摘要:人工神经网络在一般函数逼近方面很有希望,但由于灾难性遗忘,在非独立或非同分布的数据上训练具有挑战性。经验回放缓冲区(experience replay buffer)是深度强化学习中的一个标准组件,通过将经验存储在一个大的缓冲区中并用于以后的训练,通常用于减少遗忘和提高样本效率。然而,较大的重放缓冲区会导致沉重的内存负担,特别是对于内存容量有限的板载和边缘设备。本文基于深度q网络算法提出了记忆高效的强化学习算法来缓解这一问题。通过将目标q网络中的知识整合到当前q网络中,所提算法减少了遗忘并保持了较高的样本效率。与基线方法相比,所提出算法在基于特征和基于图像的任务中都取得了相当或更好的性能,同时减轻了大型经验回放缓冲区的负担。
1 Introduction
本文基于深度q网络(DQN)算法提出了memory-efficient的强化学习算法。为目标神经网络分配了一个新角色,最初引入该角色是为了稳定训练。在此算法中,目标神经网络扮演着knowledge keeper的角色,并通过consolidation loss(整合损失)帮助在行动价值网络中整合知识。我们还引入了一个调整参数,以平衡学习新知识和记忆过去的知识。通过在基于特征和基于图像环境下的实验,证明了所提出算法在使用比DQN的经验回放缓冲区至少小10倍的经验回放缓冲区时,仍然取得了可比甚至更好的性能。
2 Understanding forgetting from an objective-mismatch perspective
我们首先使用监督学习中的一个简单示例,从客观不匹配的角度阐明灾难性遗忘。
Bt是IID,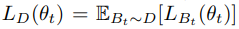
Bt是non-IID,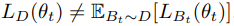
优化真实目标与优化目标之间的不匹配往往导致灾难性遗忘。如果不结合其他技术,当SGD算法用于训练给定非IID数据【IID(如从D中均匀随机抽取Bt)】的神经网络时,极有可能发生灾难性遗忘——优化目标完全是错误的
为了证明客观不匹配如何导致灾难性遗忘,我们提供了一个回归实验
3 Related works on reducing catastrophic forgetting
减少灾难性遗忘的关键是在获取新知识的同时保留过去获得的知识。
3.1 Supervised learning
3.2 Reinforcement learning
在单个强化学习任务中,遗忘问题未得到充分探索和解决,因为该问题被使用大型回放缓冲区掩盖了。本文旨在开发 memory-efficient的单任务强化学习算法,同时通过减少灾难性遗忘实现高样本效率和训练性能。
4 MeDQN: Memory-efficient DQN
4.1 RL Background
4.2 Knowledge consolidation
最初,Hinton等人(2014)提出了蒸馏来有效地在不同的神经网络之间迁移知识。在这里将knowledge consolidation称为蒸馏的特殊情况,它将信息从该网络的旧副本(例如,由θ−参数化的目标网络Qˆ)转移到网络本身(例如,由θ参数化的当前网络Q),从而巩固网络中已经包含的知识。与EWC (Kirkpatrick等人,2017)和SI (Zenke等人,2017)等正则化参数的方法不同,knowledge consolidation直接正则化函数。
形式上,我们将(vanilla)consolidation loss定义如下:
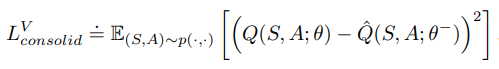
为了保留知识,状态-作用空间应该被p(s,a)充分覆盖,p(s,a)= dπ(s)π(a|s)或p(s,a)= dπ(s)µ(a),本文选择:p(s,a)= dπ(s)µ(a)。然而,p(s, a)的最优形式仍然是一个开放的问题,我们把它留给未来的研究。
综上所述,本工作中使用的consolidation loss如下:
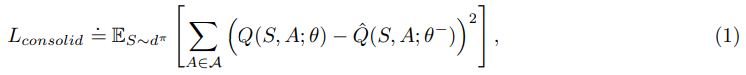
