梯度
ITK 实例7 MHA格式文件进行带滤波三维的梯度强度提取
1 #include "itkImageFileReader.h" 2 #include "itkImageFileWriter.h" 3 #include "itkRescaleIntensityImageFilter.h" 4 #include "itkGradientMagnitudeRecu ......
ITK 实例6 PNG图像进行带滤波的二维梯度强度提取
微分是对一个数字数据的不规则操作。实际中可以方便地定义一个执行微分的比例。在执行这样的滤波时使用一个高斯核被认为是最便捷的选择。通过选择一个特定的高斯标准差(σ) ,就可以选择一个相应的比例来去除通常被认为是噪声的高频部分。 itk::GradientMagnitudeRecursiveGaussi ......
ITK 实例5 PNG图像进行不带滤波的二维梯度强度提取
图像梯度的强度广泛地应用在图像分析中,主要用来帮助检测对象轮廓和分离均匀区域。 itk::GradientMagnitudeImageFilter 使用一个简单的有限差分方式来计算图像中每个像素位置的梯度强度。例如:在二维情况下计算等同于将图像使用模块类型,如下所示:然后计算它们的平方和并计算和的平 ......
VTK 实例37:梯度算子(边缘检测)
1 #include "vtkAutoInit.h" 2 VTK_MODULE_INIT(vtkRenderingOpenGL2); 3 VTK_MODULE_INIT(vtkInteractionStyle); 4 5 #include <vtkSmartPointer.h> 6 #include ......
VTK 实例38:Sobel梯度算子(边缘检测)
1 #include "vtkAutoInit.h" 2 VTK_MODULE_INIT(vtkRenderingOpenGL2); 3 VTK_MODULE_INIT(vtkInteractionStyle); 4 5 #include <vtkSmartPointer.h> 6 #include ......
【RL】第6课-随机近似与随机梯度下降-
第6课-随机近似与随机梯度下降 ## 6.1 Motivating examples ## Mean Estimation Revisit the mean estimation problem: - Consider a random variable $X$. - Our aim is to e ......
在消费级GPU调试LLM的三种方法:梯度检查点,LoRA和量化
前言 LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。 本文转载自DeepHub IMBA 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技 ......
002-深度学习数学基础(神经网络、梯度下降、损失函数)
0. 前言 人工智能可以归结于一句话:针对特定的任务,找出合适的数学表达式,然后一直优化表达式,直到这个表达式可以用来预测未来。 针对特定的任务: 首先我们需要知道的是,人工智能其实就是为了让计算机看起来像人一样智能,为什么这么说呢?举一个人工智能的例子: 我们人看到一个动物的图片,就可以立刻知道这 ......
在消费级GPU调试LLM的三种方法:梯度检查点,LoRA和量化
LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。 梯度检查点 梯度检查点是一种在神经网络训练过程中使动态计算只存储最小层数的技术。 为了理解这个过程,我们需要了解反向传播是如何执行的,以及 ......
[论文阅读] 颜色迁移-梯度保护颜色迁移
## [论文阅读] 颜色迁移-梯度保护颜色迁移 文章: [[Gradient-Preserving Color Transfer](https://onlinelibrary.wiley.com/doi/10.1111/j.1467-8659.2009.01566.x)], [[代码未公开]()] ......
强化学习——策略梯度之Reinforce
1、策略梯度介绍 相比与DQN,策略梯度方法的区别主要在于,我们对于在某个状态下所采取的动作,并不由一个神经网络来决定,而是由一个策略函数来给出,而这个策略函数的目的,就是使得最终的奖励的累加和最大,这也是训练目标,所以训练会围绕策略函数的梯度来进行。 2、策略函数 以Reinforce算法为例, ......
TabR:检索增强能否让深度学习在表格数据上超过梯度增强模型?
这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强Retrieval Augmented技术,目的是让深度学习在表格数据上超过梯度增强模型。 检索增强一直是NLP中研究的一个方向,但是引入了检索增强的表格深度学习模型在当前实现与非基于检索的模型相比几乎没有改进。所以论文作者提出了一个新的T ......
PyTorch 中的多 GPU 训练和梯度累积作为替代方案
动动发财的小手,点个赞吧! 在[本文](https://towardsdatascience.com/multiple-gpu-training-in-pytorch-and-gradient-accumulation-as-an-alternative-to-it-e578b3fc5b91 "So ......
