1 例子:运行非并行版mrsequential.go
运行一下
cd ~/6.5840
cd src/main
go build -buildmode=plugin ../mrapps/wc.go
rm mr-out*
go run mrsequential.go wc.so pg*.txt
more mr-out-0
运行结果

2 工作
2.1 改哪些
main/mrcoordinator.go和main/mrworker.go不能修改
我们只需要修改mr/coordinator.go, mr/worker.go, and mr/rpc.go
2.2 命令行运行方法
首先确保word-count插件被重新构建
go build -buildmode=plugin ../mrapps/wc.go
在main文件夹中,运行coordinator.go(pg-*.txt是mrcoordinator.go的参数,作为输入文件。每个文件对应一个“split”,作为对于一个Map的输入)
rm mr-out*
go run mrcoordinator.go pg-*.txt
在一个或多个命令行窗口,运行worker们
go run mrworker.go wc.so
当workers和coordinator完成时,在mr-out-*中查看输出,当完成实验后,我们的输出文件的排序联合起来应该与顺序输出一致,像这样:
$ cat mr-out-* | sort | more
A 509
ABOUT 2
ACT 8
...
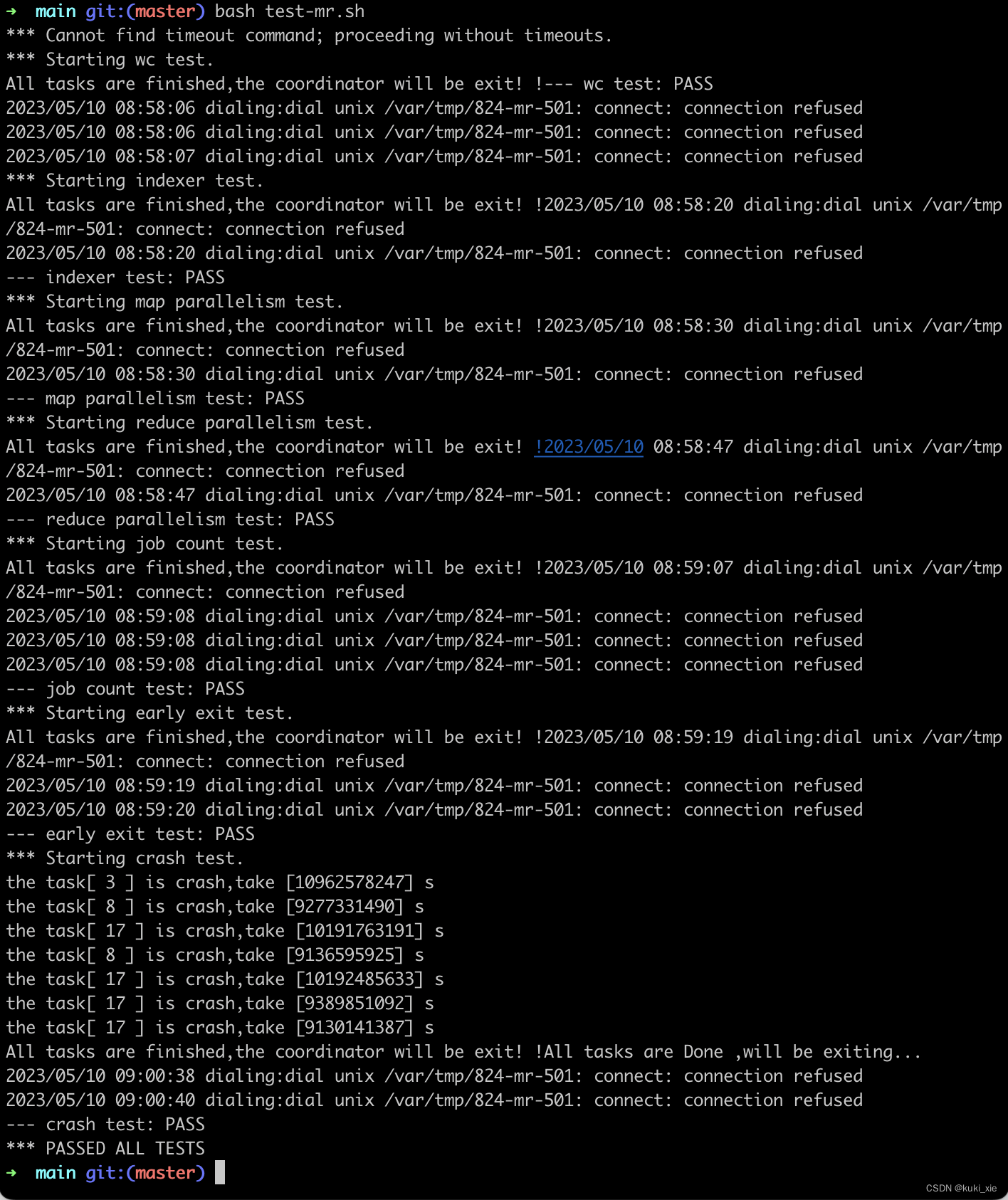
6.824课程为我们提供了一个测试脚本main/test-mr.sh。测试(1)检查wc和indexer。当输入pg-xxx.txt文件,MapReduce程序产生正确的输出。测试还检查(2)我们是否并行运行了Map和Reduce任务。测试还检查(3)我们的实现在workers运行任务崩溃时如果崩溃能否恢复过来。
