概
Self-ask, CoT 的一个拓展.
Compositionality Gap
-
作者首先研究了 compositionality gap, 以 "Who won the Master’s Tournament the year Justin Bieber was born?" 为例, 要回答这个问题, 一般来说, 我们得有能力回答如下的子问题:
- Justin Bieber 出生在 [xxx] 年;
- [xxx] 年 Master's Tournament 的冠军是 [yyy].
-
compositionality gap 指的就是, 倘若 LLM 能够正确回答两个子问题 (即该 LLM 具备正确回答问题所需的背景知识) 的概率, 和正确回答子问题且正确回答的概率的 gap.
-
如下图所示, 有一个比较有意思的现象是, 随着模型的增加, 这个 gap 并没有发生明显的变化 (40% 左右). 这意味着, LLM 的规模的提升, 主要是增加世界知识.
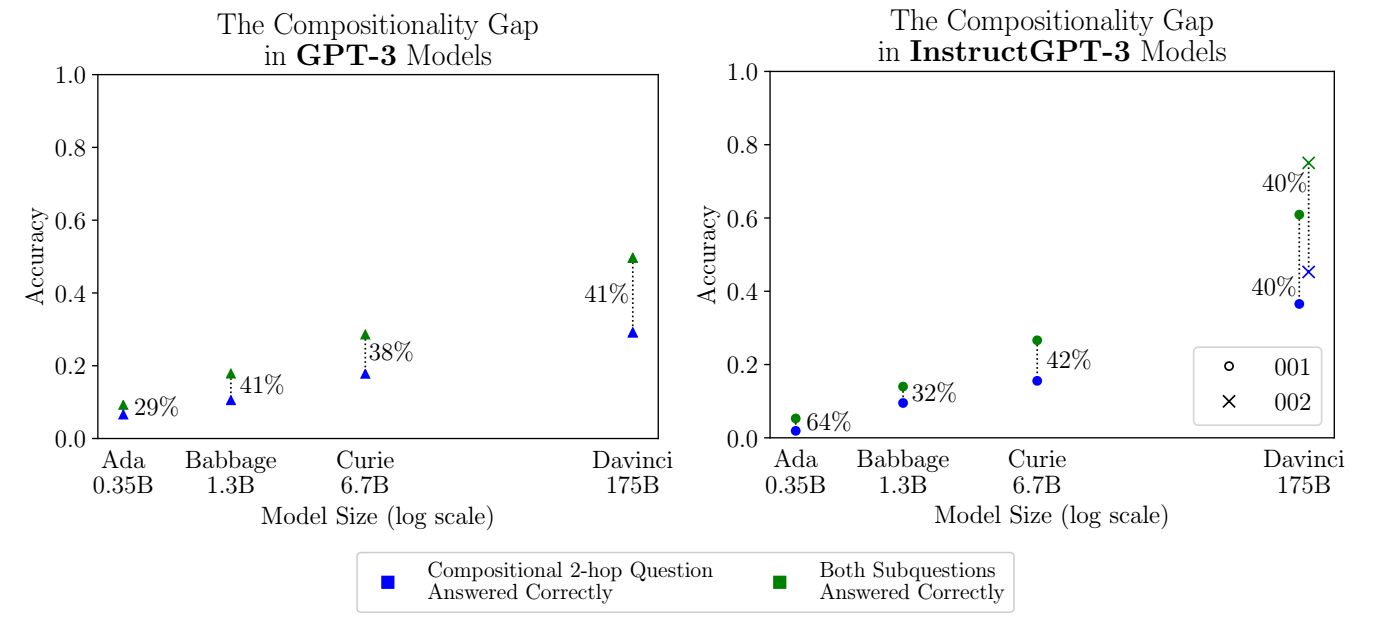
- 进一步的, 作者分析了作者对子问题回答的混淆度 (越大说明 LLM 对回答越不自信). 作者发现, 混淆度在 1.232 到 6.738 的问题的回答正确率为 42.6%, 而混淆度在 1.000 到 1.002 间的回答正确率就有 81.1%. 所以 LLM 对子问题的困惑度越大, 整个问题的预测成功率就越低 (即使所有的子问题的回答是正确的).
Self-ask
- 所以, 如果我们能够提升 LLM 对每个子问题的自信程度, 那么最终的性能就会有提升. 不像以往的 CoT, 作者希望 LLM 自己提出问题 (若感觉对这部分不是很自信):

- 甚至, 每一次提出子问题的时候, 我们可以用搜索引擎来帮助提供更多的信息:

代码
[official]
- Compositionality Measuring Narrowing Language Modelscompositionality measuring narrowing language foundation efficient language models few-shot language learners models language few-shot learners models reasoning language towards models language controlling guidance models zero-shot reasoners language models evaluation holistic language models human-level engineers language models language programming prompting models