? 本周任务:
- 了解seq2seq是什么?
- 基于RNN的seq2seq模型如何处理文本/长文本序列?
- seq2seq模型处理长文本序列有哪些难点?
- 基于RNN的seq2seq模型如何结合attention来改善模型效果?
- 可以先尝试着自己编写代码(下周更新)
一、seq2seq是什么
seq2seq(sequence to sequence)是一种常见的NLP模型结构,翻译为“序列到序列”,即:从一个文本序列得到一个新的文本序列。典型的任务有:机器翻译任务,文本摘要任务。
NLP初学者想要充分理解并实现seq2seq模型很不容易。因为,我们需要拆解一系列相关的NLP概念,而这些NLP概念又是是层层递进的,所以想要清晰的对seq2seq模型有一个清晰的认识并不容易。
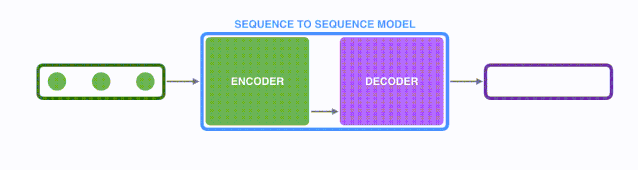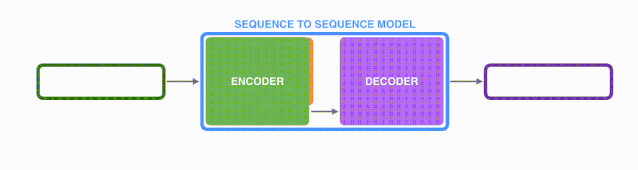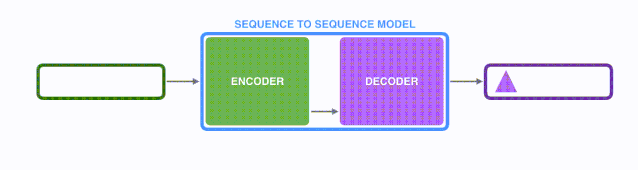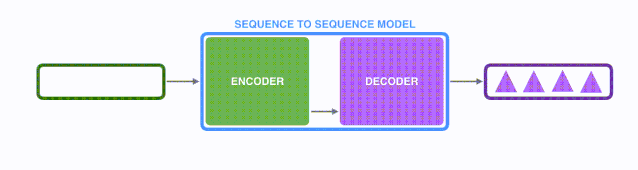
