前言
VoxelNeXt是一个采用全稀疏卷积的3D目标检测方法,该方法启发自CenterPoint,将输入点云场景体素化后通过3D稀疏卷积提取3D体素特征,提取的特征经高度压缩后采用2D稀疏卷积Head预测。不同于CenterPoint通过热力图的方式预测各个目标的中心点,VoxelNeXt预测各个目标的query voxel并实现类似的检测与跟踪功能。
论文链接:https://arxiv.org/abs/2303.11301
代码链接:https://github.com/dvlab-research/VoxelNeXt
Motivation
- 早期点云目标检测方法将3D空间中过的稀疏特征转化为2D密集特征再进行特征处理,而稀疏的目标特点使得这样的处理方式造成了计算资源的浪费。
- 一般目标检测方法常采用冗余的多框检测策略,使得对后处理步骤(如NMS)产生需求。
- 通过Lidar扫描生成的点云场景,点云信息通常分布再物体表面而不是物体内部,改变预测策略或许能使方法得到进一步提升。
Core Idea
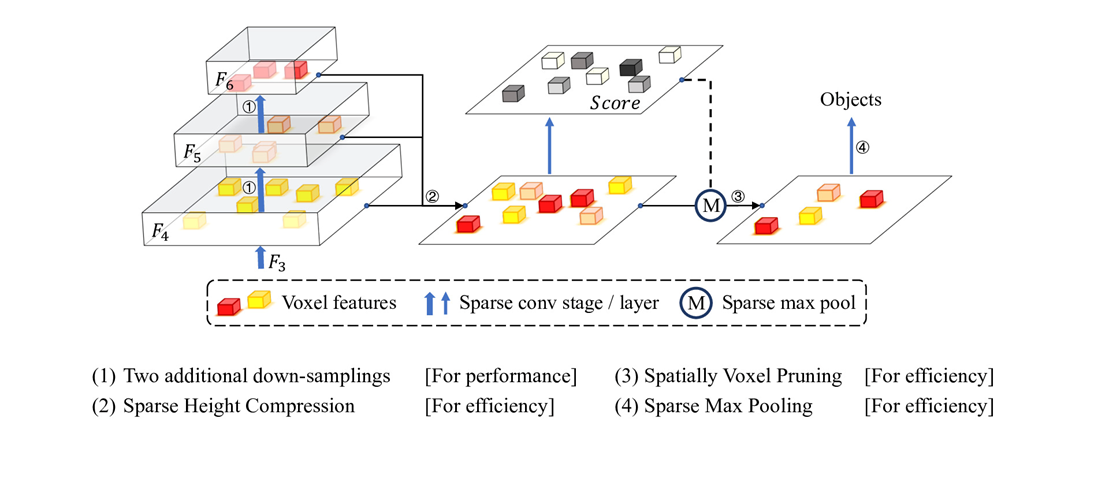
VoxelNeXt有四项重要的改进部分,首先在Backbone上增加了降采样的稀疏卷积层,与之前的相关工作对比,实验中发现该操作可以扩大感受野。对比于扩大卷积核而言,增加稀疏卷积层不会造成推理速度的大幅下降并能提升表现。

图中3x3x3的卷积核通过额外增加两层步长为16,32的稀疏卷积层之后,与改变为5x5x5的卷积核方法对比,仅增加了一点延迟但是性能提升优秀,可视化后也能看到感受野实际上得到了扩大。
VoxelNeXt取出了后三层的特征,并在F4层面上进行了特征与voxel位置的对齐并进行合并,详细公式参看原论文。

