transformer rnn
Transform操作——移动旋转缩放
Transform操作——移动旋转缩放 1.移动 transform.Translate(Vector3.left * (mouse_x * 15f) * Time.deltaTime); cube.transform.position = cube.transform.position + new ......
Attention机制竟有bug?Softmax是罪魁祸首,影响所有Transformer
前言 「大模型开发者,你们错了。」 本文转载自机器之心 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。 CV各大方向专栏与各个部署框架最全教程整理 【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线! ......
Meta-Transformer 多模态学习的统一框架
Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息,如自然语言、图像、点云、音频、视频、时间序列和表格数据,虽然各种数据之间存在固有的差距,但是Meta-Transformer利用冻结编码器从共享标记空间的输入数据中提取高级语义特征,不需要配对的多模态训练 ......
Python TensorFlow循环神经网络RNN-LSTM神经网络预测股票市场价格时间序列和MSE评估准确性|附代码数据
全文下载链接:http://tecdat.cn/?p=26562 最近我们被客户要求撰写关于循环神经网络的研究报告,包括一些图形和统计输出。 自 2000 年 1 月以来的股票价格数据。我们使用的是 Microsoft 股票。 该项目包括: 将时间序列数据转换为分类问题。 使用 TensorFlow ......
【d2l】【困难代码】【2】 output, state = self.rnn(X_and_context, state)
## 问题来源 【d2l】9.7 序列到序列学习 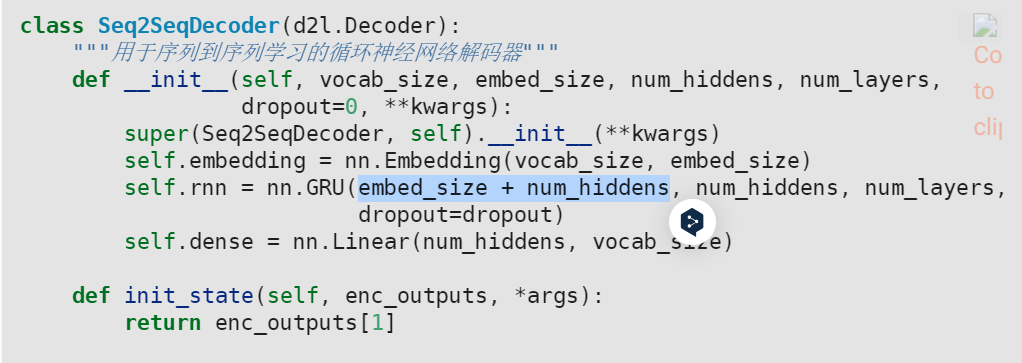 
前言 近日,香港中文大学多媒体实验室(CUHK MMLab)联合上海人工智能实验室的OpenGVLAB研究团队提出一个统一多模态学习框架 Meta-Transformer,实现骨干网络的大一统,具有一个模态共享编码器,并且无需配对数据,即可理解 12 种模态信息, 并提供了多模态无边界融合的新范式。 ......
Bidirectional Encoder Representations from Transformers
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的自然语言处理(NLP)模型。它是一个基于Transformer架构的预训练模型,通过无监督学习从大量的文本数据中学习通用的语言表示,从而能够更好... ......
Transformer模型
### Transformer模型 [Transformer模型及其实现](https://blog.csdn.net/moo611/article/details/122234867) 历史:谷歌团队在2017年提出的经典NLP模型(目前很火的bert模型就是基于此模型)。 特点:Transfor ......
CF623E Transforming Sequence
难点在于卡 `__int128`(?)。 首先 $N>K$ 显然无解,只需考虑 $N\le K$ 的情况。然而这并没有什么用。 把 $b$ 看作集合,显然 $b_i\subset b_{i+1}$。所以令 $f_{n,i}$ 为考虑到 $b_n$ 且 $|b_n|=i$ 的方案数,集合元素无序,即选 ......
VBA利用transform函数和ADO实现交叉汇总
VBA中transform函数基本语法: Creates a crosstab query. Syntax TRANSFORM aggfunction selectstatement PIVOT pivotfield [IN (value1[, value2[, ...]])] The TRANSF ......
Vision Transformer
Vision Transformer 本文关注ViT论文`4.5 Inspecting Vision Transformer`可视化的原理及实现,此外还对ViT pytorch源码实现进行理解 [toc] # Introduction [论文地址](arXiv:2010.11929) ## Titl ......
transformer中解码器的实现细节
1. 前言 17年google团队发表l了论文《Attention Is All You Need》,transformer横空出世,并引领了AI学术圈的研发风向,以Transformer为基础模型的新模型层出不穷,无论是NLP还是CV或者是多模态,attention遍地开花。 这篇文章遵循enco ......
