增量analyticdb flink hudi
Apache Flink目录遍历漏洞复现CVE-2020-17519
# Apache Flink目录遍历漏洞复现CVE-2020-17519 ## 前置知识 `Apache Flink:` > Apache Flink 是一个框架和分布式处理引擎,用于在*无边界和有边界*数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计 ......
Amazon EMR Hudi 性能调优——Clustering
随着数据体量的日益增长,人们对 Hudi 的查询性能也提出更多要求,除了 Parquet 存储格式本来的性能优势之外,还希望 Hudi 能够提供更多的性能优化的技术途径,尤其当对 Hudi 表进行高并发的写入,产生了大量的小文件之后,又需要使用 Presto/Trino 对 Hudi 表进行高吞吐的 ......
中电金信:技术实践|Flink多线程实现异构集群的动态负载均衡
导语:Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。本文主要从实际案例入手并结合作者的实践经验,向各位读者分享当应用场景中异构集群无法做到负载均衡时,如何通过Flink的自定义多线程来实现异构集群的动态负载均衡。 ● 1. 前言 ● 2. 出现的问题与解决 ......
【专题】2023母婴行业增量洞察报告PDF合集分享(附原数据表)
原文链接:https://tecdat.cn/?p=33430 我国出生人口数量在2022年为956万人,比去年减少了10%。多种因素影响了这一趋势,包括育龄人口减少、生育观念改变以及婚育年龄推迟。然而,与此同时,由于母婴人群消费水平不断提高,以及精细化喂养逐渐成为育儿的主流方式,我国母婴市场产业规 ......
图加速数据湖分析-GeaFlow和Apache Hudi集成
# 表模型现状与问题 关系模型自1970年由埃德加·科德提出来以后被广泛应用于数据库和数仓等数据处理系统的数据建模。关系模型以表作为基本的数据结构来定义数据模型,表为二维数据结构,本身缺乏关系的表达能力,关系的运算通过Join关联运算来处理。表模型简单且易于理解,在关系模型中被广泛使用。 随着互联网 ......
史上最全Flink面试题,高薪必备,大数据面试宝典
文章很长,且持续更新,建议收藏起来,慢慢读 为您奉上珍贵的学习资源 : 免费赠送 :[**《尼恩Java面试宝典》**](https://www. ......
flink-cdc同步mysql数据到elasticsearch
1,什么是cdc CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 2,fli ......
Flink源码解析(二)——Flink流计算应用执行环境解析
在Flink应用执行过程中会涉及到3个主要的执行环境变量,分别为StreamExecutionEnvironment、Environment、RuntimeContext。它们的作用层次、作用时机、作用范围各不相同。3种环境对象的关系如下图: 下面分别介绍3种环境对象的细节信息。 一、StreamE ......
使用 rsync 增量同步备份文件
rsync 全名 Remote Sync,是类 UNIX 系统下的数据镜像备份工具。可以方便的实现本地,远程备份,rsync 提供了丰富的选项来控制其行为。rsync 优于其他工具的重要一点就是支持增量备份。 > rsync - a fast, versatile, remote (and loca ......
XtraBackup数据备份与恢复(全部、增量、差异)
# XtraBackup数据备份与恢复(全部、增量、差异) ## 前言 ### 1.XtraBackup介绍 Percona-xtrabackup是 Percona公司开发的一个用于MySQL数据库物理热备的备份工具,支持MySQL、Percona server和MariaDB,开源免费,是目前较为 ......
Flink源码解析(零)——源码解析系列随笔说明
00、博主仅是数据开发及数仓开发工程师,出于提升自身对Flink系统原理掌握考虑,自愿花费精力整理源码解析系列随笔,并非专业Flink系统开发人员,在源码解析过程中出现非专业行为望见谅。希望Flink系统开发专业人员多提意见,不胜感激。 01、Flink源码解析系列随笔主要基于Flink 1.17. ......
DG 修复(增量备份) (Doc ID 1531031.1)
APPLIES TO: Oracle Database - Enterprise Edition - Version 10.2.0.1 to 11.2.0.3 [Release 10.2 to 11.2]Oracle Database - Enterprise Edition - Version 1 ......
FLink参数pipeline.operator-chaining介绍
1、当使用flink提交一个任务,没有给算子设置并行度情况下,默认所有算子会chain在一起,整个DAG图只会显示一个算子,虽然有利于数据传输,提高程序性能,但是无法看到数据的输入和疏忽,业绩反压相关指标。 2、在api开发任务中,可以使用disableChaining方法打算operatorCha ......
flink-sql-connector-mongodb-cdc和flink-connector-mongodb-cdc的区别是什么
flink-sql-connector-mongodb-cdc 和 flink-connector-mongodb-cdc 都是 Flink 的 MongoDB CDC(Change Data Capture)连接器,用于从 MongoDB 数据库中捕获变化数据并将其传递给 Flink 进行实时处理 ......
Flink 容错机制 保存点和检查点
Flink检查点常用配置: //配置检查点 env.enableCheckpointing(180000); // 开启checkpoint 每180000ms 一次 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(50000);// ......