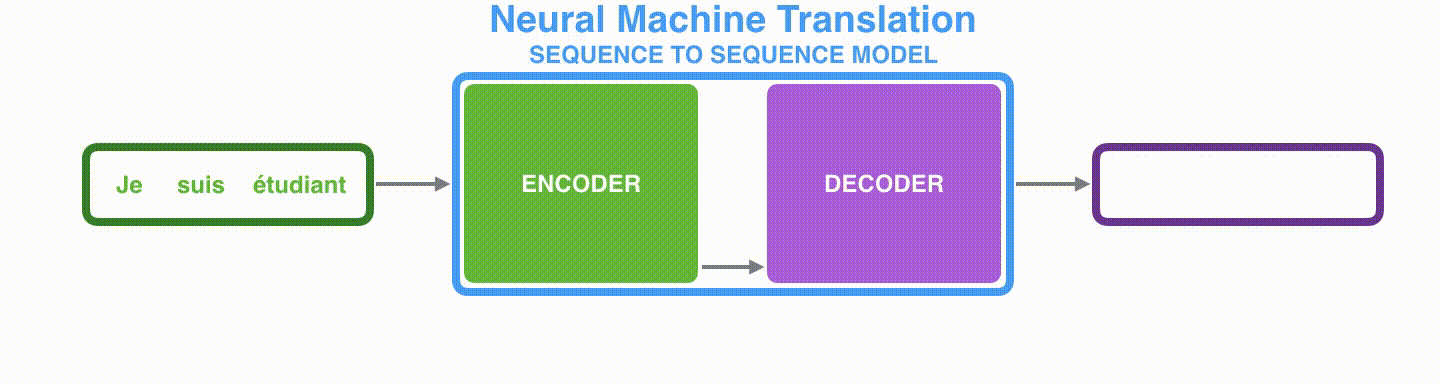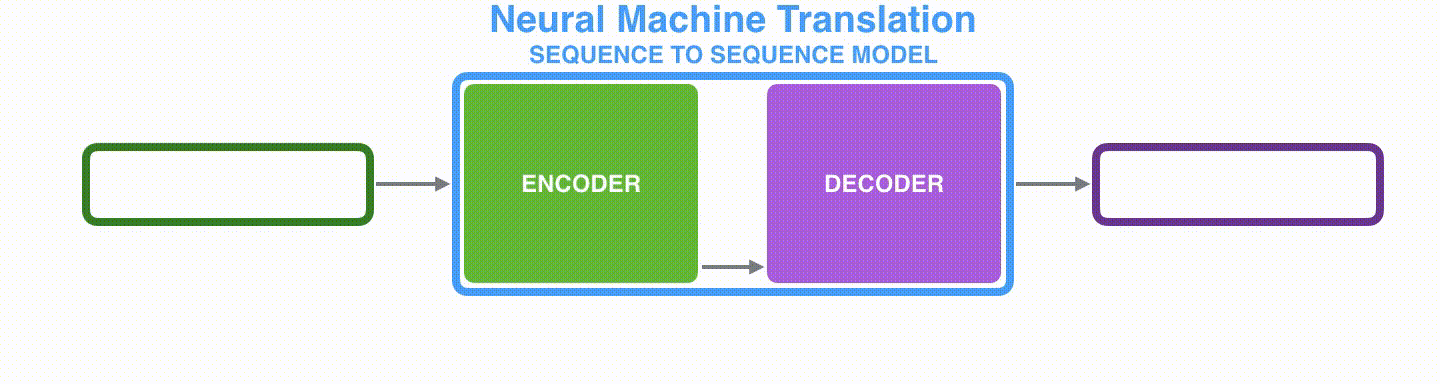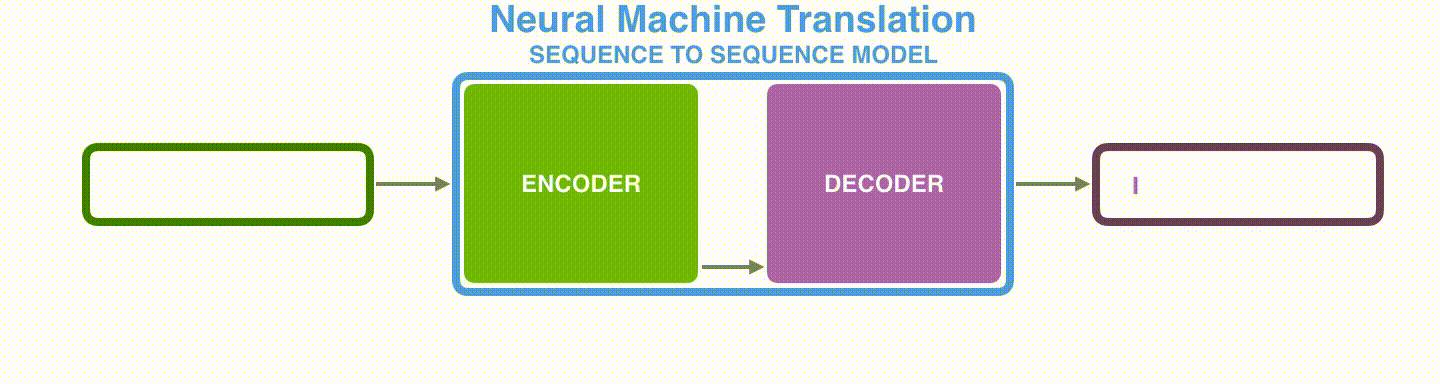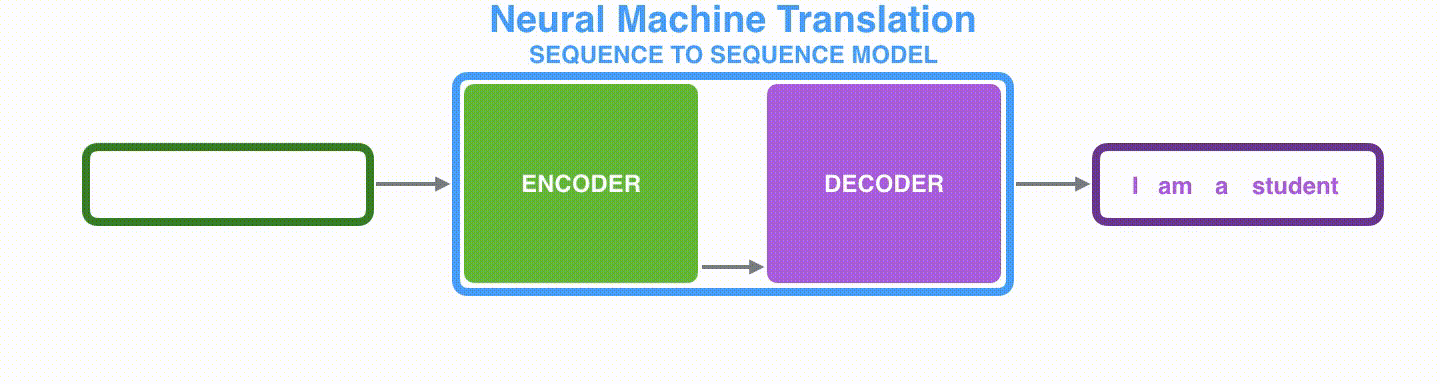
首先看seq2seq干了什么事情?seq2seq模型的输入可以是一个(单词、字母或者图像特征)序列,输出是另外一个(单词、字母或者图像特征)序列。一个训练好的seq2seq模型如下图所示:

如下图所示,以NLP中的机器翻译任务为例,序列指的是一连串的单词,输出也是一连串单词。

二、seq2seq原理
将上图中蓝色的seq2seq模型进行拆解,如下图所示:seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给紫色的解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
