transformer模型gpt
多模态大语言模型 LlaVA 论文解读:Visual Instruction Tuning
: "Implements FFN equation." def __init__(self, d_model, d_ff, dro ......
如何在矩池云复现开源对话语言模型 ChatGLM
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatG... ......
通用大模型如何突破垂直行业场景?
从京东离开后,周伯文已经很久没有这么兴奋了。 ChatGPT横空出世搅动乾坤,如同一声春雷惊醒各行各业的从业者,让他们都不约而同地听到,AGI走进现实的脚步声。 热潮之下,人们看到王慧文、王小川下场创业,也看到百度、阿里虎踞龙盘。周伯文作为IBM、京东两家大厂的AI研究院前院长,研究人工智能基础理论 ......
LLM-Blender:大语言模型排序融合框架
随着Alpaca, Vicuna, Baize, Koala等诸多大型语言模型的问世,研究人员发现虽然一些模型比如Vicuna的整体的平均表现最优,但是针对每个单独的输入,其最优模型的分布实际上是非常分散的,比如最好的Vicuna也只在20%的任务里比其他模型有优势。 有没有可能通过集成学习来综合诸 ......
本地部署开源大模型的完整教程:LangChain + Streamlit+ Llama
在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作的开发人员。 大型语言模型(llm)是指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型。这些模型使用广泛的数据集进行训练,这些数据集包括书籍、文章、 ......
Linux多线程12-生产者和消费者模型
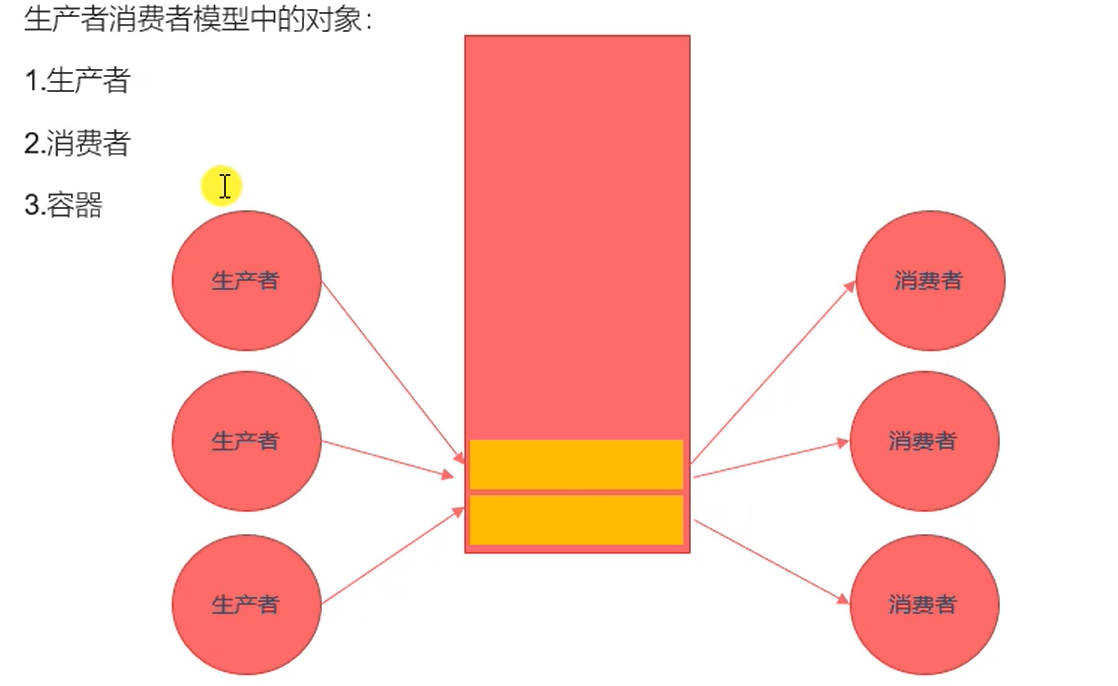 一个最简单的生产者消费者模型 ```c /* 生产者消费者模型(粗略版) */ #include #inc ......
R语言618电商大数据文本分析LDA主题模型可视化报告|附代码数据
原文链接:http://tecdat.cn/?p=1078 最近我们被客户要求撰写关于文本分析LDA主题模型的研究报告,包括一些图形和统计输出。 618购物狂欢节前后,网民较常搜索的关键词在微博、微信、新闻三大渠道的互联网数据表现,同时通过分析平台采集618相关媒体报道和消费者提及数据 社交媒体指数 ......
ESP(EFI System Partition)分区是UEFI固件中的一个特殊分区,通常位于硬盘上的第一个分区,用于存储引导加载程序、UEFI应用程序和其他与系统启动相关的文件。ESP分区使用FAT32文件系统,并拥有特定的分区类型GUID(GUID Partition Table,GPT)
ESP(EFI System Partition)分区是UEFI固件中的一个特殊分区,通常位于硬盘上的第一个分区,用于存储引导加载程序、UEFI应用程序和其他与系统启动相关的文件。ESP分区使用FAT32文件系统,并拥有特定的分区类型GUID(GUID Partition Table,GPT)。 E ......
