[SIGIR 2023] Subgraph Search over Neural-Symbolic Graphs
总结
研究的问题
在包含非结构化数据(图像、视频、文本等)的神经符号数据库(neural-symbolic graph datasets)上如何进行高效的神经符号子图匹配(neural-symbolic subgraph matching)
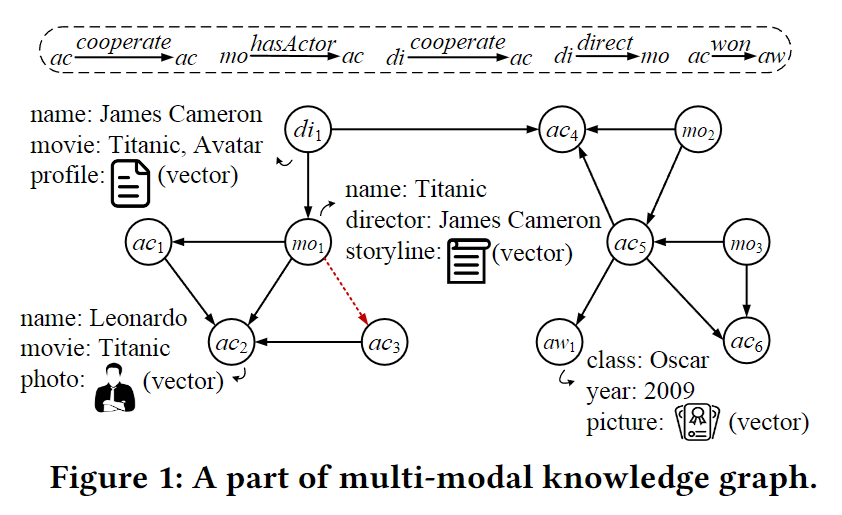
解释一下概念:
neural-symbolic中的neural对应得到是图中的向量。具体来说,包含内容向量和结构向量。前者用于表示非结构化数据,后者则是对指示图进行嵌入操作,得到的每个点的向量表示。
symbolic在图中通常指节点和边的符号标签,以及属性的键值对信息。可以这么理解:图中除了拓扑结构外的其他所有信息以及基于这些信息的运算,统称symbolic。
所以这个本文新提出的NSGD实际上就说知识图谱上增加了非结构化数据的内容嵌入的图。
而研究的问题则是在这样的数据上实现top-k的子图搜索。
具体的问题定义:
给定一个pattern Q和一个NSGD G,其中Q中的每个节点都有一个内容向量表示节点对应的非结构化数据。NSMatch是要在G中找到拓扑结构匹配Q的子图h(Q),再根据每个对应的点的内容相似度得到一个匹配分数S(h(Q)),最后获得Top-K的结果。
模型
子图匹配部分:
- 模式分解:将输入的图杂图pattern Q分解成一组start pattern SQ
- 匹配:对每一个SQ内的pattern sq,利用提出的SMat再G中进行匹配,生成top-k匹配结果。具体来说,SMat:
- 识别sq的中心点和叶节点的候选匹配节点
- 使用神经符号学习模型EJud,利用结构向量判断不存在的边是否应该存在(模型实现不完整图的边补全),提高模型的召回率。
- 利用内容向量相似度得到叶节点的top-h匹配节点。
- 中心节点扫描其邻居,根据匹配分数top-k的星型匹配集。在得到每个sq的top-k后,利用优先级队列的联接算法JoinK,利用这些top-k匹配得到Q的top-k匹配。
这里需要说明的是,JoinK在拼接时,会动态计算分数,并判断是否高于所有上界,从而保证拼接进来的图是连通的。
假设要连接的两个星型子图q1和q2,他们之间的公共节点合集U,仅在q1中出现的点集A和仅在q2中出现的点集B。
q1的打分函数:\(S'(h(q_1)) = S(h(A)) + \beta \times S(h(U))\)
