梯度torch
002-深度学习数学基础(神经网络、梯度下降、损失函数)
0. 前言 人工智能可以归结于一句话:针对特定的任务,找出合适的数学表达式,然后一直优化表达式,直到这个表达式可以用来预测未来。 针对特定的任务: 首先我们需要知道的是,人工智能其实就是为了让计算机看起来像人一样智能,为什么这么说呢?举一个人工智能的例子: 我们人看到一个动物的图片,就可以立刻知道这 ......
在消费级GPU调试LLM的三种方法:梯度检查点,LoRA和量化
LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。 梯度检查点 梯度检查点是一种在神经网络训练过程中使动态计算只存储最小层数的技术。 为了理解这个过程,我们需要了解反向传播是如何执行的,以及 ......
[论文阅读] 颜色迁移-梯度保护颜色迁移
## [论文阅读] 颜色迁移-梯度保护颜色迁移 文章: [[Gradient-Preserving Color Transfer](https://onlinelibrary.wiley.com/doi/10.1111/j.1467-8659.2009.01566.x)], [[代码未公开]()] ......
强化学习——策略梯度之Reinforce
1、策略梯度介绍 相比与DQN,策略梯度方法的区别主要在于,我们对于在某个状态下所采取的动作,并不由一个神经网络来决定,而是由一个策略函数来给出,而这个策略函数的目的,就是使得最终的奖励的累加和最大,这也是训练目标,所以训练会围绕策略函数的梯度来进行。 2、策略函数 以Reinforce算法为例, ......
TabR:检索增强能否让深度学习在表格数据上超过梯度增强模型?
这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强Retrieval Augmented技术,目的是让深度学习在表格数据上超过梯度增强模型。 检索增强一直是NLP中研究的一个方向,但是引入了检索增强的表格深度学习模型在当前实现与非基于检索的模型相比几乎没有改进。所以论文作者提出了一个新的T ......
PyTorch 中的多 GPU 训练和梯度累积作为替代方案
动动发财的小手,点个赞吧! 在[本文](https://towardsdatascience.com/multiple-gpu-training-in-pytorch-and-gradient-accumulation-as-an-alternative-to-it-e578b3fc5b91 "So ......
【d2l】【常见函数】【20】 torch.bmm( )
