概
本文在以往的 mini-batch 的快速算法上进行了改进.
符号说明
- \(\mathcal{G} = (\mathcal{V}, \mathbf{A})\), 图, (点集, 邻接矩阵);
- \(\mathbf{M}_{i, *}\), i-th row;
- \(\mathbf{M}_{*, j}\), j-th col;
- \(\tilde{\mathbf{A}} = \mathbf{A + I}\);
- \(\tilde{\mathbf{D}}\), \(\tilde{\mathbf{D}}_{i, i} = \sum_j \tilde{\mathbf{A}}_{i, j}\);
- \(\mathbf{P} = \tilde{\mathbf{D}}^{1/2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1/2}\), normalized Laplacian matrix;
- \(\mathbf{H}^{(l)} = \sigma(\mathbf{Z}^{(l)}), \mathbf{Z}^{(l)} = \mathbf{PH}^{(l-1)} \mathbf{W}^{(l-1)}\);
- \(b\), batch size;
- \(s_{node}\), 采样的 neighbors (per node);
- \(s_{layer}\), 采样的 neighbors (per layer).
Motivation
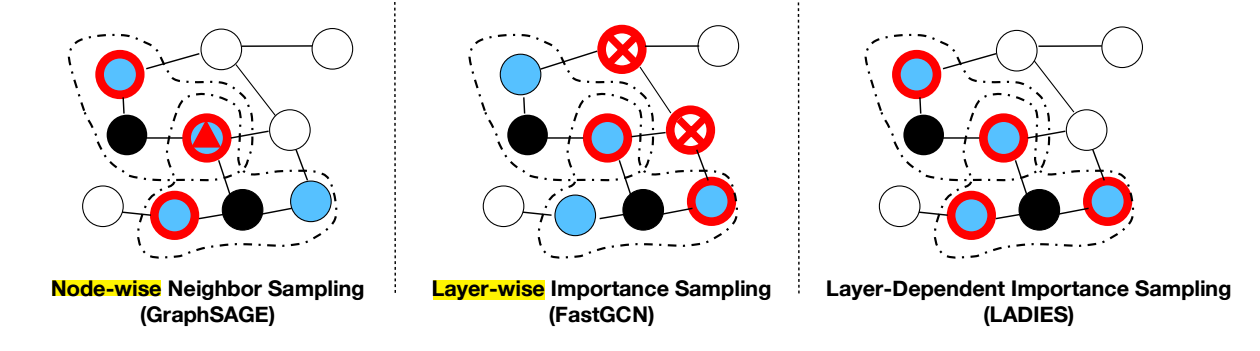
-
Node-wise 的采样, 比如著名的 GraphSAGE, 虽然采样了一批 mini-batch 的点, 但是为了能够进行邻居聚合的操作, 还需要把 mini-batch 的 \(L\)-hop 的点采样出来, 实际上, 只要这样的点的数量是随着 \(L\) 指数增长的.
-
Layer-wise 的采样, 每一层采样是独立的, 对于特别大且特别稀疏的点, 两层采样出来的点可能仅有很少的一些边, 这就使得问题变得更加稀疏了.
-
所以, 本文希望提出一种采样方法能够解决上述的问题.
LADIES
-
首先, 我们可以将 layer-wise 的采样改写成:
\[\tag{1} \frac{1}{s_{l-1}} \sum_{k \in \mathcal{S}^{(l-1)}} \frac{1}{p_k^{(l-1)}} \mathbf{P}_{*, k} \mathbf{H}_{k, *}^{(l-1)}, \]其中 \(\mathcal{S}^{(l-1)}\) 表示根据概率 \(p_k\) 采样得到的大小为 \(|\mathcal{S}^{(l-1)}| = s_{l-1}\) 的点集, 容易发现:
\[\begin{array}{ll} &\mathbb{E}\Bigg\{\frac{1}{s_{l-1}} \sum_{k \in \mathcal{S}^{(l-1)}} \frac{1}{p_k^{(l-1)}} \mathbf{P}_{*, k} \mathbf{H}_{k, *}^{(l-1)} \Bigg\} \\ =&\frac{1}{s_{l-1}} \sum_{k \in \mathcal{V}} \mathbb{E}\Bigg\{ \frac{\text{count}(k)}{p_k^{(l-1)}} \Bigg\} \mathbf{P}_{*, k} \mathbf{H}_{k, *}^{(l-1)} \\ =&\frac{1}{s_{l-1}} \sum_{k \in \mathcal{V}} \frac{s_{l-1} p_k^{(l-1)}}{p_k^{(l-1)}} \mathbf{P}_{*, k} \mathbf{H}_{k, *}^{(l-1)} \\ =&\sum_{k \in \mathcal{V}} \mathbf{P}_{*, k} \mathbf{H}_{k, *}^{(l-1)} \\ =& \mathbf{P} \mathbf{H}^{(l-1)}. \end{array} \]其中 \(\text{count}(k)\) 表示结点 \(k\) 被采样的次数.