OpenFoam——计算单元网格梯度(gradf)
计算流程如下: 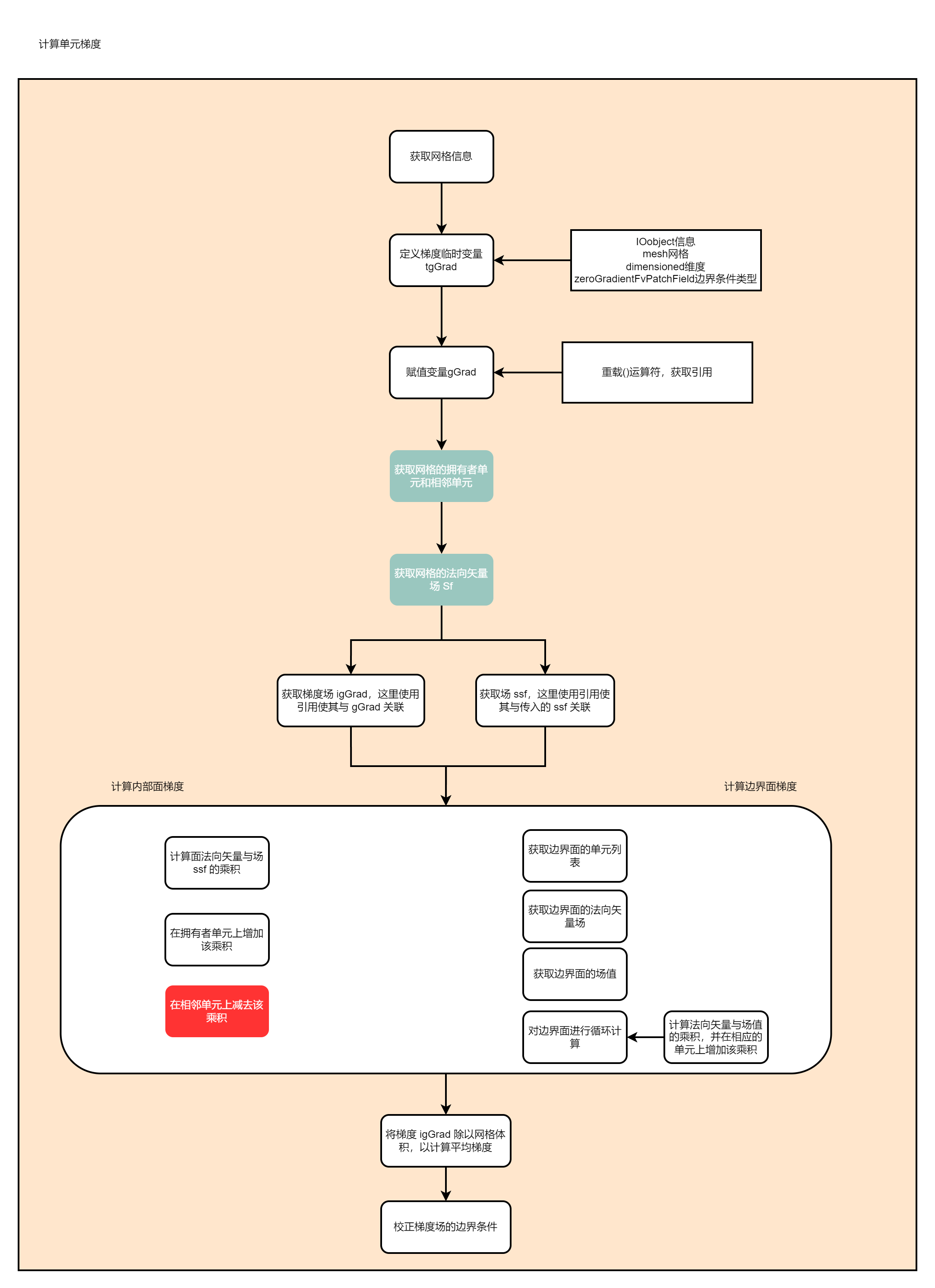 代码如下: ```c++ Foam::fv::gaussGrad::gradf ( c ......