在机器翻译任务中,seq2seq模型实现翻译的过程如下图所示。seq2seq模型中的编码器和解码器一般采用的是循环神经网络RNN,编码器将输入的法语单词序列编码成context向量(在绿色encoder和紫色decoder中间出现),然后解码器根据context向量解码出英语单词序列。
黄色的context向量本质上是一组浮点数。而这个context的数组长度是基于编码器RNN的隐藏层神经元数量的。下图展示了长度为4的context向量,但在实际应用中,context向量的长度是自定义的,比如可能是256,512或者1024。

context向量对应上图中间浮点数向量。在下文中,我们会可视化这些数字向量,使用更明亮的色彩来表示更高的值,如上图右边所示
RNN是如何具体地处理输入序列:
- 假设序列输入是一个句子,这个句子可以由 n 个词表示: \(sentence =\left\{w_{1}, w_{2}, \ldots, w_{n}\right\}\) 。
- RNN首先将句子中的每一个词映射成为一个向量得到一个向量序列: \(X=\left\{x_{1}, x_{2}, \ldots, x_{n}\right\}\) ,每个单词映射得到的向量通常又叫做:word embedding。
- 然后在处理第 $t \in[1, n] $ 个时间步的序列输入 $x_{t} $ 时,RNN网络的输入和输出可以表示为:
\(h_{t}=R N N\left(x_{t}, h_{t-1}\right)\)
- 输入:RNN在时间步t的输入之一为单词 \(w_{t}\) 经过映射得到的向量 $x_{t} $ 。
- 输入: RNN另一个输入为上一个时间步 t-1 得到的hidden state向量 \(h_{t-1}\) ,同样是一个向 量。
- 输出:RNN在时间步 t 的输出为 \(h_{t}\) hidden state向量。
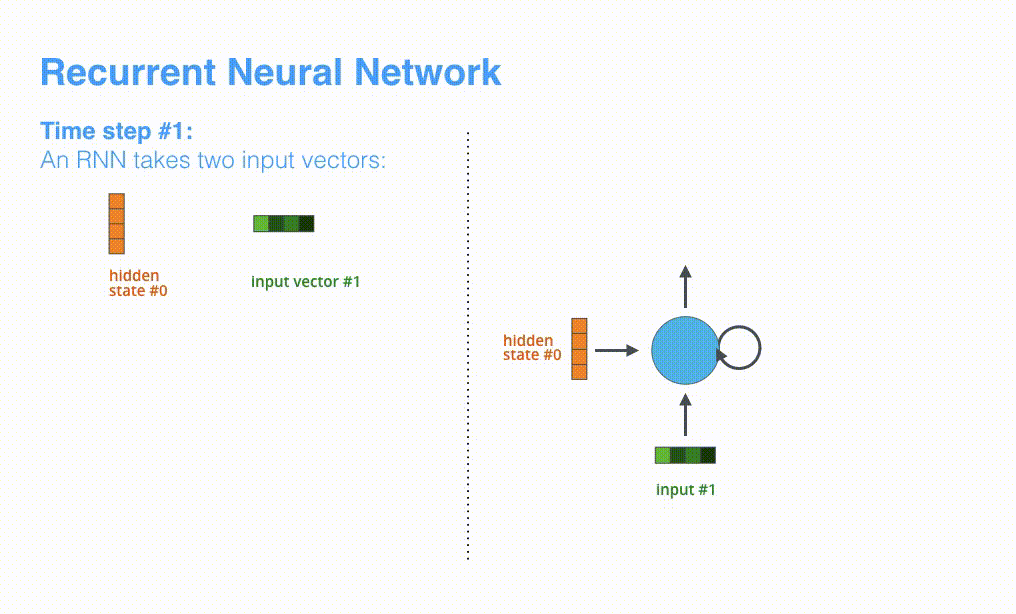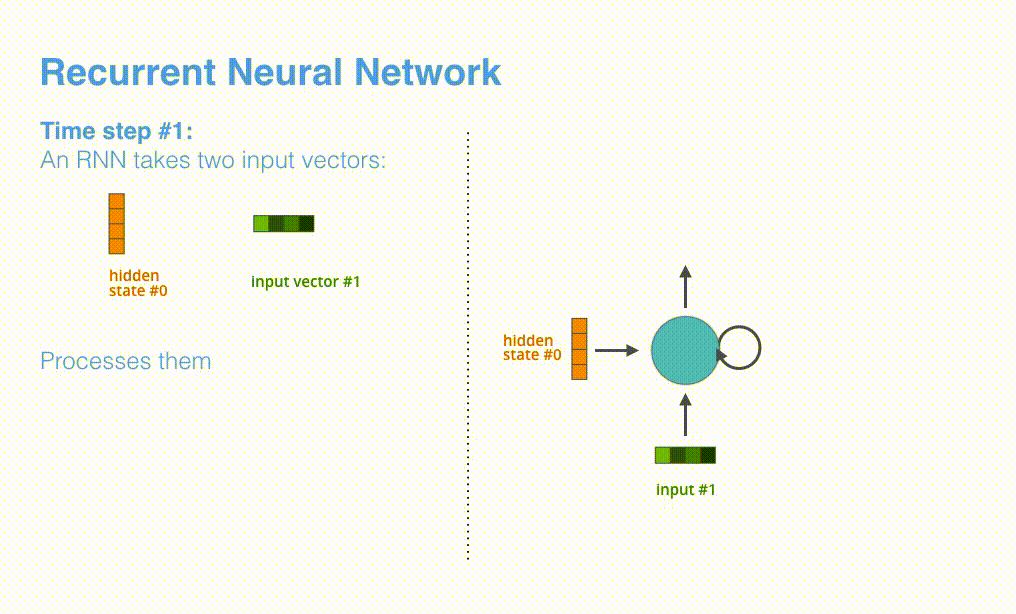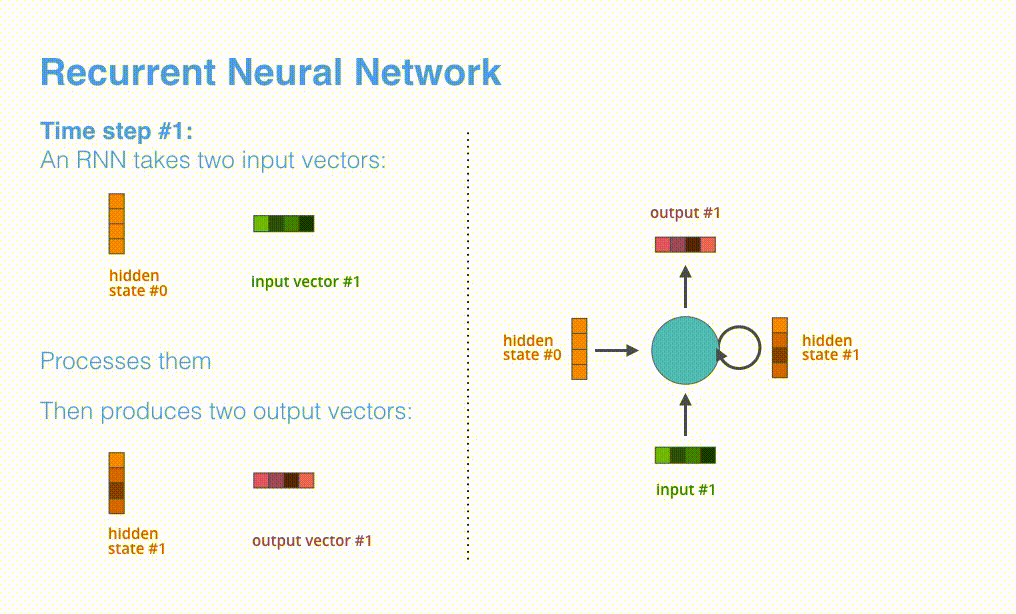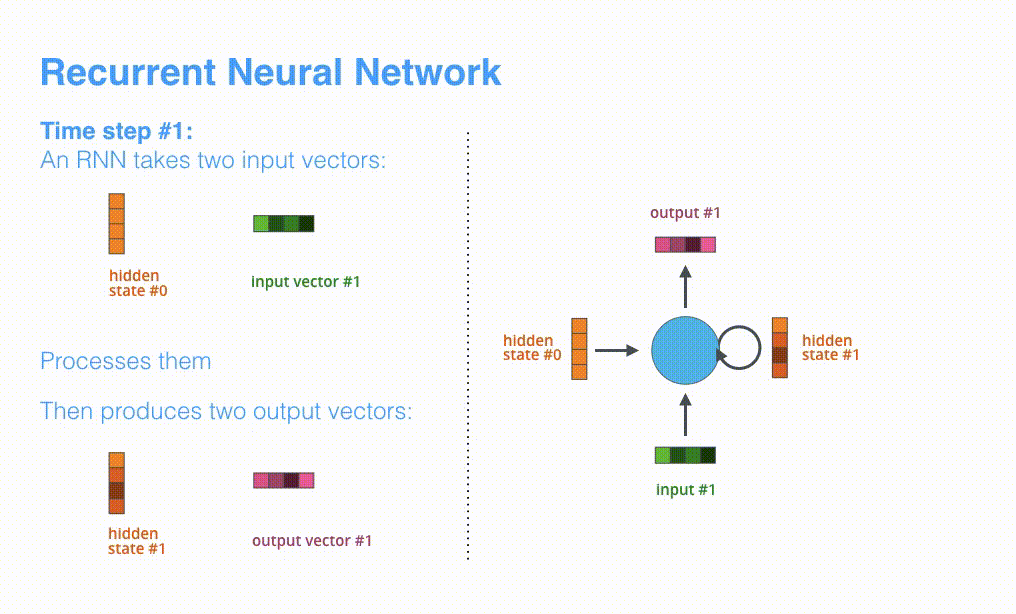
如图所示,RNN在第2个时间步,采用第1个时间步得到hidden state#10(隐藏层状态)和第2个时间步的输入向量input#1,来得到新的输出hidden state#1。