q2的打分函数:\(S'(h(q_2)) = S(h(B)) + (1 - \beta) \times S(h(U))\)
q1的上界:取集合中最后一个元素\(h_{1n_1}\)和q2中第一个元素\(h_{21}\)的得分之和为上界:\(UB_1 = S'(h_{1n_1}) + S'(h_{21})\)
q2的上界同理:\(UB_2 = S'(h_{11}) + S'(h_{2n_2})\)
也就是说,两个图在做拼接时,必须要保证两张图各自的公共部分分数和私有部分分数的加权和要比该图的最低分和另一张图最高分之和要大。
文章认为,只要保证分数高于上界就能保证连通,但并没有给出实际的证明。
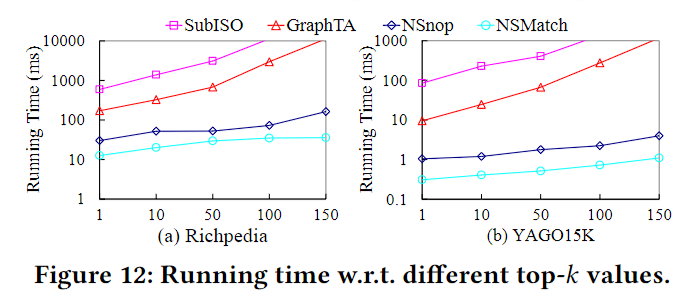
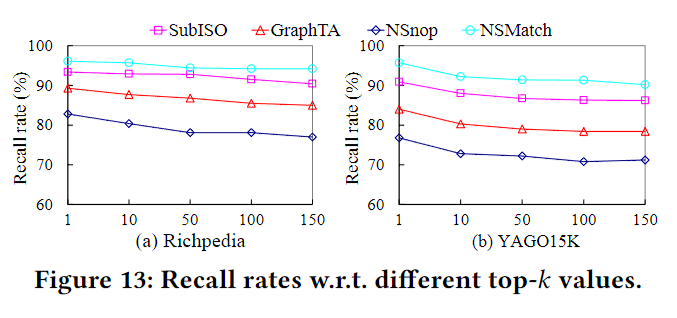
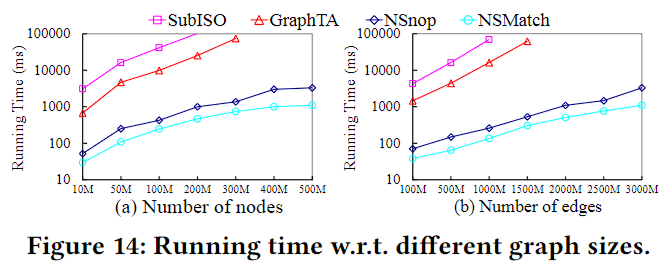
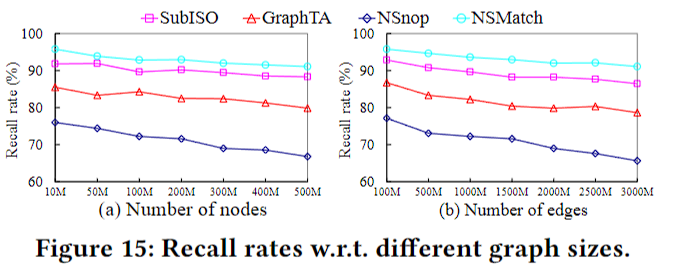
实验
文中没有提到数据集的ground truth是如何获取的,精度的指标是top-k的匹配数量和k的比值,其他实验则只是测试效率。对于纯子图同构算法,会给它套一个计算分数的部分,好得出top-k
数据集
使用三组数据集:
IMGpedia拥有502M个点3119M条边,14.8M张图。
Richpedia中有3.1M个点,119.7M条边,2.9M张图。
YAGO15K中包含15.2M个点,112.9M条边和11.2M张图。
所有的图都以及用SOTA的模型转为了128维的特征。
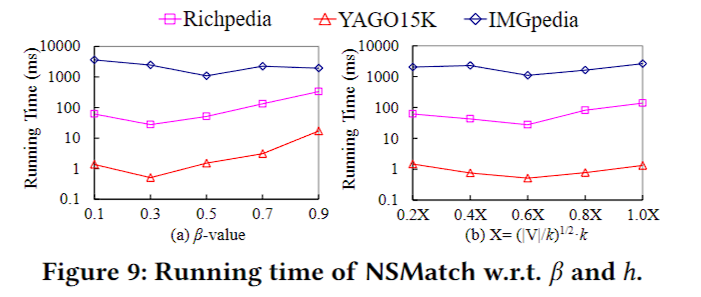
这部分实验是统计了不同的\(\beta\)(上界中的超参)和\(h\)(匹配top-h个点时的超参)对效率的影响。
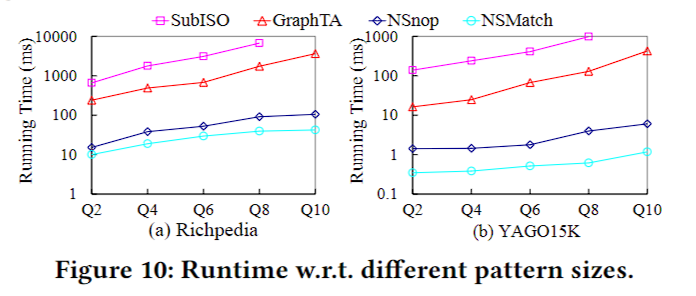
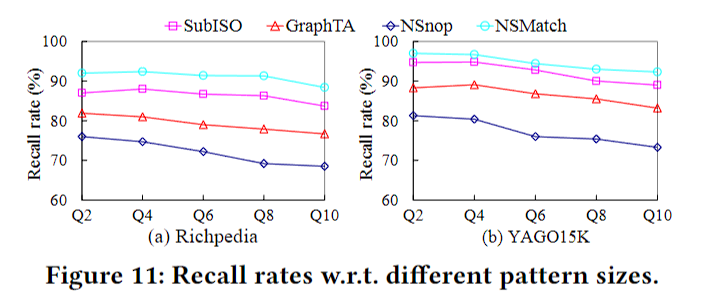
唯一一个精度实验,依然是不知道ground truth是怎么来的。
此外,文中说SubISO是现在最好的子图同构算法,会用他来找出所有的matches,再用S计算所有matches的分数,返回top-k。问题是,如果已经把所有的都找出来了,依照同样方法算出的top-k理应获得最高分,但不知道为什么最后SubISO的效果并不是最好的。归根结底还是因为不清楚ground truth是怎么来的。