关于GPT工具的操作说明
关于GPT工具的操作说明 一、飞书kata (一)工具介绍:是一个AI语言模型,被设计用于自然语言处理领域,目的是帮助用户快速高效地处理语言信息。可以分析用户提供的问题和信息,并通过对输入数据进行处理和计算,给出最合适的答案。 (二)操作说明 1、打开并登录飞书 2、在飞书搜索栏搜索“Kata” 3 ......
GPT-Gstreamer操作调查
gstreamer是一个开源的多媒体框架,可以用来实现音视频的编解码、处理、播放和转码等功能。本文将介绍如何用gstreamer完成多码率视频转换与生成、音视频编解码的基本步骤和原理。 ## 多码率视频转换与生成 多码率视频转换与生成是一种常见的视频处理需求,它可以根据不同的网络环境和设备性能,提供 ......
怎么让英文大预言模型支持中文?(一)继续预训练
代码已上传到github: https://github.com/taishan1994/chinese_llm_pretrained Part1前言 前面我们已经讲过怎么构建中文领域的tokenization: https://zhuanlan.zhihu.com/p/639144223 接下来我 ......
园子的商业化努力:今晚8点有一场直播《大模型训练数据的一些事》
今晚8点有一场直播《大模型训练数据的一些事》,欢迎大家加下面的企业微信(行行人才小秘书)到时观看直播。园子最近推出的直播是行行AI人才运营的主要内容,行行AI人才是园子商业化努力的重要一步,是园子和园子的天使投资方顺顺智慧成立新公司共同运营的新业务。 ......
构件组装模型
模型的过程是: 先进行需求分析和定义,接着是设计构件组装:在整体上考虑,建立构件库:根据构件标准获取或管理构件,构件应用程序 ,测试与发布。 优点是,易扩展、重用,成本低、灵活 缺点是,需要经验丰富的设计人员,强调重用可能牺牲性能指标,第三方构件不可控 ......
css3缩放 transform: scale() 使用缩放之后顶点对齐问题
css3缩放 transform: scale() 使用缩放之后顶点对齐问题 注意点:想要将缩放之后的div对齐顶点,那么需要将css属性设置为:transform-origin: 0 0 <div style="width: 900px; height: 900px; background: gr ......
什么时候需要微调你的大模型(LLM)?
前言 在AI盛起的当下,各类AI应用不断地出现在人们的视野中,AI正在重塑着各行各业。相信现在各大公司都在进行着不同程度的AI布局,有AI大模型自研能力的公司毕竟是少数,对于大部分公司来说,在一款开源可商用的大模型基础上进行行业数据微调也正在成为一种不错的选择。 本文主要用于向大家讲解该如何微调你的 ......
一篇一个CV模型,第(1)篇:StyleGAN
写在前面: 虽说自己肯定对外宣称自己是搞CV的,但是其实在自己接近两年半(🐔)的研究生生涯中,也没有熟练掌握过很多个CV领域的模型,或者说是CV领域的概念。我认为这个东西是必须得补的,不然作为CV算法工程师是肯定要被淘汰的。目前激发自己研究和学习热情的最好方式还是经营自己小小的博客,因此想开一个系 ......
V模型
v模型就是测试贯穿始终的开发模型, 它是提前做测试计划, v模型分几个阶段 需求分析、概要设计、详细设计、编码 而对标的测试是 验收测试、系统测试,集成设计,单元测试。 概要设计主要是分子系统,所以集成测试就是测系统的各个调用接口。 ......
多分类模型训练使用交叉熵损失的一个注意的点
使用交叉熵损失的网络模型最后一层不要用softmax,交叉熵损失函数会在计算的时候做softmax,如果用了会导致模型训练异常, 如果模型最后一层有softmax,则损失函数要写成 loss_fun = nn.NLLLoss() x = model(data) loss = loss_fun(tor ......
原型模型
瀑布模型是 1需求分析、2软件设计、3程序设计、4编码实现、5单元测试、6集成测试、7系统测试、8运行维护 原型模型通过瀑布模型的123过程构建一个原型来获取需求。 让客户体验,然后对原型进行更改从而得到需求。 所以原型模型一般用来获取需求,弥补了瀑布模型的缺陷1:需求不明确 原型模型两个阶段:原型 ......
Dora AI:支持3D模型的网站生成工具
Dora AI有什么魔力能在竞争激烈的Product Hunt月榜上强势登顶?我尝试从产品和运营两个方面分析下Dora AI这次的成功。 产品 Dora的本体乍看像一款3D网站编辑器,主页面和Webflow等传统设计或建站工具有点类似,都由一块空白画布和四周的功能区组成,可以在画布上添加各种图片、文 ......