CFD——使用扩展法计算网格梯度
## 求解流程 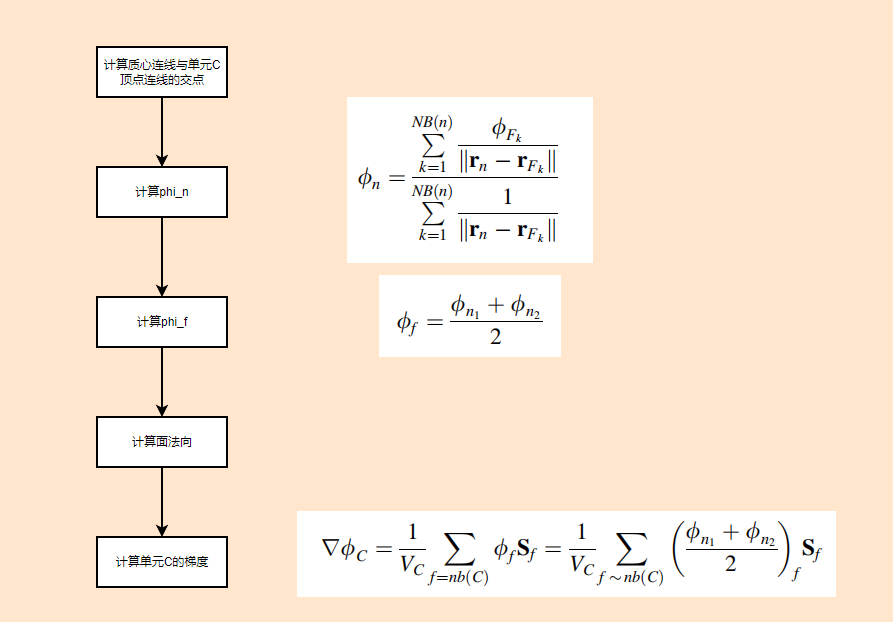 在高斯格林公式中,需要用到phi_f,以下是求解phi_f1的步骤(这里只给出phi_f ......
CFD——非结构网格梯度计算(中心法修正)
将f'作为CF(及单元C质心与周围单元质心)的中点 计算流程如下 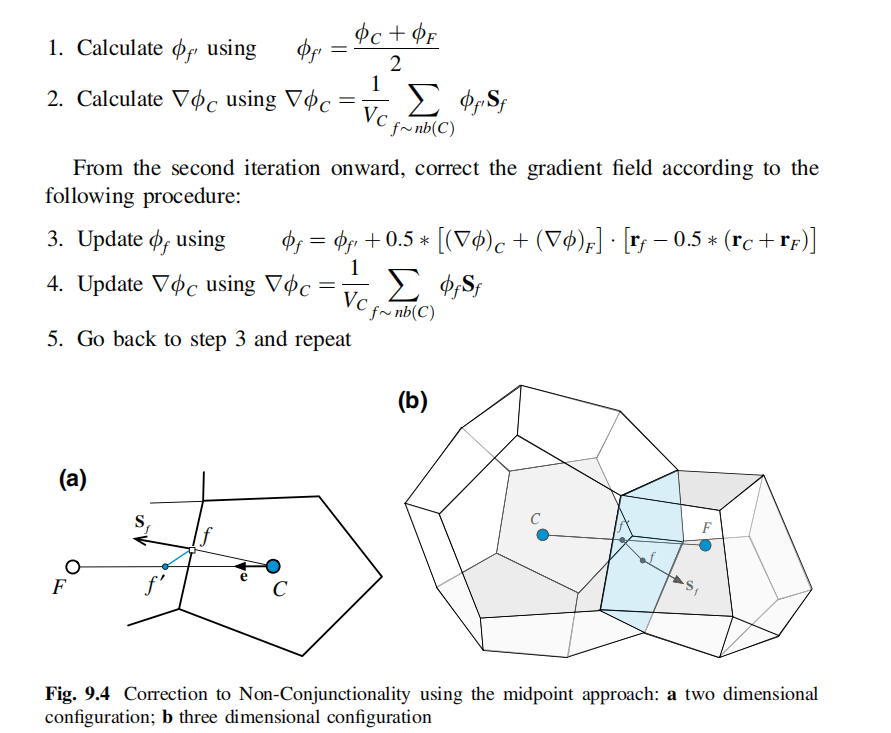 代码实现 ```python # 非 ......
CFD——非结构网格梯度计算(不修正)
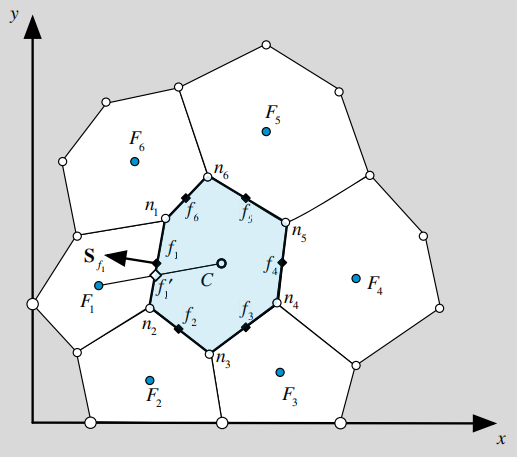 本案例在计算非结构网格的梯度时,不使用修正方法。将直接使用f'处的∅值 计算流程 算法的售电公司竞价策略研究
python代码:基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究关键词:DDPG 算法 深度强化学习 电力市场 发电商 竞价 说明文档:完美复现英文文档,可找我看文档 主要内容:代码主要研究的是多个售电公司的竞标以及报价策略,属于电力市场范畴,目前常用博弈论方法寻求电力市场均衡,但是此 ......
