底层flink join
分布式数据库 Join 查询设计与实现浅析
本文记录 Mysql 分库分表 和 Elasticsearch Join 查询的实现思路,了解分布式场景数据处理的设计方案。文章从常用的关系型数据库 MySQL 的分库分表Join 分析,再到非关系型 ElasticSearch 来分析 Join 实现策略。逐步深入Join 的实现机制。 ......
推荐一款比Flink CDC更好用的免费CDC工具
很多中大型企业都希望选择一款足够轻量好用的CDC工具,而且最好是小白用户都能使用的CDC工具,今天就推荐一款小白都能安装并立即使用的CDC工具给大家。 CDC(Change Data Capture)是一种用于捕获和传递数据库实时变更的技术。它允许您实时地监测和捕获数据库中的数据变化,并将这些变化以 ......
【OC底层原理学习笔记】1- OC对象的本质
一、OC的本质 我们平时编写的Objective-C代码,底层实现其实都是C\C++代码所以Objective-C的面向对象都是基于C\C++的数据结构实现的Objective-C的对象、类主要是基于C\C++的结构体实现的 如何将Objective-C代码转换为C\C++代码?在终端输入:xcru ......
Flink - 概述
官网:https://flink.apache.org/ Flink 是什么 为什么选择Flink 流处理的应用场景 Flink的特点 Flink 是什么 是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能。 是一个框架和分布式处理引擎,用于对无界和有界数 ......
laravel clickhouse join
(79条消息) 列式存储数据库ClickHouse的安装及使用Laravel连接使用_larval clickhouse_风中一匹狼2333的博客-CSDN博客 https://blog.csdn.net/qq_32404231/article/details/118930322 ~~~ $bd = ......
US firm's official entry into segment to motivate more Chinese peers to join in
Apple Inc's augmented reality headset will help accelerate the development of the AR industrial chain in China, and push the product not only for ente ......
Flink的几种Join总结
# Regular join组 第一种: left join 流任务中,只要left的流数据到了,就输出。如果右边流没有到,输出 [L,NULL];如果右边流到了,输出 [L, R] 第二种: right join 流任务中,只要right的流数据到了,就输出。如果左边流没有到,输出 [NULL,R ......
Postgresql,MySQL, SQL Server 的多表连接(join)update 操作
数据库更新时经常会 join 其他表做判断更新,PostgreSQL 的写法与其他关系型数据库更有不同,下面以 SQL Server, MySQL,PostgreSQL 的数据库做对比和展示。 先造数据源。 create table A(id int, city varchar(20)); crea ......
flink源码分析--RPC通信过程分析
flink的通信框架基于akka,但是不懂akka也关系不大。 首先介绍几个概念,大家记住名字和对应的作用: xxxGateway:在flink中就是一个用来告诉调用者,xxx具有哪些方法可以调用的一个接口类。比如JobMasterGateway就是用来告诉所有需要调用JobMaster的用户,我J ......
flink双流join底层如何实现的
Flink是一个分布式流处理框架,它提供了丰富的操作符来处理流数据。双流(join)操作是其中一个常用的操作,用于将两个流的数据按照指定的条件进行关联。Flink的底层实现使用了一种称为“流的连接”(stream co-processing)的技术。 在Flink中,双流(join)操作通过以下步骤 ......
flink双流join时间窗口过大导致的问题
当Flink双流(join)操作的时间窗口过大时,可能会导致以下问题: 1. 内存消耗:时间窗口大小直接影响Flink系统的内存消耗。较大的时间窗口会导致需要维护更多的状态数据,从而占用更多的内存资源。 2. 延迟增加:大时间窗口可能会导致延迟增加。如果窗口的大小超过了数据流的延迟,那么在触发窗口计 ......
flink的双流join的2个流必须都是滑动窗口吗
不,Flink的双流(join)操作并不要求两个流都是滑动窗口。在双流(join)操作中,每个流可以使用不同类型的窗口,包括滑动窗口、滚动窗口或其他类型的窗口。 在Flink中,可以对每个输入流分别定义不同的窗口类型和参数,以满足实际的业务需求。只要两个流在关联键上能够匹配,并且窗口定义能够适配,就 ......
flink中的广播流实例
在Flink中,广播流(Broadcast Stream)是一种特殊的数据流类型,用于将一个数据流广播到所有并行任务中,以供每个任务共享和使用。广播流通常用于将静态数据(如维表数据)发送给所有任务,以便任务可以在本地缓存该数据,避免多次访问外部存储系统。 广播流的特点如下: - 广播流只有一个并行度 ......
flink的状态表需要保存多久
Flink的状态表保存的时间可以根据应用程序的需求进行配置。状态表的保留时间取决于两个因素: 1. **状态后端(State Backend)的配置**:Flink支持不同类型的状态后端,如内存、文件系统、RocksDB等。不同的状态后端可以配置不同的状态保留策略。例如,如果使用基于内存的状态后端, ......
flink从检查点恢复时候做什么
当发生故障时,Flink从最近的一致性检查点中恢复任务的状态。以下是从检查点恢复的主要步骤: 1. **加载检查点元数据和状态数据**:Flink首先加载最近一次成功的检查点的元数据和持久化的状态数据。检查点的元数据包含了关于检查点的信息,如检查点ID、生成时间和相关的任务信息等。持久化的状态数据包 ......