**局部矩阵乘法** 参考:https://pytorch.org/docs/stable/generated/torch.bmm.html , torch.unsqueeze( )
## torch.squeeze() **压缩大小为1的维度** 参考:https://pytorch.org/docs/stable/generated/torch.squeeze.html  )
**返回一个指定size的张量,元素是0~1之间的随机数** 参考: https://pytorch.org/docs/stable/generated/torch.rand.html 
参考:https://pytorch.org/docs/stable/generated/torch.repeat_interleave.html 
torch.all() 其中的所有项都为True,返回True,反之,返回False >>> import torch >>> a = torch.tensor([[1, 2], [3, 4]]) >>> b = torch.tensor([[1, 2], [3, 4]]) >>> a OUT: t ......
torch的flatten函数
python:flatten()参数详解 这篇博客主要写flatten()作用,及其参数的含义 flatten()是对多维数据的降维函数。 flatten(),默认缺省参数为0,也就是说flatten()和flatte(0)效果一样。 python里的flatten(dim)表示,从第dim个维度开 ......
【d2l】【常见函数】【12】 torch.tensor.repeat( )
**Repeats this tensor along the specified dimensions.** 参考:https://pytorch.org/docs/stable/generated/torch.Tensor.repeat.html 
计算流程如下: 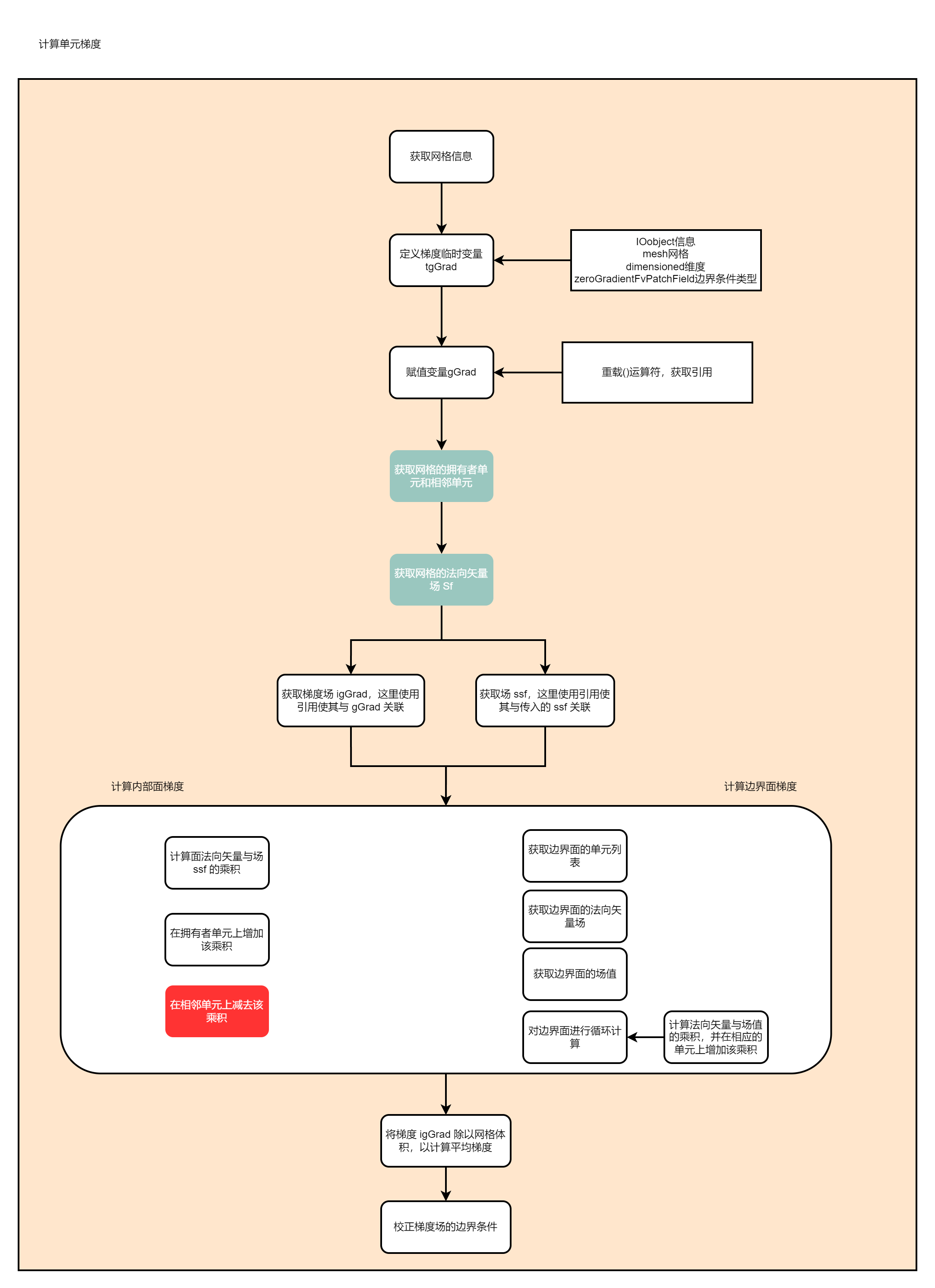 代码如下: ```c++ Foam::fv::gaussGrad::gradf ( c ......
【d2l】【常见函数】【2】 torch.tensor.to(device)
**指定读取张量的设备,如GPU,CPU** 参考:https://blog.csdn.net/shaopeng568/article/details/95205345  在高斯格林公式中,需要用到phi_f,以下是求解phi_f1的步骤(这里只给出phi_f ......
CFD——非结构网格梯度计算(中心法修正)
将f'作为CF(及单元C质心与周围单元质心)的中点 计算流程如下 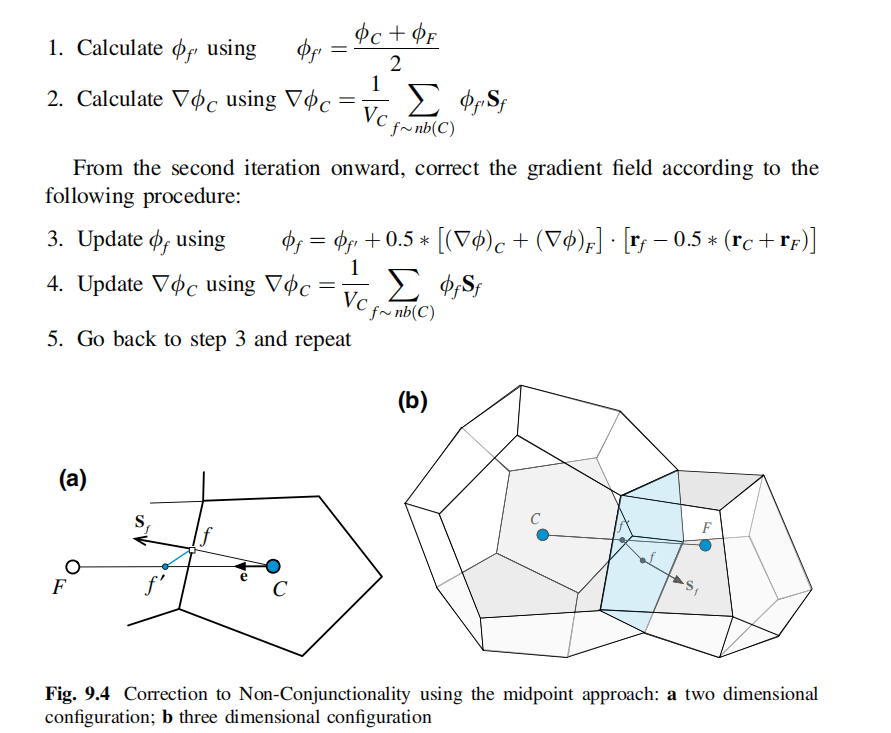 代码实现 ```python # 非 ......
