模型gscloud gdemv3 gdemv
行行AI人才直播第8期:新加坡国立大学在读博士生张傲《多模态大语言模型(MLLM)的简介及高效训练》
随着 ChatGPT 在各领域展现出非凡能力,多模态大型语言模型(MLLM)近来也成为了研究的热点,它利用强大的大型语言模型(LLM)作为“大脑”,可以执行各种多模态任务。更让人感慨的是,MLLM 展现出了传统方法所不具备的能力,比如能够根据图像创作故事,无需 OCR 的数学推理等,这为实现人工智能 ......
基于MRPC的BERT模型实战
[TOC] > 本项目根据MRPC数据集,首先对数据进行处理(包括对每句话进行分词操作和编码操作),然后创建BERT模型,接着根据Transformer结构(包括self-attention机制,attention_mask等),最终是二分类任务:判断两句话是否相连(这两句话是否可判断为同一句话), ......
NLP应用 | 保存checkpoint模型
**需求描述:** 当我们训练模型的时候,我们要训练很多训练步数,我们想要保存训练到一定阶段的checkpoint模型参数,并把这些checkpoint模型保存到一个指定的文件夹下。在文件夹下我们最多保存`keep_checkpoint_max`个checkpoint模型的文件。保存到`output ......
可视化模型地址
https://github.com/zhangti0708/bigdata-examples https://github.com/iGaoWei/BigDataView ......
AI重塑千行百业,华为云发布盘古大模型3.0和昇腾AI云服务
【中国,东莞,2023年7月7日】华为开发者大会2023(Cloud)7月7日在中国东莞正式揭开帷幕,并同时在全球10余个国家、中国30多个城市设有分会场,邀请全球开发者共聚一堂,就AI浪潮之下的产业新机会和技术新实践开展交流分享。 在7日下午举行的大会主题演讲中,华为常务董事、华为云CEO张平安重 ......
我用numpy实现了GPT-2,GPT-2源码,GPT-2模型加速推理,并且可以在树莓派上运行,读了不少hungging face源码,手动实现了numpy的GPT2模型
之前分别用numpy实现了mlp,cnn,lstm和bert模型,这周顺带搞一下GPT-2,纯numpy实现,最重要的是可在树莓派上或其他不能安装pytorch的板子上运行,生成数据 gpt-2的mask-multi-headed-self-attention我现在才彻底的明白它是真的牛逼,比ber ......
道德与社会问题简报 #4: 文生图模型中的偏见
**简而言之: 我们需要更好的方法来评估文生图模型中的偏见** ## 介绍 [文本到图像 (TTI) 生成](https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads) 现在非常流行,成千上万的 TTI 模型被上传 ......
大模型复现实践记录-在linux环境4090GPU(24G)
# chatglm-6b 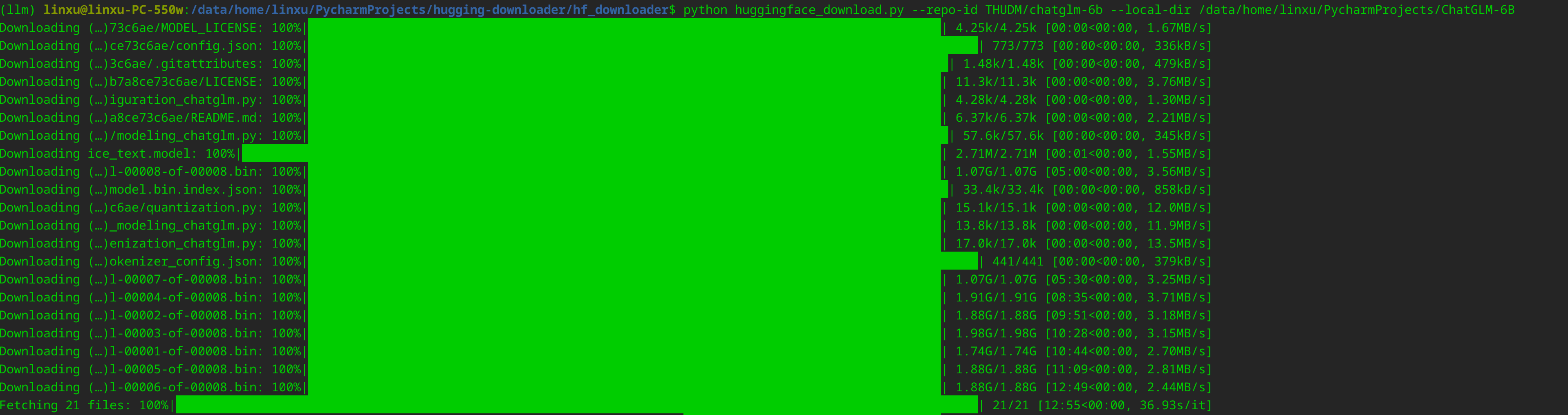 是反映两个随机变量之间关联程度的一个概念 它与相关性(correlation)有区别,常用的 ......
ARIMA模型,ARIMAX模型预测冰淇淋消费时间序列数据|附代码数据
全文下载链接:http://tecdat.cn/?p=22511 最近我们被客户要求撰写关于ARIMAX的研究报告,包括一些图形和统计输出。 标准的ARIMA(移动平均自回归模型)模型允许只根据预测变量的过去值进行预测 。 该模型假定一个变量的未来的值线性地取决于其过去的值,以及过去(随机)影响的值 ......
【视频】决策树模型原理和R语言预测心脏病实例
全文链接:https://tecdat.cn/?p=33128 原文出处:拓端数据部落公众号 分析师:Yudong Wan 决策树模型简介 决策树模型是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。与传统的线性回归 ......