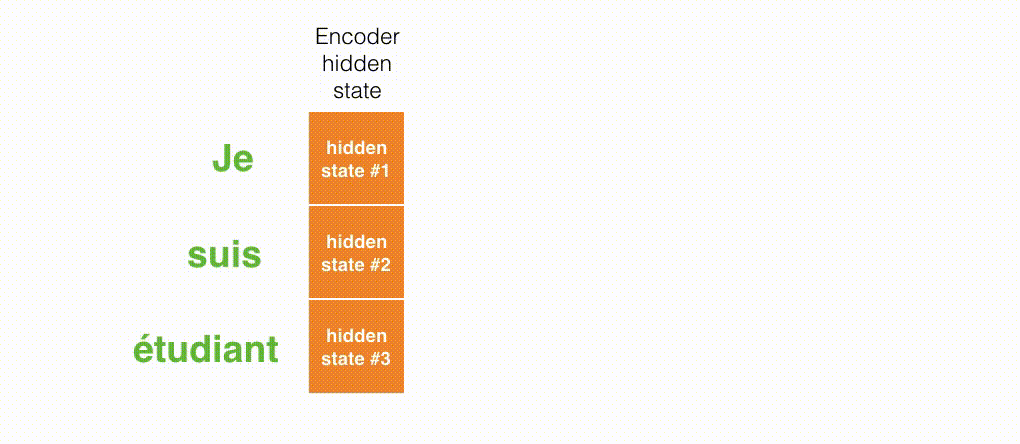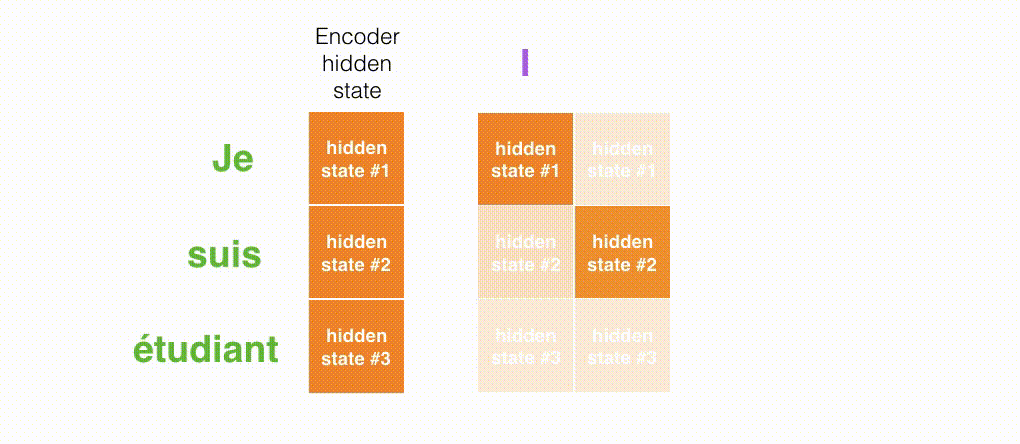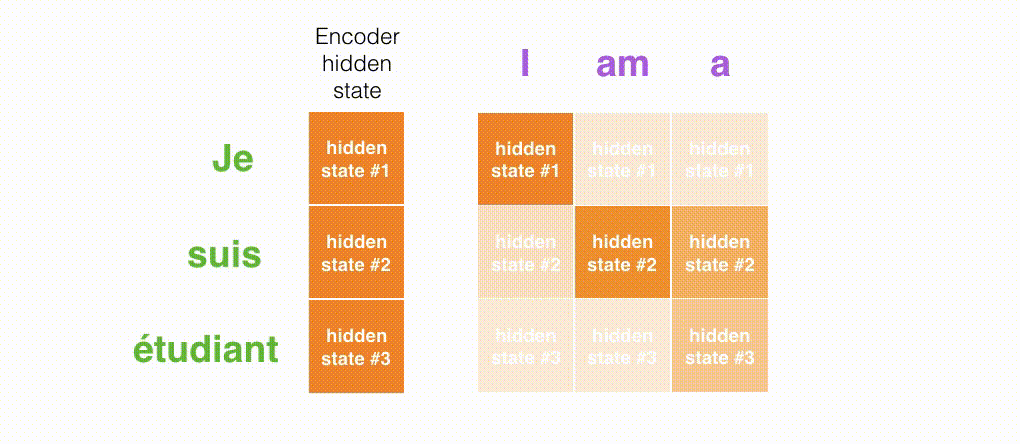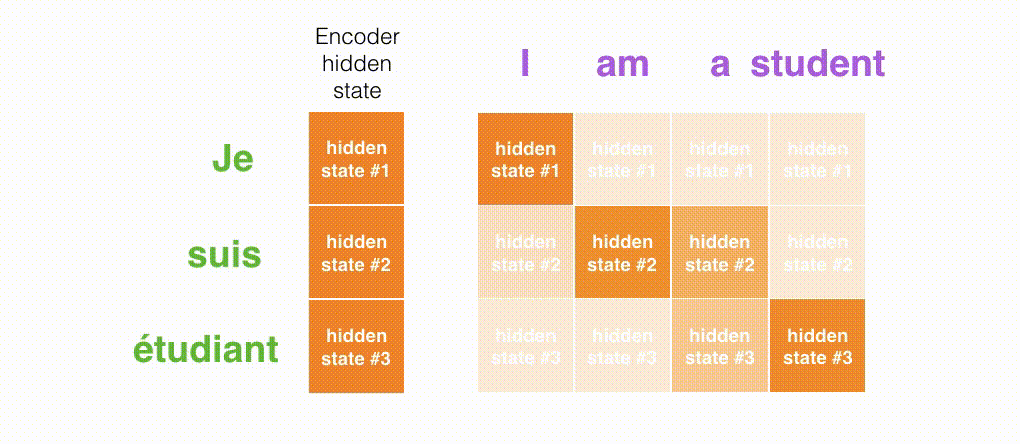
上面的动态图,让我们详细观察得到编码器如何在每个时间步得到hidden sate,并将最终的hidden state传输给解码器,解码器根据编码器所给予的最后一个hidden state信息解码处输出序列。注意,最后一个 hidden state实际上是我们上文提到的context向量。
接着,编码器首先按照时间步依次编码每个法语单词,最终将最后一个hidden state也就是context向量传递给解码器,解码器根据context向量逐步解码得到英文输出。
三、
seq2seq模型处理长文本序列有哪些难点
1.长期依赖问题:由于长文本序列中存在大量的上下文信息,因此需要建立模型能够捕捉到长期的依赖关系。但是,常规的RNN结构很容易出现梯度消失或梯度爆炸的问题,导致模型无法有效地处理长期的依赖关系。