直观上,最小化合并损失可以通过惩罚与Qˆ偏离太多的Q来保存先前学到的知识。通常,我们也可以使用其他损失函数,为了简单起见,我们使用均方误差损失,我们的实验也证明了这是有效的。
给定由过渡τ = (s,a,r,s')组成的mini-batch B,则DQN损耗定义为:
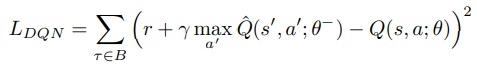
我们将这两种损失结合起来,得到我们算法的最终训练损失:
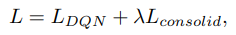
没有引入额外的网络,因为目标网络用于consolidation。
注意:
LDQN帮助Q网络从B中学习新知识,这些知识是从经验回放缓冲区中采样的。
Lconsolid用于通过将信息从Qˆ巩固到Q来保存旧知识。
通过将它们与加权参数λ相结合,我们可以同时平衡学习和保存知识。此外,由于Lconsolid充当函数正则化器,只要函数值Q保持在Qˆ附近,参数θ就可能发生显著变化
4.3 Uniform state sampling
还有一个问题:如何得到dπ(s)?一般来说,很难计算dπ(s)的精确形式,相反,我们使用随机采样。
近似dπ(s)的最简单方法之一是使用S上的均匀分布:
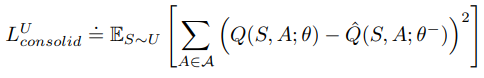
其中U是状态空间S上的均匀分布。
当dπ(s)≤1时,则有
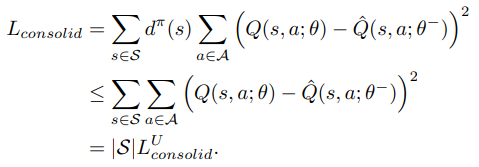
本质上,最小化Lu 可以最小化 Lconsolid的上界。只要Lu足够小,就可以以较低的Lconsolid实现较好的知识固结。在极端情况下,LU = 0会导致Lconsolid = 0。
在实践中,我们可能事先不知道S。为了解决这个问题,我们保持Slow和Shigh分别作为所有观测状态的下界和上界。请注意,sLOW和sHIGH都是与S中的状态具有相同维度的两个状态向量.
最初,设置sLOW =[∞,···,∞]∈rn和sHIGH =[−∞,···,−∞]∈Rn。对于每个新接收到的s∈Rn,我们更新状态界为
在训练过程中,我们从区间[sLOW, shigh]中均匀采样伪状态,以帮助计算consolidation loss
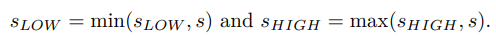
Algorithm 1:MeDQN(U)

将使用均匀状态采样的算法命名为具有均匀状态采样的内存高效DQN,记为MeDQN(U),如算法1所示。
与DQN相比,MeDQN(U)有几个变化:
首先,经验回放缓冲区D非常小(第1行)。在实践中,我们将缓冲区大小设置为小批量大小以应用小批量梯度下降。其次,我们维护状态边界并在每一步更新它们(第7行)。此外,为了从小型回放缓冲区中提取尽可能多的信息,我们使用相同的数据来训练Q函数E次(第13-19行)。在实践中,我们发现较小的E(例如,1-4)就足以表现良好。最后,我们通过在DQN损失中添加一个巩固损失作为最终的训练损失来应用知识巩固(第16-17行)。
4.4 Real state sampling
为了克服统一状态抽样的缺点,我们提出了真实状态抽样
将先前观察到的状态存储在状态回放缓冲区Ds中,并从Ds中采样真实状态以进行知识整合。与均匀采样相比,从状态重放缓冲区采样的状态与Sπ有更大的重叠,是dπ的更好近似。形式上,我们将使用真实状态采样的consolidation loss定义为:
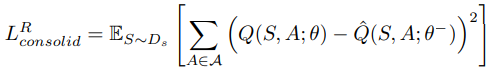
在实践中,我们从经验回放缓冲区D中对状态进行采样。我们将使用真实状态采样的算法命名为具有真实状态采样的memory-efficient DQN,记为MeDQN(R)。算法描述如算法3所示。
与MeDQN(U)类似,我们也使用相同的数据来训练Q函数E次,并通过添加consolidation loss来应用知识巩固。
主要的区别是MeDQN(R)中使用的经验回放缓冲区相对较大,而MeDQN(U)中的经验回放缓冲区非常小(即一个小批量大小)。然而,正如我们接下来要展示的,MeDQN(R)中使用的经验回放缓冲区仍然可以明显小于DQN中使用的经验回放缓冲区。
Algorithm 2:DQN

Algorithm 3:MeDQN(R)