作者认为2D的稀疏特征在目标预测上已经足够有效,因此打算去掉Z轴采用2D的稀疏卷积继续处理。以往将特征转化为鸟瞰图通常会让同一z轴上的特征进行concat操作,而VoxelNeXt则是让特征直接相加,这样特征的维度不会大幅度增加进一步降低了计算量。
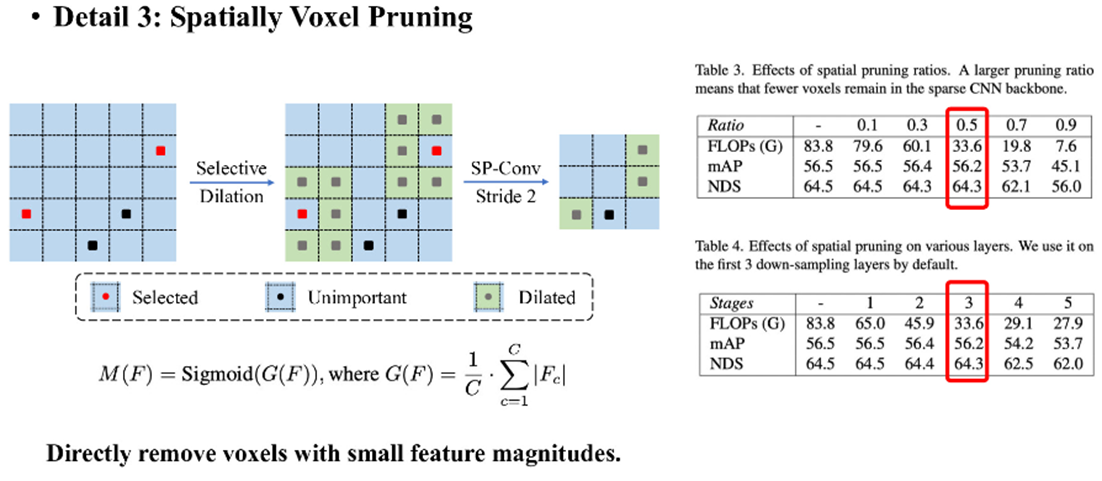
因为3D场景中可能存在的大量背景点对预测帮助较少,因此可将一些特征数值较小的voxel进行修建。该步骤论文描述中在降采样部分开始实行。
spconv在实际运行降采样的时候会将每个有值样本扩大至卷积核大小,VoxelNeXt则只会将大于阈值的voxel进行扩大,将voxel中的特征按特征维度相加取平均后再经过sigmoid映射至0-1。
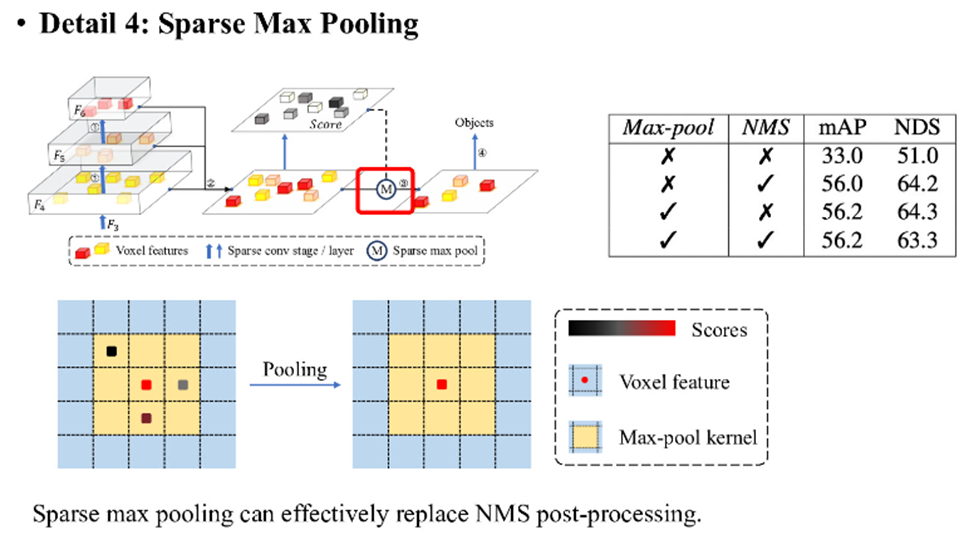
模型训练完毕在预测流程中,作者会采取稀疏最大池化操作,即逐个类别的,只在有值的地方进行最大池化,被移除的特征将不会参与后续bbox的预测。该操作作者认为能取代NMS,从而为模型进行加速。
Others
VoxelNeXt的网络模式最终提出了query voxel的概念用于取代中心点。CenterPoint提出的tracking方法同样能在VoxelNeXt中沿用。在论文给出的表现上query voxel更优秀,作者认为其原因在于query voxel在预测中的相对位置更为稳定。
作者对query voxel可视化后发现它们往往在目标框的边沿上甚至是目标框之外(行人类)这与lidar点云往往位于目标表面的特点相契合。
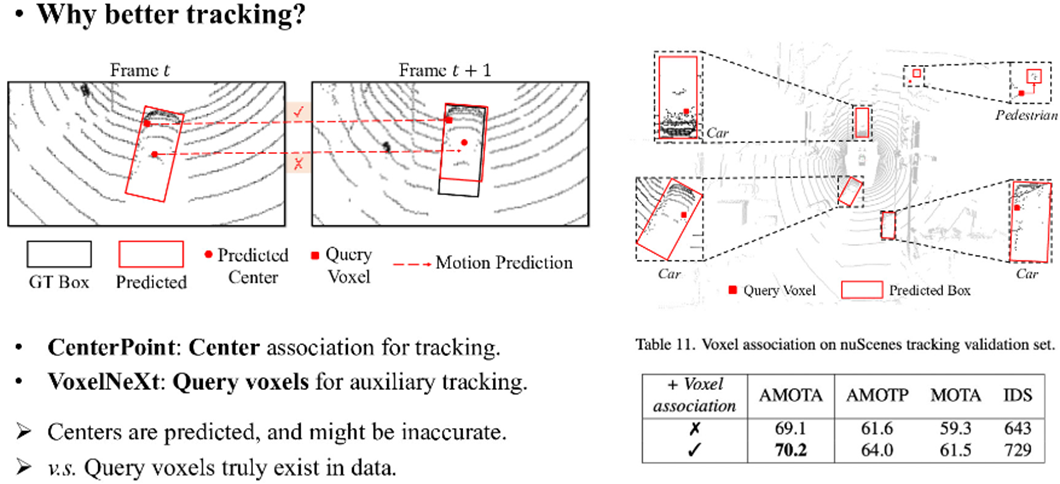
思考:随着目标的接近,点数量会逐渐变大,如果是特征提取能力较弱的backbone,query voxel的变动可能会比较大,这可能是需要改进的地方。
参考
- [1] VoxelNeXt作者对于该论文的解读
- [2] CenterPoint