-
倘若我们记 \(\mathbf{S}^{(l-1)}\) 为一对角矩阵, 且其对角线元素为:
\[\mathbf{S}_{k, k}^{(l-1)} =\left \{ \begin{array}{ll} \frac{1}{s_{l-1} \cdot p_k^{(l-1)}} & i_k \in \mathcal{S}^{(l-1)}, \\ 0 & \text{otherwise}. \end{array} \right . \] -
则我们可以将 (1) 改写为
\[\mathbf{P}\mathbf{S}^{(l-1)} \mathbf{H}^{(l-1)}. \] -
下面我们令 \(\mathcal{S} = \{i_k\}\), 这里 \(k\) 将表示 \(i_k\) 为 \(\mathcal{S}\) 中的第 \(k\) 个元素, 若令 \(\mathbf{Q}^{(l)} \in \mathbb{R}^{s_l \times |\mathcal{V}|}\) 的每个元素定义为:
\[\mathbf{Q}_{k, s}^{(l)} := \left \{ \begin{array}{ll} 1 & (k, s) = (k, i_{k}^{(l)}) \\ 0 & \text{otherwise}. \end{array} \right . \]那么 \(\mathbf{P}\mathbf{S}^{(l-1)} {\mathbf{Q}^{(l-1)}}^T\)相当于将 \(\mathbf{P}\mathbf{S}^{(l-1)}\) 中的被采样的列挑选出来并按照 \(i_1, i_2, \ldots\) 的顺序进行整理. 而 \(\mathbf{Q}^{(l)} \mathbf{P} \mathbf{S}^{(l-1)} {\mathbf{Q}^{(l-1)}}^T\) 则相当于再从整理好的列中将在 \(l\) 层中被采样的点的 embeddings 选出来.
-
于是乎 LADIES 的整体的流程就是按照如下的方式进行:
\[\tilde{\mathbf{Z}}^{(l)} = \tilde{\mathbf{P}}^{(l-1)} \tilde{\mathbf{H}}^{(l-1)} \mathbf{W}^{(l-1)}, \quad \tilde{\mathbf{H}}^{(l-1)} = \sigma(\tilde{\mathbf{Z}}^{(l-1)}), \]其中 \(\tilde{\mathbf{P}} = \mathbf{Q}^{(l)} \mathbf{P} \mathbf{S}^{(l-1)} {\mathbf{Q}^{(l-1)}}^T\). 每一个 \(\mathbf{S}^{(l)}\) 都是根据 \(p_k\) 采样得到的.
-
到目前为止, 这还只是一个 layer-wise 的采样, 故而依旧带有之前所说的那些问题, 即不同层之间的结点的边可能是非常非常稀疏的.
-
故作者采用 top-down 的方式采样:
-
首先采样 \(l\) 层的结点 \(\mathcal{S}_l\), 然后令
\[\mathcal{V}^{(l-1)} := \cup_{v_i \in \mathcal{S}_l} \mathcal{N}(v_i). \] -
接下来我们我们只在 \(\mathcal{V}^{(l-1)}\) 中采样 \(l-1\) 的结点, 并且依旧是按照重要性采样的方式, 采样概率如下:
\[p_i^{(l-1)} = \frac{\|\mathbf{Q}^{(l)} \mathbf{P}_{*, i}\|_2^2}{\|\mathbf{Q}^{(l)} \mathbf{P}\|_F^2}. \]
-
-
具体算法如下:

代码
- Layer-Dependent Convolutional Importance Dependent Samplinglayer-dependent convolutional importance dependent layer-dependent convolutional importance learning networks importance dependent sampling importance learning skills basic importance automotive diagnostic industry annotation-dependent likelihood-free experience likelihood importance