请介绍感知机模型及其训练算法(梯度下降法)。注意,梯度的推导是必需的。
感知机(Perceptron)是一种二分类的线性分类模型,其基本结构由一个或多个输入节点、一个加权总和和一个激活函数组成。感知机模型的训练算法通常使用梯度下降法。 感知机模型的输入是一个n维向量x=(x₁, x₂, ..., xn),对应于n个特征。每个特征都有一个对应的权重w=(w₁, w₂, . ......
众所周知,梯度下降法是一种基本的优化算法,不能保证全局最优,也不能保证效率。为什么它仍然被广泛应用于深度学习,而不是传统的凸优化算法和粒子群算法
梯度下降法在深度学习中被广泛应用的原因主要有以下几点: 适用性广泛:梯度下降法可以应用于各种深度学习模型,包括神经网络、卷积神经网络、循环神经网络等。而传统的凸优化算法和粒子群算法往往只适用于特定类型的优化问题。 原理简单:梯度下降法的原理相对简单,易于理解和实现。相比之下,传统的凸优化算法和粒子群 ......
强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient策略梯度-Cart pole游戏展示
# 强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient策略梯度-Cart pole游戏展示 - 强化学习(Reinforcement learning,简称RL)是机器学习中的一个领域,区别与监督学习和无监督学习,强调如何基于环境而行动,以取得最大化的预期利益。 - 基本操作 ......
强化学习从基础到进阶--案例与实践[7.1]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解项目实战
强化学习从基础到进阶--案例与实践[7.1]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解项目实战 ......
强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解
强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解 ......
实践讲解强化学习之梯度策略、添加基线、优势函数、动作分配合适的分数
摘要:本文将从实践案例角度为大家解读强化学习中的梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)。 本文分享自华为云社区《强化学习从基础到进阶-案例与实践[5]:梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)》,作者: 汀丶。 ......
避免梯度爆炸:让深度学习算法快速稳定地训练
[toc] 避免梯度爆炸:让深度学习算法快速稳定地训练 作为一名人工智能专家,程序员和软件架构师,我深刻理解深度学习算法在训练过程中可能会遇到的问题——梯度爆炸。因此,在本文中,我将结合自己的经验和知识,探讨如何避免梯度爆炸,让深度学习算法能够快速稳定地训练。 1. 引言 1.1. 背景介绍 随着人 ......
TensorFlow11.4 循环神经网络-梯度弥散与梯度爆炸
RNN并没有我们想象中的那么完美,虽然它的参数会比卷积神经网络少,但是它长时间的Training可能会出现Training非常困难的情况。 、优势函数、动作分配合适的分数(credit)
强化学习从基础到进阶-常见问题和面试必知必答[5]::梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit) ......
共轭梯度法对“正定矩阵”的求解与对“非正定矩阵”的求解的对比
众所周知,共轭梯度法可以很好的对正定矩阵进行求解,但是在计算过程中我们往往难以得到正定矩阵,因此很多时候在使用共轭梯度法时难以保证矩阵为正定,那么此时我们依然可以使用共轭梯度法进行近似计算,得到一个还不错的结果,本文就使用共轭梯度法分别对正定矩阵和非正定矩阵两种形式进行对比: 参考: 正定矩阵的生成 ......
Hessian Free Optimization——外国网友分享的“共轭梯度”的推导
外国网友分享的“共轭梯度”的推导: https://andrew.gibiansky.com/blog/machine-learning/hessian-free-optimization/ 系数矩阵为Hessian矩阵时的使用Pearlmutter trick的共轭梯度解法 Ax = b 的迭代解 ......
基于策略梯度的强化学习算法
[toc] 《基于策略梯度的强化学习算法》 引言 强化学习是一种通过不断地试错和调整策略来最大化长期奖励的学习技术。在强化学习中,智能体通过与环境交互来学习最优策略,并通过执行这些策略来获得奖励。本文将介绍一种基于策略梯度的强化学习算法,该算法将策略梯度用于优化智能体的动作选择。 技术原理及概念 1 ......