$ cd ~/6.5840/src/main
$ bash test-mr.sh
*** Starting wc test.
测试脚本期待在命名为mr-out-X文件中看到输出,每一个对应一个reduce任务。一开始mr/coordinator.go和mr/worker.go中的空白实现不能产生这些文件,所以测试会失败。
当你完成工作后,测试脚本应该长这样
$ bash test-mr.sh
*** Starting wc test.
--- wc test: PASS
*** Starting indexer test.
--- indexer test: PASS
*** Starting map parallelism test.
--- map parallelism test: PASS
*** Starting reduce parallelism test.
--- reduce parallelism test: PASS
*** Starting job count test.
--- job count test: PASS
*** Starting early exit test.
--- early exit test: PASS
*** Starting crash test.
--- crash test: PASS
*** PASSED ALL TESTS
$
3 一些规则
- map阶段应该应该将中间key划分成nReduce个reduce任务,其中nReduce是reduce任务的数量(作为main/mrcoordinator.go的参数传递给MakeCoordinator())。每一个map需要创建nReduce中间文件给reduce任务消耗。
- worker实现应该将第X个reduce任务的输出放在文件mr-out-X。
- 一个mr-out-out-X文件需要包含每个Reduce函数输出的一行。这一行需要被以Go的"%v %v"的格式产生,使用key和value进行调用。可以在main/mrsequential.go中注视有"this is the correct format"一行看到。如果你的实现偏离这个格式太远,测试脚本会失败。
- 你可以修改mr/worker.go,mr/coordinator.go和mr/rpc.go。你可以暂时修改其他文件为了测试,但是确保你的代码使用原始版本运行。
- worker应该将中间Map输出放在当前文件夹下的文件中,你的worker可以稍后读取他们作为Reduce任务的输入。
- main/mrcoordinator.go期待mr/coordinator.go实现一个Done()方法,当MapReduce任务已经完成时它将返回true;在那时,mrcoordinator.go将会退出。
- 当工作完成时,worker进程需要退出。一个简单的实现方法是使用call()的返回值:如果worker联系coordinator失败,它可以假设coordinator已经退出因为工作已经完成,所以worker也可以中止。依赖你的设计,你可能也会发现有一个"please exit"伪任务(coordinator可以把它交给worker)将会有帮助。
4 提示
-
Gudiance页有一些关于开发和debug的提示。
-
一个开始的方式是修改
mr/worker.go中的Worker()来发送一个RPC到coordinator请求任务。接着修改coordinator用一个尚未启动的map任务文件名回复。接着修改worker来读取文件并call程序中的Map函数,在mrsequential.go中。 -
程序Map和Reduce函数在运行时借助Go插件包加载,文件名以
.so结尾。 -
如果你修改
mr/文件夹中的任何东西,你将可能需要re-build任何你使用的MapReduce插件,使用类似go build -buildmode=plugin ../mrapps/wc.go -
这个实验依赖workers共享一个文件系统。当所有workers运行在一个机器上时将很简单,但是如果workers运行在不同的机器上时将可能需要一个全局文件系统类似GFS。
-
一个合理的中间文件命名惯例是
mr-X-Y,其中X是Map的任务数字,而Y是reduce任务的数字。 -
worker的map任务代码将需要一种方式存储中间key/value对到文件中用一种方式可以被正确的读回在reduce任务中时。一个可能的方式是使用Go的
enconding/json包。为了写key/value对以JSON格式到一个开放文件enc := json.NewEncoder(file) for _, kv := ... { err := enc.Encode(&kv)并且读这样一个文件回来
dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) } -
你的worker的map部分可以使用
ihash(key)函数(在worker.go)来根据一个给定的key挑选reduce任务。 -
你可以从
mrsequential.go中偷一些代码为了读Map输入的文件,来排序中间key/value对在Map和Reduce之间,并存储Reduce输出到文件中。 -
coordinator,作为一个RPC服务器,将会并行;别忘了给共享数据加锁。
-
使用Go的竞争检测器,借助
go run -race。test-mr.sh有一个注释在起始处告诉你如何运行它带-race。当我们给你的实验评分时,我们将不使用竞争检测器。然而,如果你的代码有竞争,那么存在可能当我们测试它即使没有竞争检测器它会失败。 -
Workers有时会需要等待,等。reduces不能开始直到最后一个map完成。一个可能性是对于workers周期性地请求corrdinator任务,使用
time.Sleep()睡觉在每次请求之间。另一个可能性是对于相关RPC处理器在corrdinator中有一个等待的循环,可以用time.Sleep()或者sync.Cond。Go在自己的线程中为每个RPC运行处理程序,所以一个处理程序正在等待的现实不会阻止coordinator处理其他RPC。 -
coordinator不能可靠地区分崩溃的workers,workers活着但是停止因为一些原因,和workers正在执行但是太慢不能有用。你能做的最好的事就是让coordinator等待一定数量时间,接着放弃,并将任务派给另一个worker。对于这个实验,让coordinator等待10s;之后coordinator需要假设worker已经死了(当然,也许并没有)。
-
如果你选择执行备用任务(Section 3.6),注意我们测试你的代码不会安排额外的任务当workers执行任务时不会崩溃。备份任务应该只在某个相对较长的时间后被安排(例如10s)。
-
为了测试崩溃恢复,你可以使用
mrapps/crash.go程序插件。它随机退出在Map和Reduce函数。 -
为了确保没有人观察到部分写入的文件在崩溃的情况下,MapReduce论文提到了使用临时文件并原子化地重命名一旦完成写入。你可以使用
ioutil.TempFile来创造一个临时文件并且os.Rename来原子化的重命名。 -
test-mr-many.sh运行test-mr.sh多次在一行中,你可能想这样做来发现低概率bug。它使用运行测试的次数当作参数。你不应该同时运行数个test-mr.sh实例因为coordinator将重复使用同一个套接字,导致冲突。 -
Go RPC仅发送名称以大写字母开始的结构字段。子结构也必须有大写的字段名。
-
当调用RPC
call()函数,回复结构应该包含所有默认值。RPC调用应该是这样的reply := SomeType{} call(..., &reply)没有设置任何回复字段在调用前。如果你传输回复结构有非默认字段时,RPC系统可能悄悄地回复错误值。
5 写代码(过程)
5.1 mr/worker.go的修改
5.1.1 改哪些
原始大纲
worker.go
|-KeyValue
|-ihash()
|-Worker()
|-CallExample()
|-call()
修改后的大纲
worker.go
|-KeyValue
|-SortedKey新增 yes
|-ihash()
|-Worker()修改 yes
|-CallExample()
|-GetTask()新增 yes
|-DoMapTask()新增 yes
|-DoReduceTask()新增 yes
|-shuffle()新增 yes
|-call()
|-callDone()新增 yes
5.1.2 CallExample()不用改,call()不用改
5.1.3 KeyValue不用改,新增SortedKey()
一、
这段代码定义了一个名为 KeyValue 的结构体,该结构体包含两个字段:Key 和 Value,分别表示键和对应的值。
另外,还定义了一个名为 SortedKey 的类型,它是 KeyValue 的切片,并且实现了 Len()、Swap() 和 Less() 三个方法。这三个方法是为了使 SortedKey 可以使用 Go 语言内置的 sort 包进行排序。
具体来说,Len() 方法返回 SortedKey 的长度,Swap() 方法用于交换 SortedKey 中两个元素的位置,Less() 方法定义了 SortedKey 的排序规则。在这个例子中,排序规则是按照 KeyValue 的 Key 字段进行升序排序。
