clickhouse数据flink
直播平台三度关系推荐之数据采集模块分析
下面我们就从第一个模块,数据采集模块开始。 注意:在实际工作中,数据采集模块不是只针对某一个项目而言的,而是一个公共的采集平台,所有项目依赖的数据全部是来源于数据采集模块,所以在设计采集模块的时候要考虑通用性。 ### 数据采集架构详细分析 在具体开始之前,我们还要再分析一些内容 我们前面在分析整体 ......
I/O密集型应用模型 数据密集型应用 Node对CPU密集型的场景不够友好
语雀 https://help.aliyun.com/document_detail/193189.html 更新时间:2022-11-28 18:16 产品详情 相关技术圈 我的收藏 本文介绍如何通过函数计算,解决语雀CPU密集场景下,进程被阻塞等问题。 客户介绍 语雀是一个专业的云端知识库,用于 ......
第2章. 变量和简单数据类型
2.2 变量 2.2.1 变量的命名和使用 2.2.2 使用变量时避免命名错误 2.2.3 变量是标签 2.3 字符串 2.3.1 使用方法修改字符串的大小写 2.3.2 在字符串中使用变量 2.3.3 使用制表符或换行符来添加空白 2.3.4 删除空白 2.3.5 使用字符串时避免语法错误 2.4 ......
redis主从数据同步的原理
# redis主从数据同步的原理 ## 数据同步原理 主从第一次同步是全量同步,但是如果slave重启后同步,则执行增量同步。 选题背景:NBA 作为世界上水平最高的篮球联赛,吸引了无数的球迷。每一场NBA 比赛都会产生大量的数据信息,如果能够有效地运用这些数据,便可以充分发挥出其潜在价值。 在每年赛季开始之前,大量的媒体专家都会对本赛季 NBA 常规赛的情况进行预测,这其中球队战绩和明星球员的个人数据是大家着重讨论的 ......
【转】ZFS与数据去重
从这篇文章了解到zfs的块级去重功能? https://www.cnblogs.com/cjdty/p/16813040.html 那这个zfs的块级去重功能有什么用呢?? 原文: https://www.cnblogs.com/itech/archive/2012/06/19/2555442.ht ......
4种数据同步到Elasticsearch方案
上周听到公司同事分享 MySQL 同步数据到 ES 的方案,发现很有意思,感觉有必要将这块知识点再总结提炼一下,就有了这篇文章。 本文会先讲述数据同步的 4 种方案,并给出常用数据迁移工具,干货满满! 不 BB,上文章目录: 1. 前言 在实际项目开发中,我们经常将 MySQL 作为业务数据库,ES ......
JAVA的springboot+vue医疗预约服务管理信息系统,医院预约管理系统,附源码+数据库+论文+PPT
**1、项目介绍** 会员制医疗预约服务管理信息系统是针对会员制医疗预约服务管理方面必不可少的一个部分。在会员制医疗预约服务管理的整个过程中,会员制医疗预约服务管理系统担负着最重要的角色。为满足如今日益复杂的管理需求,各类的管理系统也在不断改进。本课题所设计的是会员制医疗预约服务管理信息系统,使用j ......
数据库应用2023-06-03 触发器
Mysql触发器实例详解 - Mr_Echo - 博客园 (cnblogs.com) CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW trigger_stmt trigger_name:触发 ......
关于MySQL数据库的索引的作用及如何创建?
一、创建索引的作用? 原因:创建索引可以大大提高系统的性能。第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。第四,在使用分组和排序子句进行数据检 ......
Splunk Enterprise 9.0.5 (macOS, Linux, Windows) 发布 - 机器数据管理和分析
Splunk Enterprise 9.0.5 (macOS, Linux, Windows) - 机器数据管理和分析 请访问原文链接:,查看最新版。原创作品,转载请保留出处。 作者主页:[sysin.org](https://sysin.org) ## 混合世界的数据平台 快速、大规模地从可见性转 ......
大白话讲解数据库的三级模式(所谓的内外模式在生活中到底是什么东西?)
具象化理解数据库的三级模式 形象一点来说,把数据看做货物,数据库是仓库,模式就是表格。 你有一个仓库,仓库里成千上万的货物,随便你怎么堆,你堆个正方体,堆个圆柱体,甚至随便乱堆都行,你怎么堆的叫内模式。 完事你写了一张表,表上对全部货物按某个标准分类,而且标清了啥货物在哪(这个是模式内模式映射),你 ......
js使用xlsx插件导出table中的数据
js代码 需要引入<script type="text/javascript" src="static/js/xlsx.core.min.js"></script> //导出excel function toExcel(){ var blob = sheet2blob(XLSX.utils.tabl ......
3、数据库:Oracle部署 - 系统部署系列文章
Oracle数据库的安装,以前写过一篇,这次将新版的安装再记录一次,让读者能够有所了解,笔者也能够记录下最新版的安装过程。 一、数据库下载; Oracle最新版目前在官网是19c,从下面这个链接进去下载便可。 https://www.oracle.com/cn/database/technologi ......
Neo4j图数据库快速使用
针对这个项目中用到的技术组件,只有filebeat和neo4j我们没有使用过 不过filebeat比较简单,类似于flume,在使用的时候主要是写配置文件,所以在后面用到的时候我们再具体分析。 下面我们来学习一下neo4j的使用,让大家快速了解它并掌握它的常见用法。 ### Neo4j介绍 Neo4 ......
