增量analyticdb flink hudi
Flink1.13.6 部署踩坑记录
环境 Hadoop集群是Ambari2.7.5的版本 Flink是1.13.6_2.12的版本 问题记录 1.缺少jar包 报错:ERROR org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Error while running the Flin ......
Flink重启策略
Flink默认重启策略是通过Flink的配置文件设置的flink-conf.yaml,配置参数restart-strategy定义采用的策略。 注意:如果启用了checkpoint并且没有显式配置重启策略,会默认使用fixeddelay策略,最大重试次数为Integer.MAX_VALUE。 1.固 ......
jenkins 自动化部署 flink job
Jenkinsfile def deployIp = '192.168.1.53' def remote = [:] remote.name = deployIp remote.host = deployIp remote.user = 'root' remote.password = LCX_PW ......
Flink 的 checkpoint 机制对比 spark 有什么不同和优势?
spark streaming 的 checkpoint 仅仅是针对 driver 的故障恢复做了数据和元数据的 checkpoint。 而 flink 的checkpoint 机制要复杂很多,它采用的是轻量级的分布式快照,实现了每个算子的快照,及流动中的数据的快照。 ......
kettle和Flink做ETL的区别
Kettle和Flink都可以用于ETL(抽取、转换和加载)处理,但它们有一些不同之处。 Kettle是一款基于图形化界面的ETL工具,可以通过拖放组件的方式来设计和构建ETL流程。它提供了大量的内置组件和步骤,可以用于处理各种数据源和格式。Kettle的优点是易于使用和学习,适合于小型数据处理任务 ......
聊聊Flink必知必会(二)
### Checkpoint与Barrier Flink是一个有状态的流处理框架,因此需要对状态做持久化,Flink定期保存状态数据到存储空间上,故障发生后从之前的备份中恢复,这个过程被称为Checkpoint机制。而Checkpoint为Flink提供了Exactly-Once的投递保障。 流处理 ......
flink 源代码启动
Flink源码编译启动 背景纯小白新手入门flink,由于自身基础差底子薄,启动个源码各种查资料找资源,终于启动好了 值得记录一下,本文源码启动是基于idea+jdk8+maven在windows上启动flink1.16源码。 (1)下载源码源码地址:https://github.com/apach ......
Apache Hudi 初步了解
(一)背景 Hudi 是 Uber 主导开发的开源数据湖框架。所以大部分的出发点都来源于 Uber 自身场景,比如司机数据和乘客数据通过订单 Id 来做 Join 等。在 Hudi 过去的使用场景里,和大部分公司的架构类似,采用批式和流式共存的 Lambda 架构,我们先从 延迟,数据完整度还有成本 ......
聊聊Flink的必知必会(一)
Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 ......
实例讲解Flink 流处理程序编程模型
摘要:在深入了解 Flink 实时数据处理程序的开发之前,先通过一个简单示例来了解使用 Flink 的 DataStream API 构建有状态流应用程序的过程。 本文分享自华为云社区《Flink 实例:Flink 流处理程序编程模型》,作者:TiAmoZhang 。 在深入了解 Flink 实时数 ......
推荐一款比Flink CDC更好用的免费CDC工具
很多中大型企业都希望选择一款足够轻量好用的CDC工具,而且最好是小白用户都能使用的CDC工具,今天就推荐一款小白都能安装并立即使用的CDC工具给大家。 CDC(Change Data Capture)是一种用于捕获和传递数据库实时变更的技术。它允许您实时地监测和捕获数据库中的数据变化,并将这些变化以 ......
Flink - 概述
官网:https://flink.apache.org/ Flink 是什么 为什么选择Flink 流处理的应用场景 Flink的特点 Flink 是什么 是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能。 是一个框架和分布式处理引擎,用于对无界和有界数 ......
Flink的几种Join总结
# Regular join组 第一种: left join 流任务中,只要left的流数据到了,就输出。如果右边流没有到,输出 [L,NULL];如果右边流到了,输出 [L, R] 第二种: right join 流任务中,只要right的流数据到了,就输出。如果左边流没有到,输出 [NULL,R ......
flink源码分析--RPC通信过程分析
flink的通信框架基于akka,但是不懂akka也关系不大。 首先介绍几个概念,大家记住名字和对应的作用: xxxGateway:在flink中就是一个用来告诉调用者,xxx具有哪些方法可以调用的一个接口类。比如JobMasterGateway就是用来告诉所有需要调用JobMaster的用户,我J ......
flink双流join底层如何实现的
Flink是一个分布式流处理框架,它提供了丰富的操作符来处理流数据。双流(join)操作是其中一个常用的操作,用于将两个流的数据按照指定的条件进行关联。Flink的底层实现使用了一种称为“流的连接”(stream co-processing)的技术。 在Flink中,双流(join)操作通过以下步骤 ......