通过定义 SortedKey 类型和实现 sort.Interface 接口中的三个方法,可以让 SortedKey 类型具有排序能力,可以方便地对其进行排序操作。
二、
在这个代码中,type 关键字用于定义了一个名为 KeyValue 的结构体类型,该类型包含了两个字段 Key 和 Value,分别用于存储键和值的信息。这个定义使得程序中可以使用 KeyValue 来表示一个包含键和值信息的数据类型,从而方便地在程序中定义和使用这样的数据类型变量。
通过定义一个结构体类型,可以将相关的数据字段组合在一起,并为这些数据字段定义一些方法,从而方便地进行一些操作。在实际的编程过程中,结构体类型经常被用于表示一些复杂的数据结构,如链表、树等。此外,结构体类型还可以用于进行数据的序列化和反序列化,即将结构体类型转化为字节流,或者将字节流转化为结构体类型。
代码中,type 关键字的作用是为一个切片类型 SortedKey 定义了一个别名。通过 type SortedKey []KeyValue 的定义,SortedKey 等价于 []KeyValue 类型,也就是说,可以通过 SortedKey 类型来表示一个 KeyValue 结构体类型的切片。
这个别名的作用在于,可以方便地定义一些针对 SortedKey 类型的操作或方法,而不必暴露 []KeyValue 类型的细节。同时,定义这个别名还可以提高代码的可读性,因为在程序中可以使用 SortedKey 来表示一组按照键排序的 KeyValue 结构体类型的集合,这样更加清晰明了。
在这段代码中,SortedKey 是一个切片类型,而不是一个数组类型。切片是一种动态数组,可以根据需要动态地增加或缩减大小,因此在定义时不需要指定初始大小。切片会在程序运行时动态分配内存,因此可以根据需要动态调整大小。与之不同的是,数组是一种固定大小的数据类型,一旦定义了数组的大小,就不能再进行修改。
需要注意的是,在使用切片时,如果未指定切片的容量,则 Go 语言会根据切片的长度自动推导出切片的容量。如果切片的长度超过了容量,则需要重新分配内存空间,这可能会导致性能下降。因此,在编写程序时,需要根据实际情况合理地设置切片的容量,以免出现性能问题。
三、
-
在 Go 语言中,函数和方法都可以使用多重赋值(multi-value assignment)的方式来交换两个变量的值,这是因为 Go 语言中的赋值语句是原子操作,它们会同时执行,从而保证了交换操作的原子性和正确性。
在上面的代码中,
Swap方法用于交换SortedKey类型变量k中指定位置的两个元素。在方法的函数体中,我们使用多重赋值的方式将k[i]和k[j]交换,将k[j]的值赋给k[i],将k[i]的值赋给k[j]。这样就完成了两个元素的交换操作。需要注意的是,方法中的参数是按值传递的,也就是说,当我们调用
Swap方法时,会将SortedKey类型的变量k拷贝一份传递给方法,因此在方法中对参数的修改不会影响到原始的SortedKey类型变量。不过,在上面的代码中,我们修改的是k中元素的值,而不是k本身的值,因此交换操作是生效的。 -
func (k SortedKey) Len() int是定义了一个方法,它是SortedKey类型的一个接收器(receiver),表示该方法是与SortedKey类型关联的。这个方法的名称是Len,返回类型是一个int类型的值,它的作用是返回SortedKey类型的长度。这个方法是用来实现 Go 语言中的
sort接口中的Len方法,sort接口是用来表示一个可排序的集合的,包含三个方法:Len、Less和Swap。其中,Len方法用于返回集合中元素的个数,Less方法用于判断集合中两个元素的大小关系,Swap方法用于交换集合中两个元素的位置。通过实现这三个方法,我们就可以方便地对集合中的元素进行排序。在上面的代码中,我们定义了一个
SortedKey类型的方法Len,它返回了SortedKey类型的长度。在使用sort包进行排序时,我们可以将SortedKey类型的切片传递给sort.Sort方法,sort.Sort方法会自动调用SortedKey类型的Len、Less和Swap方法,从而实现对SortedKey切片的排序。 -
在 Go 语言中,函数和方法的定义都需要使用
func关键字。它们的区别在于,函数不依赖于任何类型,而方法是与某个类型相关联的。当我们定义一个方法时,需要在函数名前加上一个接收器(receiver),用于指定该方法属于哪个类型。接收器(receiver)是指在函数名前的参数,它指定了方法所属的类型。在上面的例子中,我们定义了一个方法