2.内存限制:Seq2seq模型在训练和推理过程中需要对整个序列进行处理,而长文本序列可能会超出模型内存限制的范围,导致无法处理完整个序列。
3.对齐问题:解码器在生成输出序列时需要与输入序列对齐,但是当输入序列很长时,对齐问题变得更加困难。此时,模型需要学习如何在长文本序列中保持正确的对齐关系,以便生成正确的输出序列。
4.训练时间和计算成本:由于长文本序列需要更多的计算和处理,因此训练和推理时间会更长,计算成本也会更高。
5.数据稀疏性:长文本序列通常包含大量的稀疏数据,例如停用词、低频词等。这些数据可能会导致模型学习不到足够的信息,从而影响模型的性能。
四、Attention的引入
基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。一方面单个向量很难包含所有文本序列的信息,另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)。
面对以上问题,Bahdanau等2014发布的Neural Machine Translation by Jointly Learning to Align and Translate 和 Luong等2015年发布的Effective Approaches to Attention-based Neural Machine Translation两篇论文中,提出了一种叫做注意力attetion的技术。通过attention技术,seq2seq模型极大地提高了机器翻译的质量。归其原因是:attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
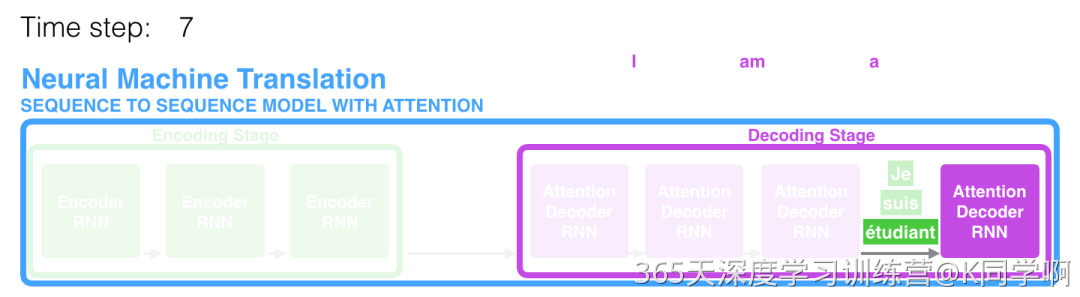
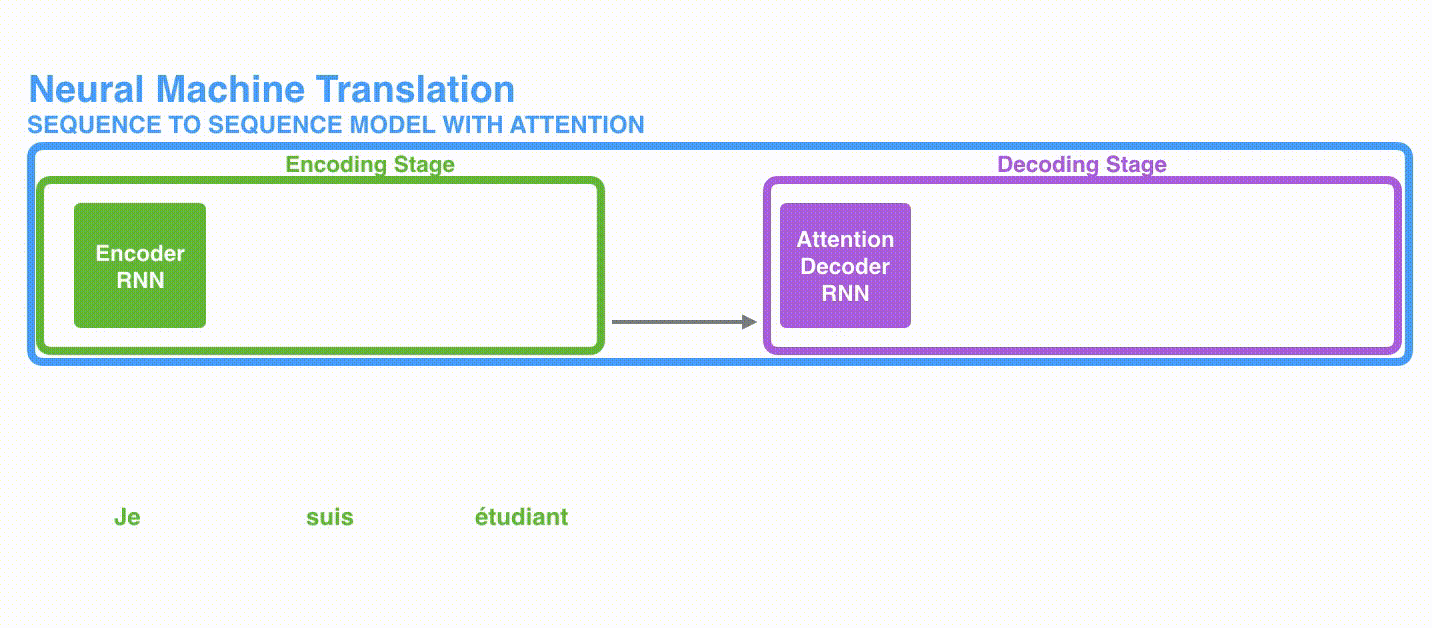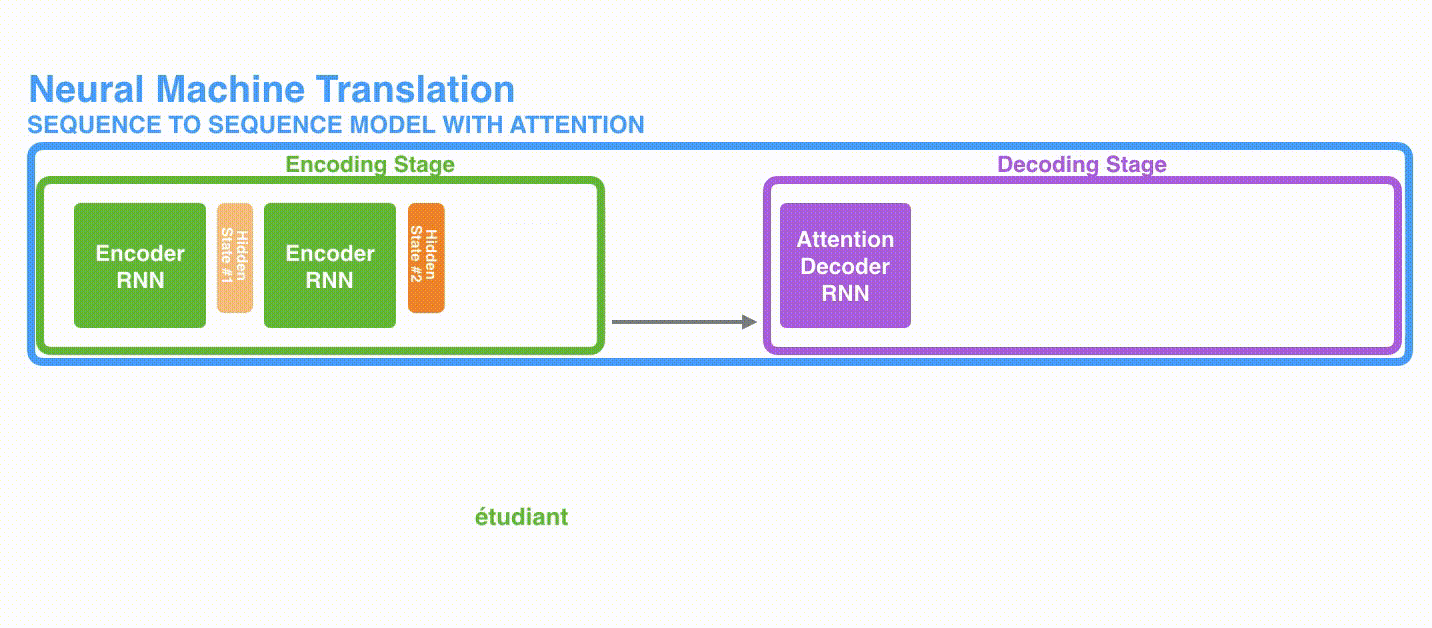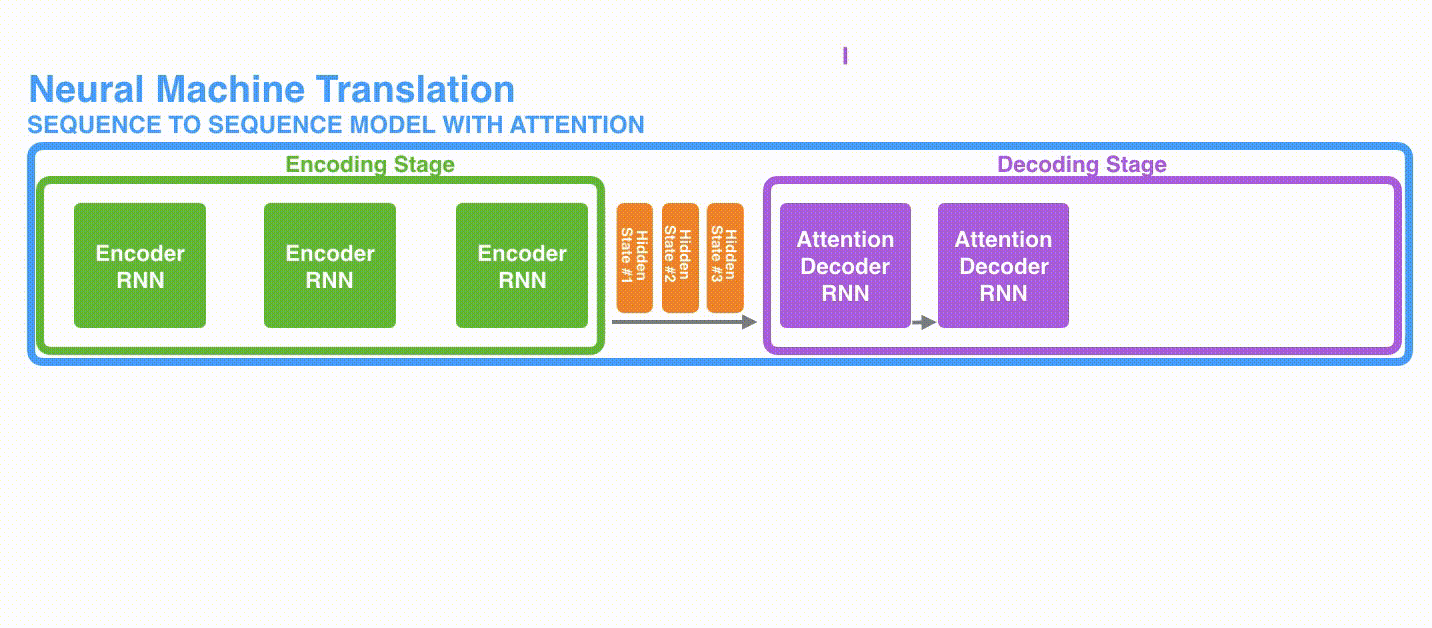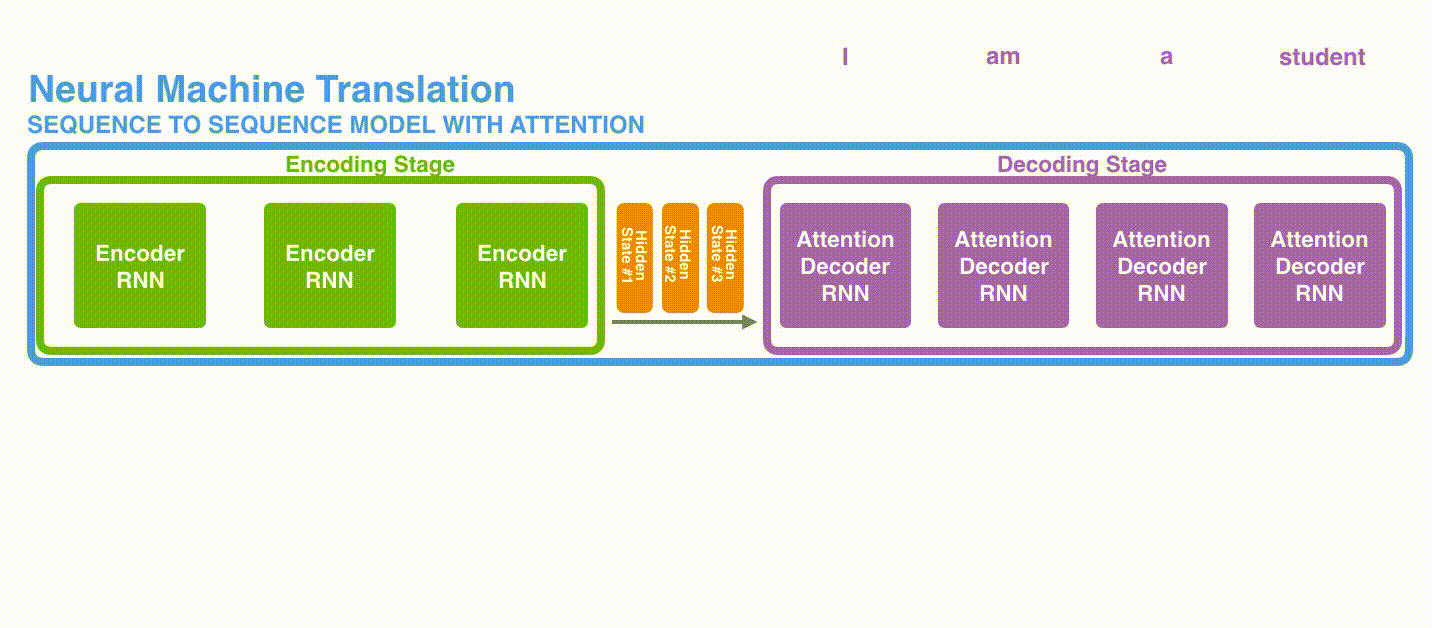
在第 7 个时间步,注意力机制使得解码器在产生英语翻译student英文翻译之前,可以将注意力集中在法语输入序列的:étudiant。
一个注意力模型与经典的seq2seq模型主要有2点不同:
-
首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态),如下面的动态图所示:
-
注意力模型的解码器在产生输出之前,做了一个额外的attention处理。如下图所示,具体为:
a. 由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden state(隐藏层状态)。
b. 给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
c. 所有hidden state(隐藏层状态)的分数经过softmax进行归一化。
d. 将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
e. 将所有hidden state根据对应分数进行加权求和,得到对应时间步的context向量。

结合注意力的seq2seq模型解码器全流程:
可视化一下注意力机制,看看在解码器在每个时间步关注了输入序列的哪些部分:
注意力模型不是无意识地把输出的第一个单词对应到输入的第一个单词,它是在训练阶段学习到如何对两种语言的单词进行对应(在本文的例子中,是法语和英语)。