CFD——非结构网格梯度计算(不修正)
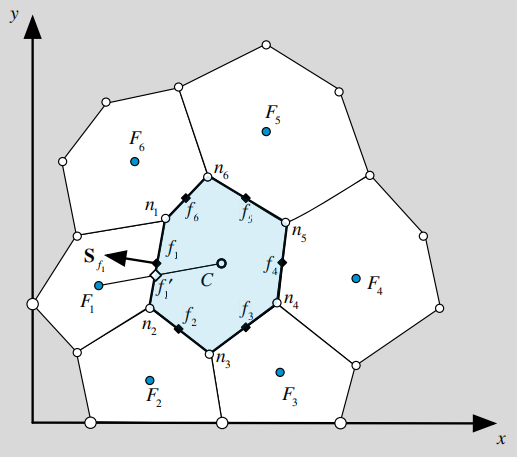 本案例在计算非结构网格的梯度时,不使用修正方法。将直接使用f'处的∅值 计算流程  返回标准正态分布张量
参考:https://pytorch.org/docs/stable/generated/torch.randn.html 
**竖着或者横着拼接矩阵** 参考:https://www.cnblogs.com/JeasonIsCoding/p/10162356.html 参考:https://blog.csdn.net/qian2213762498/article/details/88795848 :注意事项
1。 当执行原地操作时,例如 tensor.add_(x),将会在一个张量上直接修改数据,而不会创建新的张量。由于修改了张量的数据,因此计算图会失效,即计算图中的操作和输入输出关系都会发生变化。这会导致反向传播无法正确计算梯度。因此,PyTorch 禁止在需要梯度计算的张量上执行原地操作。为了解决这 ......
pytorch使用(三)torch.zeros用法
#torch.zeros用法 torch.zeros() 是 PyTorch 中用来创建全 0 张量的函数。用法为 torch.zeros(size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=Fal ......
验证torch和torchvision安装成功
import torchprint("torch_version:",torch.__version__)print("cuda_version:",torch.version.cuda)print("cudnn_version:",torch.backends.cudnn.version())pr ......
机器学习 - Torch-TensorRT 推理加速
# 机器学习 - Torch-TensorRT 推理加速 Torch-TensorRT 作为 TorchScript 的扩展。 它优化并执行兼容的子图,让 PyTorch 执行剩余的图。 PyTorch 全面而灵活的功能集与 Torch-TensorRT 一起使用,解析模型并将优化应用于图的 Ten ......
python代码:基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究
python代码:基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究关键词:DDPG 算法 深度强化学习 电力市场 发电商 竞价 说明文档:完美复现英文文档,可找我看文档 主要内容:代码主要研究的是多个售电公司的竞标以及报价策略,属于电力市场范畴,目前常用博弈论方法寻求电力市场均衡,但是此 ......
PyTorch | torch.save()函数的使用
Pytorch保存模型等相关参数,利用`torch.save()`,以及读取保存之后的文件。 ### 函数信息 ```python torch.save(obj, f, pickle_module=pickle, pickle_protocol=DEFAULT_PROTOCOL,_use_new_z ......
torch中关于cuDNN的一些训练设置
torch.backends.cudnn.enabled = True cuDNN的非确定性算法(NP),等于True时启用,cuDNN设置为使用非确定性算法 torch.backends.cudnn.benchmark = True 再将benchmark设置为true,cuDNN将会自动寻找最适 ......
请介绍感知机模型及其训练算法(梯度下降法)。注意,梯度的推导是必需的。
感知机(Perceptron)是一种二分类的线性分类模型,其基本结构由一个或多个输入节点、一个加权总和和一个激活函数组成。感知机模型的训练算法通常使用梯度下降法。 感知机模型的输入是一个n维向量x=(x₁, x₂, ..., xn),对应于n个特征。每个特征都有一个对应的权重w=(w₁, w₂, . ......
众所周知,梯度下降法是一种基本的优化算法,不能保证全局最优,也不能保证效率。为什么它仍然被广泛应用于深度学习,而不是传统的凸优化算法和粒子群算法
梯度下降法在深度学习中被广泛应用的原因主要有以下几点: 适用性广泛:梯度下降法可以应用于各种深度学习模型,包括神经网络、卷积神经网络、循环神经网络等。而传统的凸优化算法和粒子群算法往往只适用于特定类型的优化问题。 原理简单:梯度下降法的原理相对简单,易于理解和实现。相比之下,传统的凸优化算法和粒子群 ......