Len,它的接收器是类型SortedKey。这意味着该方法属于SortedKey类型,我们可以通过SortedKey类型的变量来调用这个方法。使用方法的好处是,可以将方法与其所属的类型相关联,从而提高代码的可读性和可维护性。方法可以访问其所属类型的数据,并且可以在需要的时候修改这些数据。在面向对象编程中,方法是一种重要的概念,它可以帮助我们封装数据和行为,从而更好地组织代码和提高代码的复用性。
-
这段代码是一个方法的定义,方法名为
Len,接收器(receiver)为类型SortedKey,返回值为int类型的数据,表示该方法用于返回SortedKey类型数据的长度。具体来说,方法
Len定义在SortedKey类型上,这个类型是一个结构体切片,其中包含了多个KeyValue类型的元素。当我们调用这个方法时,实际上是在针对SortedKey类型的一个变量进行操作,这个变量可以是一个结构体切片,它包含了多个KeyValue类型的元素。在方法的函数体中,通过
len(k)计算出了SortedKey类型变量k中包含的元素个数,然后将这个计算结果返回给调用者。这个方法的作用是用来支持对SortedKey类型变量的排序操作,例如在使用sort包进行排序时,我们可以将SortedKey类型的切片传递给sort.Sort方法,该方法会自动调用SortedKey类型的Len方法获取切片的长度,并通过Less和Swap方法对切片进行排序。
type KeyValue struct {
Key string
Value string
}
type SortedKey []KeyValue
// Len 重写len,swap,less才能排序
func (k SortedKey) Len() int { return len(k) }
func (k SortedKey) Swap(i, j int) { k[i], k[j] = k[j], k[i] }
func (k SortedKey) Less(i, j int) bool { return k[i].Key < k[j].Key }
5.1.4 修改Worker()
-
这段代码定义了一个
Worker函数,它接受两个参数mapf和reducef,分别是一个函数类型的参数。函数类型指的是具有特定函数签名的函数类型,也就是说,该类型的函数必须接受指定的参数和返回值类型。在本例中,mapf和reducef的类型分别是(string, string) []KeyValue和(string, []string) string,它们分别表示将两个字符串映射为一个KeyValue列表和将一个字符串列表归约为一个字符串。Worker函数的具体实现需要根据具体应用场景来设计,它的作用可能是从输入中读取数据,调用mapf函数将数据转换为KeyValue列表,再调用reducef函数将同一Key对应的Value进行归约,最终输出结果。在本例中,Worker函数的具体实现被省略了,需要根据具体应用场景来实现。在最后注释中,有一个名为
CallExample()的函数被注释了。它可能是用于向协调器(coordinator)发送一个示例的 RPC 请求的函数。在 MapReduce 分布式计算框架中,协调器负责协调和管理整个计算过程,包括将任务分配给工作节点(worker)、监控任务的执行情况、处理任务的输出结果等。
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
keepFlag := true
for keepFlag {
task := GetTask()
switch task.TaskType {
case MapTask:
{
DoMapTask(mapf, &task)
callDone(&task)
}
case WaittingTask:
{
time.Sleep(time.Second * 5)
}
case ReduceTask:
{
time.Sleep(time.Second)
fmt.Println("All tasks are Done, will be exinting...")
keepFlag = false
}
}
}
// uncomment to send the Example RPC to the coordinator.
//CallExample()
time.Sleep(time.Second)
}
5.1.5 新增GetTask()
func GetTask() Task {
args := TaskArgs{}
reply := Task{}
ok := call("Coordinator.PollTask", &args, &reply)
if ok {
} else {
fmt.Println("call failed!")