【d2l 问题记录】【1】 视频55 从零实现rnn
 ```python H, = state ``` 这句代码我真是看懵逼了。 ## 1 元组的打包和解包 ......
Transformer(转换器)
Sequence To Sequence(序列对序列) 输入一个序列,输出一个序列 输出序列的长度由机器自己决定,例如:语音辨识、机器翻译、语音翻译 Sequence To Sequence一般分成两部分: Encoder:传入一个序列,由Encoder处理后传给Decoder Decoder:决定 ......
自注意机制和RNN
self attention(自注意机制) 输入:以往神经网络的输入都是一个向量;如果现在输入的是一排向量,并且数量不唯一,应该如何处理: 例一:一句英文 One-hot Encoding:开一个长度为世界上全部词汇数的向量表示一个词汇(缺点:词汇间没关系) Word Embedding:给每个词汇 ......
斯坦福博士一己之力让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
前言 FlashAttention新升级!斯坦福博士一人重写算法,第二代实现了最高9倍速提升。 本文转载自新智元 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。 CV各大方向专栏与各个部署框架最全教程整理 【CV技 ......
Transformer取代者登场!微软、清华刚推出RetNet:成本低、速度快、性能强
前言 Transformer 的训练并行性是以低效推理为代价的:每一步的复杂度为 O (N) 且键值缓存受内存限制,让 Transformer 不适合部署。不断增长的序列长度会增加 GPU 内存消耗和延迟,并降低推理速度。研究者们一直在努力开发下一代架构,希望保留训练并行性和 Transformer ......
[未解决] vue transform-blocks解析源代码报错:Illegal tag name. Use '<' to print '<'.
报错内容: [vite] Internal server error: Illegal tag name. Use '<' to print '`标签后报错,但其他vue文件可以正常读取和展示。 报错的文件,去掉``标签就可以正常加载。报错的方法是vue-compiler的`baseParse()` ......
从RNN到Transformer
## 1. RNN 循环神经网络的内容可参考https://www.youtube.com/watch?v=UNmqTiOnRfg。 RNN建模的对象是具有时间上前后依赖关系的对象。以youtube上的这个视频为例,一个厨师如果只根据天气来决定今天他做什么菜,那么就是一个普通的神经网络;但如果他第i ......
Hugging News #0717: 开源大模型榜单更新、音频 Transformers 课程完成发布!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息,快来看看吧! 🎉 😍 ## 重磅更新 ......
大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍
# 大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍 # 1.大语言模型的预训练 ## 1.LLM预训练的基本概念 预训练属于迁移学习的范畴。现有的神经网络在进行训练时,一般基于反向传播(Back Propagation,BP)算法 ......
Transform LiveData
查询资料的其中一个场景: 创建一个回调函数,当查询后台的时候,后台有结果了,回调对应的回调函数,并将结果保存到LiveData中。 public class DataModel { ... public MutableLiveData<List<Repo>> searchRepo(String qu ......
[论文速览] A Closer Look at Self-supervised Lightweight Vision Transformers
## Pre title: A Closer Look at Self-supervised Lightweight Vision Transformers accepted: ICML 2023 paper: https://arxiv.org/abs/2205.14443 code: https ......
论文日记四:Transformer(论文解读+NLP、CV项目实战)
# 导读 重磅模型**transformer**,在2017年发布,但就今天来说产生的影响在各个领域包括NLP、CV这些都是巨大的! Paper《[Attention Is All You Need](https://arxiv.org/pdf/1706.03762.pdf)》,作者是在机器翻译这个 ......
Swin Transformer结构梳理
[TOC] > Swim Transformer是特为视觉领域设计的一种分层Transformer结构。Swin Transformer的两大特性是滑动窗口和层级式结构。 1.滑动窗口使相邻的窗口之间进行交互,从而达到全局建模的能力。 2.层级式结构的好处在于不仅灵活的提供各种尺度的信息,同时还因为 ......
Shell | Transformer-xl代码的shell代码实现
**实现网址:**https://github.com/kimiyoung/transformer-xl/tree/master/pytorch  patch embedding:例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为 ......
transformer
arXiv:1706.03762 # 1. 问题提出 全连接神经网络(FCN),可以很好的处理输入为1个向量(特征向量)的情况,但是如果输入是一组向量,FCN处理起来不太方便 以词性标记的问题为例 对于处于同一个句子中的相同的2个单词`saw`,词性不同,前者为动词(V),后者为名词(N) 如果尝试 ......
Transformer学习笔记
[09 Transformer 之什么是注意力机制(Attention)@水导](https://www.bilibili.com/video/BV1QW4y167iq) [ELMo原理解析及简单上手使用@知乎](https://zhuanlan.zhihu.com/p/51679783) ELMo ......