三色标记、原始快照、增量更新相关
#### 三色标记遍历过程(其实就是一个bfs的过程) 假设现在有白、灰、黑三个集合(表示当前对象的颜色),其遍历访问过程为: 1. 初始时,所有对象都在白色集合中; 2. 将GCRoots直接引用到的对象挪到灰色集合中; 3. 从灰色集合中获取对象: 1. 将本对象引用到的其他对象全部挪到灰色集合 ......
oracle imp增量导入
oracle imp导入可以使用 ignore=y 参数进行增量导入 如果不使用 ignore=y 参数在进行imp导入时,就会对已经存在的表就不会进行导入(会报错并跳过), 如果加上 ignore=y 参数,就会对已经存在的表中没有的记录进行更新,但对已经存在记录不会进行覆盖修改。 ......
阿里云flink操作示例
前期简单查询:(不同版本语法或有不同,当前版本:专有云flink1.11) 1、可以先简单定义自己的源表字段(下图test),进行简单查询,确定结果是否输出(结果输出是一直存在的,源表实时新增一条数据,查询结果就会新增一条数据) 备注:以下示例特殊信息写成自己的信息;可定义多个源表 2、定义结果表( ......
【专题】2023母婴行业增量洞察报告PDF合集分享(附原数据表)
报告链接:https://tecdat.cn/?p=33286 原文出处:拓端数据部落公众号 本报告合集主要研究和探讨了中国母婴营养品行业近年来的发展历程、市场现状、消费者行为习惯以及未来的发展趋势。研究的目的是全面解读母婴营养品行业的发展情况、市场现状以及关键营养素,并对母婴营养品的消费人群的营养 ......
(笔记)位置式PID与增量式PID区别浅析
一、PID控制算法 什么是PID PID 控制器以各种形式使用超过了 1 世纪,广泛应用在机械设备、气动设备 和电子设备.在工业应用中PID及其衍生算法是应用最广泛的算法之一,是当之无愧的万能算法 PID 实指“比例 proportional”、“积分 integral”、“微分 derivativ ......
数仓知识07:数据增量更新的几种方式
数仓知识07:数据增量更新的几种方式 1、增量更新的几种方式 增量更新的本质,其实是获取源表中数据变化的情况(增、删、改),然后将源表中发生的变化同步至目标表中。 不同的方式,获取源表中数据变化的情况不一样,受技术的限制、表结构的限制,某些方式可能无法获取到完整的数据变化情况,因此只能适用于特定的场 ......
flink个人理解
1.广播 想把配置streamConfig,广播到流stream中 stream.connect(streamConfig.broadcast(映射描述器msd)); // msd的作用有2(a.泛型, b.获取广播数据context.getBroadcastState(msd)只有通过这个msd才 ......
第三章 Flink 集群搭建
# Flink集群搭建 ```text Flink 可以选择的部署方式有: Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。 我们主要对 Standalone 模式和 Yarn 模式下的 Flink 集群部署进行分析。 我们对sta ......
Flink实时数仓
### 为什么分层? 复杂的问题简单化 避免重复计算 参考大厂做法 ### ods层 1. 采集到ods链路: 用户行为数据(前端埋点):前端埋点=》Nginx=》日志服务器(springboot--落盘成log)=》flume==》kafka:topic_log 业务数据(MySQL):mysql ......
Flink 运行架构
# 第四章 Flink 运行架构 ## 4.1 Yarn 模式任务提交流程 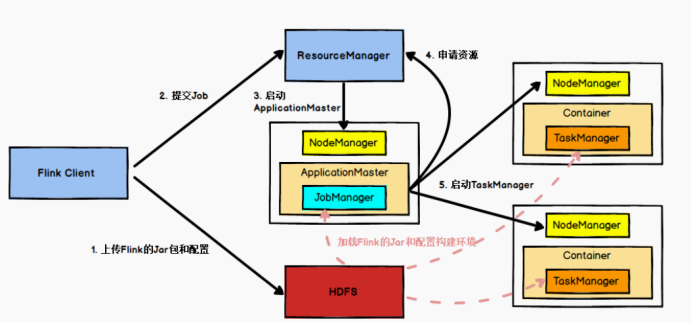 ``` text (1)Fl ......
【Implementation】Vivado增量编译:加速FPGA设计实现
一、Vivado增量编译概述 Vivado增量编译 (Incremental Implementation),是指针对设计中已经完成的部分,仅编译修改的部分,并在这些部分重新生成比特流,以加速设计实现的过程。简单来说,就是只更新那些被修改过的代码,而不是每次都对整个设计进行重新编译。 与传统的完全重 ......
mysql 同步至es logstash 每隔10秒执行一次增量同步
. 在Logstash的config目录下创建mysql-es.conf配置文件,Logstash会根据该配置文件从MySQL中读 取数据并同步到ES库中。 input { jdbc { jdbc_connection_string => "jdbc:mysql://localhost:3306/p ......
全网最详细4W字Flink入门笔记(上)
本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord) 微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5 ......
全网最详细4W字Flink入门笔记(下)
本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord) 微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5 ......