}
return reply
}
5.1.6 新增DoMapTask()
func DoMapTask(mapf func(string string) []KeyValue, response *Task) {
var intermediate []KeyValue
filename := response.FileSlice[0]
file, err := os.Open(filename)
if err != nil {
log.Fatal("cannot open %v", filename)
}
// 通过io工具包获取conten,作为mapf的参数
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatal("cannot read %v", filename)
}
file.Close()
//map返回一组KV结构体数组
intermediate = mapf(filename, string(content))
// initialize and loop over []KeyValue
rn := response.ReducerNum
// 创建一个长度为nReudce的二维切片
HashedKV := make([][]KeyValue, rn)
for _, kv := range intermediate {
HashedKV[ihash(kv.Key)%rn] = append(HashedKV[ihash(kv.Key)%rn], kv)
}
for i := 0; i < rn; i++ {
oname := "mr-tmp-" + strconv.Itoa(response.TaskId) + "-" + strconv.Itoa(i)
ofile, _ := os.Create(oname)
enc := json.NewEncoder(ofile)
for _, kv := range HashedKV[i] {
err := enc.Encode(kv)
if err != nil {
return
}
}
ofile.Close()
}
}
5.1.7 新增DoReduceTask()
func DoReduceTask(reducef func(string, []string) string, response *Task) {
reduceFileNum := response.TaskId
intermediate := shuffle(response.FileSlice)
dir, _ := os.Getwd()
// tempFile,err := ioutil.TempFile(dir,"mr-tmp-*")
tempFile, err := ioutil.TempFile(dir, "mr-tmp-*")
if err != nil {
log.Fatal("Failed to create temp file", err)
}
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
output := reducef(intermediate[i].Key, values)
fmt.Fprintf(tempFile, "%v %v\n", intermediate[i].Key, output)
i = j
}
tempFile.Close()
//在完全写入后进行重命名
fn := fmt.Sprintf("mr-out-%d", reduceFileNum)
os.Rename(tempFile.Name(), fn)
}
}
5.1.8 新增shuffle()
// 洗牌方法,得到一组排序好的kv数组
func shuffle(files []string) []KeyValue {
var kva []KeyValue
for _, filepath := range files {
file, _ := os.Open(filepath)
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
kva = append(kva, kv)
}
file.Close()
}
sort.Sort(SortedKey(kva))
return kva
}
5.1.9 新增callDone()
func callDone(f *Task) Task {
args := f
reply := Task{}
ok := call("Coordinator.MarkFinished", &args, &reply)
if ok {
} else {
fmt.Printf("call failed!\n")
}
return reply
}
5.2 mr/rpc.go的修改
RPC(Remote Procedure Call)远程过程调用协议,一种通过网络从远程计算机上请求服务,而不需要了解底层网络技术的协议。
5.2.1 改哪些
原始大纲
rpc.go
|-ExampleArgs
|-ExampleReply
|-coordinatorSock()
修改后的大纲
rpc.go
|-ExampleArgs
|-ExampleReply
|-Task 新增 yes
|-TaskArgs 新增 yes
|-TaskType 新增 yes
|-Phase 新增 yes
|-State 新增 yes
|-coordinatorSock()
|-枚举任务类型
|-枚举阶段类型
|-任务状态类型
5.2.2 新增TaskArgs,TaskType,Phase,State
// TaskArgs rpc应该传入的参数,可实际上应该什么都不用传,因为只是worker获取一个任务
type TaskArgs struct{}
//TaskType 对于下方枚举任务的父类型
type TaskType int
// Phase对于分配任务阶段的父类型
type Phase int
// State任务的状态的父类型
type State int
// Cook u
5.2.3 新增Task
// Task worker向coordinator获取task的结构体
type Task struct{
TaskType TaskType // 任务类型判断到底是map还是reduce
TaskId int //任务的id
ReduceNum int // 传入的reducer的数量,用于hash
FileSlice []string //输入文件的切片,map一个文件对应一个文件,reduce是对应多个temp中间值文件
}
5.2.4 新增三个枚举
// 枚举任务的类型
const (
MapTask TaskType = iota
ReduceTask
WaittingTask // Waittingen任务代表此时任务都分发完了,但是任务还没完成,阶段未改变
ExitTask // exit
)
// 枚举阶段的类型
const (
MapPhase Phase = iota //此阶段在分发MapTask
ReducePhase //此阶段在分发ReduceTask
AllDone //此阶段已完成
)
// 任务状态类型
const (
Working State = iota //此阶段在工作
Waitting //此阶段在等待执行
Done //此阶段已经做完
)
5.3 mr/coordinator.go的修改
5.3.1 改哪些
原始大纲
coordinator.go
|-Coordinator
|-Example()
|-server()
|-Done()
|-MakeCoordinator
修改后的大纲
coordinator.go
|-Coordinator 修改 yes
|-TaskMetaInfo 新增 yes
|-TaskMetaHolder 新增 yes
|-MakeCoordinator 修改 yes
|-CrashDetector() 新增 yes
|-makeMapTasks 新增 yes
|-makeReduceTasks 新增 yes
|-selectReduceName 新增 yes
|-acceptMeta 新增 yes
|-PollTask 新增 yes
|-toNextPhase 新增 yes
|-checkTaskDone 新增 yes
|-judgeState 新增 yes
|-generateTaskId 新增 yes
|-Example() 修改 yes
|-server() 不变 yes
|-MarkFinished 新增 yes
|-Done() 修改 yes
6 测试
cd ~/6.5840/src/main
bash test-mr.sh
测试结果,PASS