瀑布模型
瀑布模型是指软件开发过程类似瀑布从上直下,一条线没有回头。 它的特点是:开发过程阶段明确,上下阶段联系紧密,一个阶段的输出是下一个阶段的输入,每个阶段必须完成才能进入下一个阶段,只适合需求的明确的项目 它的缺点是: 软件需求完整性、正确性难明确:很难做到需求完整和正确,因为现实中需求是随时有调整的, ......
软件过程模型概况
软件过程模型就是软件开发过程中遵循的流程、方法、标准、规范、思想等等所形成的模板。 目前的常用的软件过程模型有以下几种: 瀑布模型 V模型(瀑布模型的变种) 原型模型 螺旋模型(原型+瀑布) 构件组装模型/基于构件的开发方法 快速应用开发RAD(瀑布+构件组装) 统一过程/统一开发方法 敏捷开发方法 ......
【七】并发编程之IO模型
## 【七】并发编程之I/O模型 ### IO模型 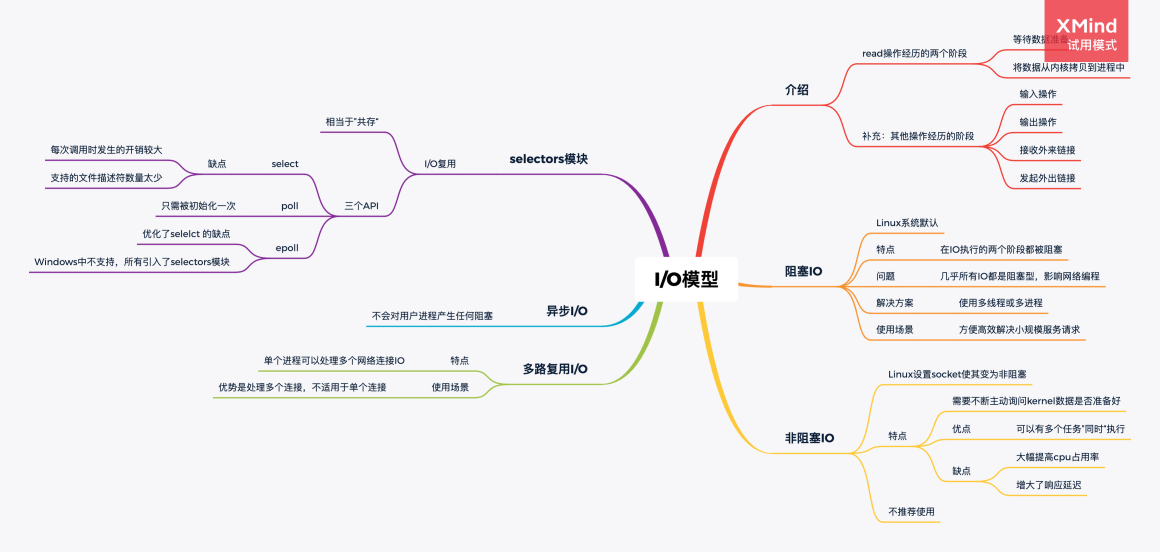 ### 【一】前序知识回顾 为了更好地了解IO模型,我们需要事 ......
模型生成技术在医疗保健领域的应用:精准诊断和治疗
[toc] 1. 引言 在医疗保健领域,精准诊断和治疗一直是一个挑战。随着人工智能和机器学习技术的发展,模型生成技术开始被应用于医疗保健领域,以实现更精准诊断和治疗。本文将介绍模型生成技术在医疗保健领域的应用:精准诊断和治疗。 医疗保健是一个涉及众多学科和领域的领域,其中之一便是生物学和统计学。这些 ......
【教程】数据挖掘中的数据挖掘算法模型构建与设计
[toc] 数据挖掘中的数据挖掘算法模型构建与设计 随着大数据时代的到来,数据挖掘已经成为企业、政府机构以及学术界关注的热点领域。数据挖掘是指从大量数据中发现有价值的信息和规律,从而为企业、政府以及学术界提供决策支持和实际应用价值。在数据挖掘中,数据挖掘算法是实现数据挖掘的关键,其模型构建与设计是数 ......
安装新版VS2022之后,添加EF实体模型没有生成对于的表格
1)找到vs2022安装路径中的EF6.Utility.CS.ttinclude.tt文件,需要去掉.tt后缀,然后再做以下修改【部分版本直接是EF6.Utility.CS.ttinclude则直接进入第二步】 2)修改EF6的实用程序EF6.Utility.CS.ttinclude文件,它默认的位 ......
HBase数据模型
HBase是一个稀疏的多维度的映射表 列族(支持动态扩展,保留旧的版本) 做不到对数据进行修改,只能生成新的,标注时间。(不考虑冗余,追求分析效率,牺牲空间,来换取时间) 列限定符 时间戳: 数据坐标概念: 四个维度(行键,列族,列限定符,时间戳)确定唯一的值 概念视图 行式存储和列式存储 面向行的 ......