flink双流join时间窗口过大导致的问题
当Flink双流(join)操作的时间窗口过大时,可能会导致以下问题: 1. 内存消耗:时间窗口大小直接影响Flink系统的内存消耗。较大的时间窗口会导致需要维护更多的状态数据,从而占用更多的内存资源。 2. 延迟增加:大时间窗口可能会导致延迟增加。如果窗口的大小超过了数据流的延迟,那么在触发窗口计 ......
flink的双流join的2个流必须都是滑动窗口吗
不,Flink的双流(join)操作并不要求两个流都是滑动窗口。在双流(join)操作中,每个流可以使用不同类型的窗口,包括滑动窗口、滚动窗口或其他类型的窗口。 在Flink中,可以对每个输入流分别定义不同的窗口类型和参数,以满足实际的业务需求。只要两个流在关联键上能够匹配,并且窗口定义能够适配,就 ......
flink中的广播流实例
在Flink中,广播流(Broadcast Stream)是一种特殊的数据流类型,用于将一个数据流广播到所有并行任务中,以供每个任务共享和使用。广播流通常用于将静态数据(如维表数据)发送给所有任务,以便任务可以在本地缓存该数据,避免多次访问外部存储系统。 广播流的特点如下: - 广播流只有一个并行度 ......
flink的状态表需要保存多久
Flink的状态表保存的时间可以根据应用程序的需求进行配置。状态表的保留时间取决于两个因素: 1. **状态后端(State Backend)的配置**:Flink支持不同类型的状态后端,如内存、文件系统、RocksDB等。不同的状态后端可以配置不同的状态保留策略。例如,如果使用基于内存的状态后端, ......
flink从检查点恢复时候做什么
当发生故障时,Flink从最近的一致性检查点中恢复任务的状态。以下是从检查点恢复的主要步骤: 1. **加载检查点元数据和状态数据**:Flink首先加载最近一次成功的检查点的元数据和持久化的状态数据。检查点的元数据包含了关于检查点的信息,如检查点ID、生成时间和相关的任务信息等。持久化的状态数据包 ......
使用Redis作为维表输入的Flink示例代码
下面是一个使用Redis作为维表输入的Flink示例代码: ```java import org.apache.flink.api.common.functions.RichFlatMapFunction; import org.apache.flink.api.common.state.MapSt ......
flink的各个算子在收到barrier的时候会做什么
在Flink中,各个算子(算子链中的每个算子)在收到 barrier(检查点屏障)时会执行以下操作: 1. **算子状态快照**:算子会触发对其状态的快照操作,以捕获当前状态的一致性快照。这包括算子的运行时状态、缓冲区或累加器等数据。 2. **处理挂起输入数据**:算子会将收到的 barrier ......
flink中一个多输入的算子如何决定是否可以往下游算子发送barrier
在Flink中,多输入的算子在决定是否可以往下发 barrier 时需要满足以下条件: 1. **输入流的 barrier 对齐**:多输入的算子必须要求所有输入流都处于 barrier 对齐状态,即收到了相同的 barrier。这意味着所有输入流的上游任务都已经收到了相同的 barrier,并向下 ......
Flink CDC
# **第1章 CDC简介** ## 1.1 什么是CDC CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 ## 1 ......
Apache Hudi 1.x 版本重磅功能展望与讨论
Apache Hudi 社区正在对Apache Hudi 1.x版本功能进行讨论,欢迎感兴趣同学参与讨论,PR链接:[https://github.com/apache/hudi/pull/8679/files](https://github.com/apache/hudi/pull/8679/fi ......
Flink中的Window和Time详解
### Window(窗口) Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。 通常来讲,Window是一种可以把无界数据切割为有界数据块的手段 例如,对流中的所有元素进行计 ......
Flink核心API之Table API和SQL
### Table API & SQL 注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现Flink中所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。 Table API和SQL的由来: Flink针对标准的流处理和批处理提供了两种 ......
Flink核心API之DataSet
### DataSet API DataSet API主要可以分为3块来分析:DataSource、Transformation、Sink。 DataSource是程序的数据源输入。 Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap、filt ......
Flink核心API之DataStream
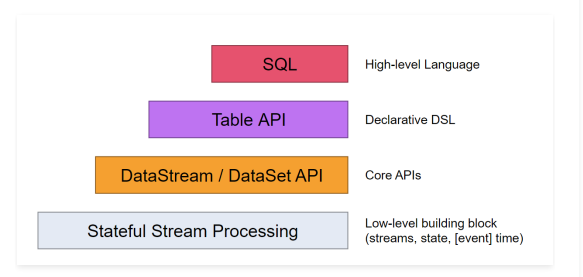 Flink中提供了4种不同层次的API,每种API在简洁和易表达之间有自己的权衡,适用于不同的场景。目前 ......