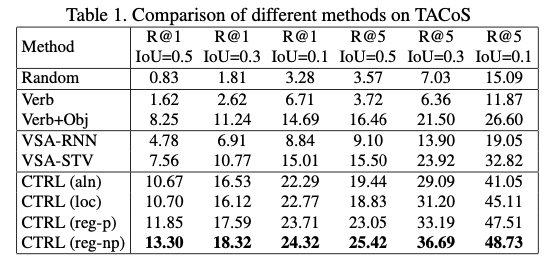
TACoS训练集
-
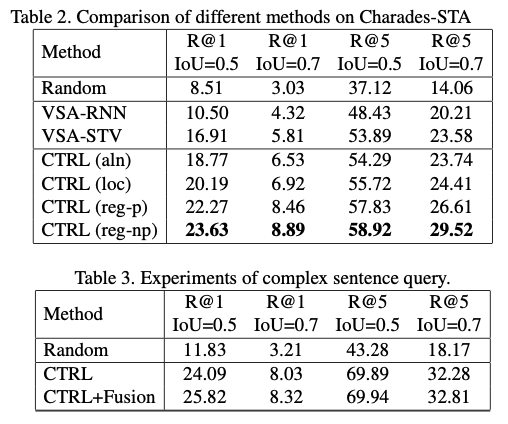
Charades-STA
5 总结
贡献主要定义任务
方法如下:
- 滑动窗口提取视频特征
- word2vec+LSTM提取文本信息
- 向量加、乘、FC拼接融合多模态信息
- 时间回归网络得到预测片段开始和结束
- Localization Activity Language Temporal Querylocalization activity language temporal language kibana query kql 示例language query wql 示例structured language query localization localization simultaneous real-time slamesh api-ms-win-core-localization-l api-ms-win-core-localization-l localization camera-imu-uwb range-focused drift-reduced localization action weakly-supervised completeness localization