基础大模型能像人类一样标注数据吗?
自从 ChatGPT 出现以来,我们见证了大语言模型 (LLM) 领域前所未有的发展,尤其是对话类模型,经过微调以后可以根据给出的提示语 (prompt) 来完成相关要求和命令。然而,直到如今我们也无法对比这些大模型的性能,因为缺乏一个统一的基准,难以严谨地去测试它们各自的性能。评测我们发给它们的指 ......
Qt+opencv dnn模块调用tensorflow模型
参考网址(1条消息) Qt+opencv dnn模块调用tensorflow模型_vs qt 调用 tensorflow_街道口扛把子的博客-CSDN博客代码地址:GitHub - Whu-wxy/Simple_Qt_opencv_dnn: Using deep learning model wit ......
python基础day39 生产者消费者模型和线程相关
如何查看进程的id号 进程都有几个属性:进程名、进程id号(pid >process id) 每个进程都有一个唯一的id号,通过这个id号就能找到这个进程 import os import time def task(): print("task中的子进程号:", os.getpid()) prin ......
Logistic回归模型,python
代码参考https://blog.csdn.net/DL11007/article/details/129204192?ops_request_misc=&request_id=&biz_id=102&utm_term=logistic%E6%A8%A1%E5%9E%8Bpython&utm_med ......
【AI实战】开源大语言模型LLMs汇总
大语言模型大语言模型(LLM)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。来自百度百科 发展历史 2020年9月,OpenAI授权微软使用GPT-3模型,微软成为全球首个 ......
开源可商用大模型再添重磅玩家——StabilityAI发布开源大语言模型StableLM
今天,Stability宣布开源StableLM计划,这是一个正在开发过程的大语言模型,但是它是开源可商用的模型。本文将对该模型做简单的介绍!本文来自DataLearner官方博客:开源可商用大模型再添重磅玩家——StabilityAI发布开源大语言模型StableLM | 数据学习者官方网站(Da ......
开源中英文大语言模型汇总
开源中英文大语言模型汇总 Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。 所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 AI 模型,发现其中的规律,可以根据提示 ......
能「说」会「画」, VisCPM:SOTA 开源中文多模态大模型
最近, 清华大学 NLP实验室、面壁智能、知乎联合在 OpenBMB 开源多模态大模型系列VisCPM,评测显示,VisCPM 在中文多模态开源模型中达到最佳水平。 VisCPM 是一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM- ......
逼近GPT-4!BLOOMChat: 开源可商用支持多语言的大语言模型
背景 SambaNova和Together这2家公司于2023.05.19开源了可商用的支持多语言的微调模型BLOOMChat。 SambaNova这家公司专注于为企业和政府提供生成式AI平台,Together专注于用开源的方式打造一站式的foundation model,赋能各个行业。 OpenA ......
开源中文大型语言模型(资源汇总
随时更新!汇总2023年开源的大型中文大规模语言模型,入选标准: 对中文支持能力强 模型规模 ≥ 1B 公布模型权重、推理代码 公布模型训练细节 Chinese-Vicuna 项目地址:https://github.com/Facico/Chinese-Vicuna 基座模型:LLaMA 7B 特点 ......
开源大模型新SOTA,支持免费商用,比LLaMA65B小但更强
号称“史上最强的开源大语言模型”出现了。 它叫Falcon(猎鹰),参数400亿,在1万亿高质量token上进行了训练。 最终性能超越650亿的LLaMA,以及MPT、Redpajama等现有所有开源模型。 一举登顶HuggingFace OpenLLM全球榜单: 除了以上成绩,Falcon还可以只 ......
截至2023年5月份目前业界支持中文大语言模型开源和商用许可协议总结
原文有模型链接与更新信息。 目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。 上图是Dat ......
MegEngine 使用小技巧:如何使用 MegCC 进行模型编译
本文将重点解析模型部署中的重要步骤之一-模型编译:编译 MegEngine 模型,生成运行这个模型对应的 Kernel 以及和这些 Kernel 绑定的模型。 ......
如何避免模型数据的偏差?
当数据集存在偏差时,训练出的模型可能会对某些类别或观点表现出倾向性,而忽略其他类别或观点。这种偏差可能会导致不公平的结果或误导性的决策。因此,消除训练数据中的偏差至关重要。 训练数据可能存在多种类型的偏差。以下是一些常见的数据偏差类型: 1. 标签偏差(Label Bias):标签偏差是指训练数据集 ......
开源大语言模型是否可以商用的调查报告
开源大语言模型是否可以商用的调查报告 0. 背景 1. 调查结果 1.1 基础大模型(LLM) 1.2 对话大模型(ChatLLM) 1.3 多模态对话大模型(MultiModal-ChatLLM) 2. 可商用开源模型总结 2.1 基础大模型(LLM) 2.2 对话大模型(ChatLLM) 0. ......
python基础 如何查看进程的id号、队列的使用(queue)、解决进程之间隔离关系、生产者消费者模型、线程
如何查看进程id号 进程都有几个属性:进程名、进程id号(pid-->process id)每一个进程都有一个唯一的id号, 通过这个id号就能找到这个进程 import os import time def task(): print("task中的子进程号:", os.getpid()) pri ......
数据密集型应用系统设计:数据模型与查询语言
1、现在大多数应用开发都采用面向对象的编程语言,由于兼容性问题,普遍对SQL数据模型存在抱怨:如果数据存储在关系表中,那么应用层代码中的对象与表、行和列的数据库模型之间需要一个笨拙的转换层。模型之间的脱离有时被称为阻抗失谐。 2、拥有地理区域和行业的标准化列表,并让用户从下拉列表或自动填充器中进行选 ......