title: ViT在DDPM取代UNet(DiT)
banner_img: https://cdn.studyinglover.com/pic/2023/08/b6f940f512488c10b7a1bf40eb242cae.png
index_img: https://cdn.studyinglover.com/pic/2023/08/f68c4f271029a484e97822dbb9fb2569.png
date: 2023-8-20 9:43:00
categories:
- 笔记
tags:
- 文字生成图片
ViT在DDPM取代UNet(DiT)
这篇论文主要是尝试使用ViT取代DDPM中的UNet,叫做Diffusion Transformer-DiT,作者训练了DiT-S、DiT-B、DiT-L 和 DiT-XL四种模型,每种模型的patch取8,4,2, 一共训练了12个模型。
作者探索的完整 DiT 设计空间是补丁大小、变压器块架构和模型大小。
模型第一层是对 sequences of patches 进行操作(就是ViT把图片看成\(16*16\)的的单词之后单词构成的序列) 。
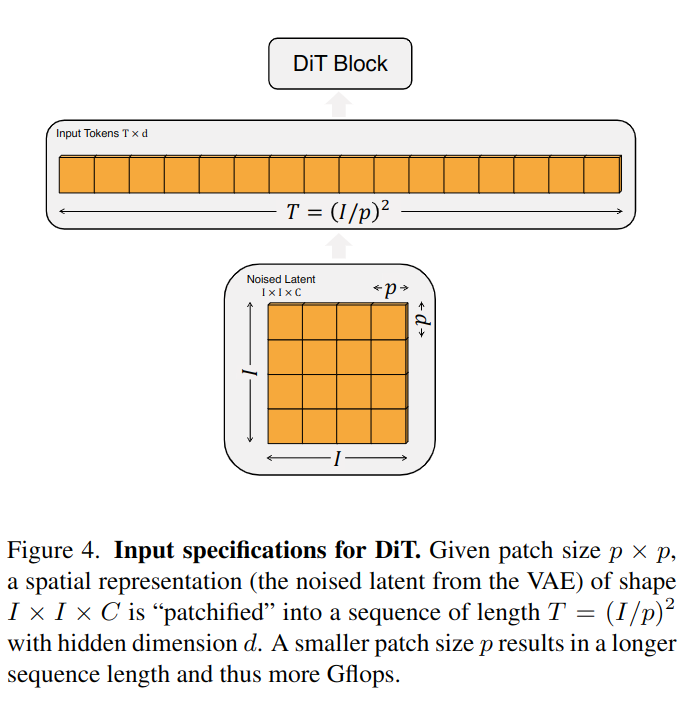
如图所示,给定的patch是\(p\times p\) ,VAE采样出来的噪声大小是\(I\times I\times C\) ,那么patches会变成长度为\(T=(I/\hat{p})^{2}\) 的一个序列,每个patch维度是\(d\) ,位置嵌入用的是sine-cosine。
接下来就是diffusion transformers的设计。
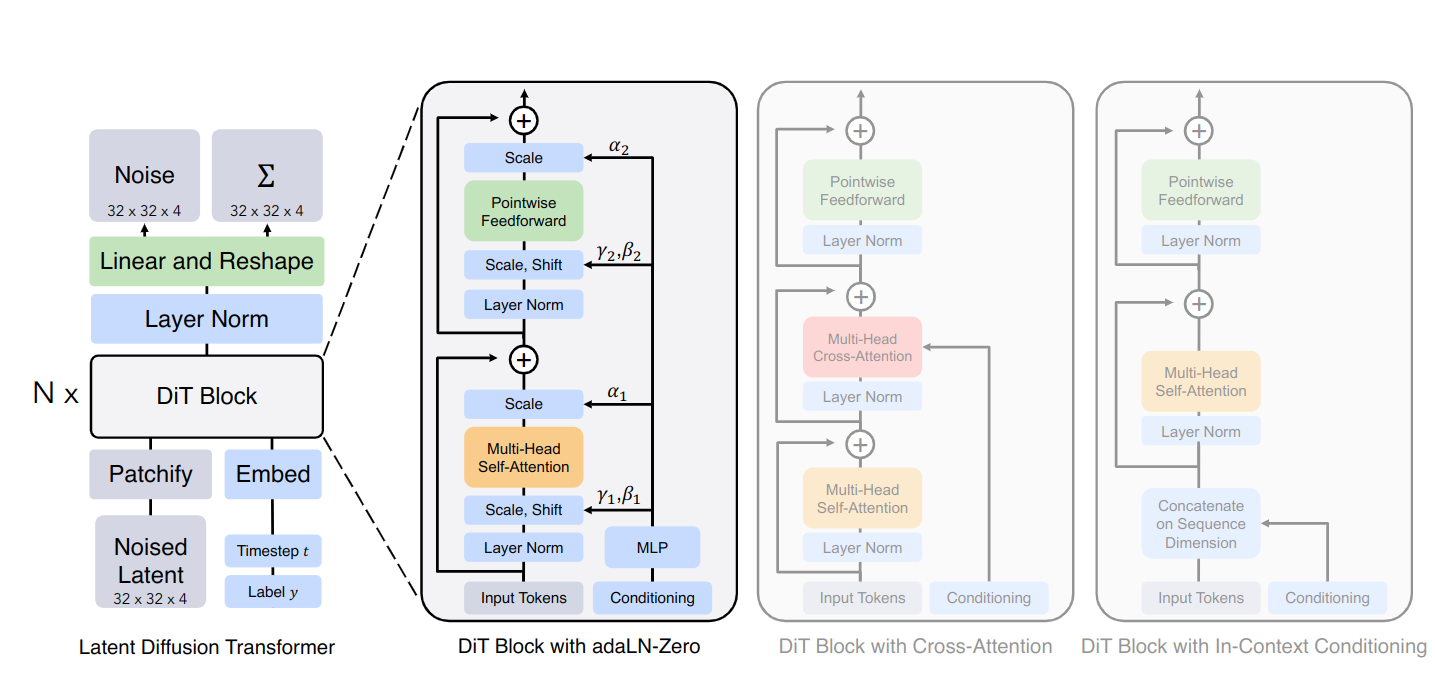
作者提到了一点,就是获取到path序列之后应该在后面加上去噪步数和类别标签,并在最后一个DiT块之后删掉。
在最终的 DiT 块之后,需要将输出解码为噪声预测和对角协方差预测。这两个输出的形状都等于整个模型的输入。作者使用标准线性解码器来做到这一点。如果使用 adaLN 自适应就应用最后一层范数,并将每个标记线性解码为 \(p\times p\times2C\) 张量,其中 \(C\) 是输入到DiT的空间大小。最后,将解码的token重新排列到其原始空间布局中,得到预测的噪声和协方差。