Flink中的Window和Time详解
### Window(窗口) Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。 通常来讲,Window是一种可以把无界数据切割为有界数据块的手段 例如,对流中的所有元素进行计 ......
Flink核心API之Table API和SQL
### Table API & SQL 注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现Flink中所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。 Table API和SQL的由来: Flink针对标准的流处理和批处理提供了两种 ......
Flink核心API之DataSet
### DataSet API DataSet API主要可以分为3块来分析:DataSource、Transformation、Sink。 DataSource是程序的数据源输入。 Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap、filt ......
Flink核心API之DataStream
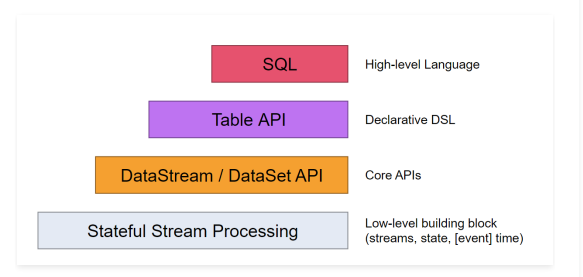 Flink中提供了4种不同层次的API,每种API在简洁和易表达之间有自己的权衡,适用于不同的场景。目前 ......
对一个二维数组中的数据排序,方法如下: 将整个数组中值最小的元素所在行调整为数组第一行, 将除第一行外的行中最小元素所在行调整为第2行, 将除第1,2行外的行中最小值元素所在行调整为第3行,以此类推
/* 对一个二维数组中的数据排序,方法如下: 将整个数组中值最小的元素所在行调整为数组第一行, 将除第一行外的行中最小元素所在行调整为第2行, 将除第1,2行外的行中最小值元素所在行调整为第3行,以此类推 */ #include<stdio.h>#include<stdlib.h>#include< ......
关于MySQL数据库的外键作用及如何创建?
一、外键的作用: 外键的主要作用是保证数据的一致性和完整性,并且减少数据冗余。主要体现在以下两个方面:1、阻止执行从表插入新行,其外键值不是主表的主键值便阻止插入。从表修改外键值,新值不是主表的主键值便阻止修改。主表删除行,其主键值在从表里存在便阻止删除(要想删除,必须先删除从表的相关行)。主表修改 ......
virtio数据包过滤实现
# 背景和意义 在dpdk实现过滤包的意义主要有两个方面: 第一是出于性能考虑,如果我们对所接受的数据包的类型有所要求,在dpdk这边直接进行过滤的话,可以大大加快处理的效率,节省资源,提升系统性能与吞吐量。否则,包的接收需要通过dpdk vhost user,到virtio net,最后到达协议栈 ......
一个sqlite3 复杂的数据库端修改某个字符串字段中的子字符串的sql写法
"update not_match_files set policy_id_tms = replace(policy_id_tms, substr(policy_id_tms,instr(policy_id_tms,'," + m_pid_id[v_del_policies[idx]] + ":') ......
Flink安装部署
### Flink集群安装部署 Flink支持多种安装部署方式 - Standalone - ON YARN - Mesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境 ......
Flink详解
### 什么是Flink Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。 分布式:表示flink程序可以运行在很多台机器上, 高性能:表示Flink处理性能比较高 高可用:表示flink支持程序的自动重启机制。 准确的:表示flink可以保证处理数据的准确性。 Fl ......
为什么数据可视化对用户体验设计很重要
如今,我们发现自己正在以前所未有的速度消耗大量信息。从在线交易到社交媒体互动,再到科学研究,数据的复杂性呈指数级增长。这揭示了一个挑战——如何将这些原始数据转化为可操作的洞察力。 这就是数据可视化的用武之地。数据可视化是我们在为用户设计时都应该考虑的一个非常重要的概念。 在本文中,您将了解什么是数据 ......
数据可视化之Zeppelin
### 前言 数据可视化这块不是项目的重点,不过为了让大家能有一个更加直观的感受,我们可以选择一些现成的数据可视化工具实现。 咱们前面分析过,想要查询hive中的数据可以使用hue,不过hue无法自动生成图表。 所以我们可以考虑使用Zeppelin,Zeppelin是一个Apache的孵化项目.一个 ......
Vue——属性指令、style和class、条件渲染、列表渲染、事件处理、数据双向绑定、过滤案例
## vm对象 ```html {{name}} 点我 ``` ## 函数传参 ```html 函数,可以多传参数,也可以少传参数,都不会报错 点我 事件对象,调用函数,不传参数,会把当前事件对象,传入,可以不接收,也可以接收 点我2 点我3 ``` ## 属性指令 ```html // 标签上 n ......
数据仓库之订单拉链表实战
### 什么是拉链表 针对订单表、订单商品表,流水表,这些表中的数据是比较多的,如果使用全量的方式,会造成大量的数据冗余,浪费磁盘空间。 所以这种表,一般使用增量的方式,每日采集新增的数据。 在这注意一点:针对订单表,如果单纯的按照订单产生时间增量采集数据,是有问题的,因为用户可能今天下单,明天才支 ......