使用Redis作为维表输入的Flink示例代码
下面是一个使用Redis作为维表输入的Flink示例代码: ```java import org.apache.flink.api.common.functions.RichFlatMapFunction; import org.apache.flink.api.common.state.MapSt ......
flink的各个算子在收到barrier的时候会做什么
在Flink中,各个算子(算子链中的每个算子)在收到 barrier(检查点屏障)时会执行以下操作: 1. **算子状态快照**:算子会触发对其状态的快照操作,以捕获当前状态的一致性快照。这包括算子的运行时状态、缓冲区或累加器等数据。 2. **处理挂起输入数据**:算子会将收到的 barrier ......
flink中一个多输入的算子如何决定是否可以往下游算子发送barrier
在Flink中,多输入的算子在决定是否可以往下发 barrier 时需要满足以下条件: 1. **输入流的 barrier 对齐**:多输入的算子必须要求所有输入流都处于 barrier 对齐状态,即收到了相同的 barrier。这意味着所有输入流的上游任务都已经收到了相同的 barrier,并向下 ......
《深度剖析CPython解释器》19. Python类机制的深度解析(第三部分): 自定义类的底层实现、以及metaclass
https://www.cnblogs.com/traditional/p/13593927.html 楔子 Python除了给我提供了很多的类之外,还支持我们定义属于自己的类,那么Python底层是如何做的呢?我们下面就来看看。 自定义class 老规矩,如果想知道底层是怎么做的,那么就必须要通过 ......
Flink CDC
# **第1章 CDC简介** ## 1.1 什么是CDC CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 ## 1 ......
linux 中join命令
001、 [root@PC1 test3]# ls file1.txt file2.txt [root@PC1 test3]# cat file1.txt 1 John 2 Mary 3 Tom [root@PC1 test3]# cat file2.txt 1 M 2 F 4 M [root@PC ......
Flink中的Window和Time详解
### Window(窗口) Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。 通常来讲,Window是一种可以把无界数据切割为有界数据块的手段 例如,对流中的所有元素进行计 ......
Flink核心API之Table API和SQL
### Table API & SQL 注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现Flink中所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。 Table API和SQL的由来: Flink针对标准的流处理和批处理提供了两种 ......
Flink核心API之DataSet
### DataSet API DataSet API主要可以分为3块来分析:DataSource、Transformation、Sink。 DataSource是程序的数据源输入。 Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap、filt ......
Flink核心API之DataStream
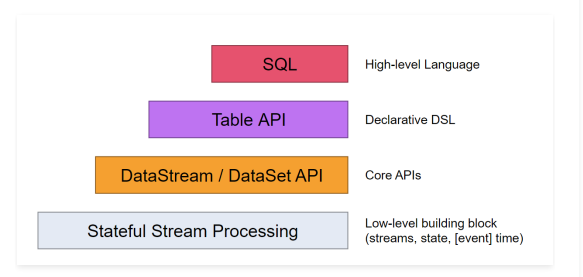 Flink中提供了4种不同层次的API,每种API在简洁和易表达之间有自己的权衡,适用于不同的场景。目前 ......
Flink安装部署
### Flink集群安装部署 Flink支持多种安装部署方式 - Standalone - ON YARN - Mesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境 ......
Flink详解
### 什么是Flink Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。 分布式:表示flink程序可以运行在很多台机器上, 高性能:表示Flink处理性能比较高 高可用:表示flink支持程序的自动重启机制。 准确的:表示flink可以保证处理数据的准确性。 Fl ......
@@linq left join group
@@linq left join group 如何实现LINQ的left join group by语法? 在LINQ下这样写 var query = (from st in db.Student join sc in db.Score on st.id equals sc.sid into g1 ......
FLink写入Clickhouse优化
一、背景 ck因为有合并文件操作,适合批量写入。如单条插入则速度太慢 二、Flink写入ck优化 改为分批插入,代码如下 DataStream<Row> stream = ... stream.addSink(JdbcSink.sink( "INSERT INTO mytable (col1, co ......