模型yolov8 opencv yolov
《安富莱嵌入式周报》第316期:垂直降落火箭模型,超低噪声测量,开源电流探头,吸尘器BLDC,绕过TrustZone,提高频率计精度,CMSIS V6.0文档
周报汇总地址:http://www.armbbs.cn/forum.php?mod=forumdisplay&fid=12&filter=typeid&typeid=104 视频版: https://www.bilibili.com/video/BV1rz4y1H71w/ 1、基于罗氏线圈的开源电流 ......
Rabbitmq:消息队列介绍、Rabbitmq安装、 基于Queue实现生产者消费者模型、基本使用(生产者消费者模型)、消息安全之ack、 消息安全之durable持久化、发布订阅闲置消费、
[toc] ### 一、消息队列介绍 #### 1.1介绍 消息队列就是基础数据结构中的“先进先出”的一种数据机构。想一下,生活中买东西,需要排队,先排的人先买消费,就是典型的“先进先出” : can't open/read file: check file path/integrity 解决办法 很简单,参考python中 ......
JMM内存模型
JMM是定义程序中变量的访问规则,线程对于变量的操作只能在自己的工作内存中进行,而不能直接对主内存操作.由于指令重排序,读写的顺序会被打乱,因此JMM需要提供原子性,可见性,有序性保证. 随着CPU和内存的发展速度差异的问题,导致CPU的速度远快于内存,所以现在的CPU加入了高速缓存,高速缓存一般可 ......
语言模型在文本挖掘中的应用:如何通过数据挖掘和机器学习技术发现文本中的有价值的信息
[toc] 语言模型在文本挖掘中的应用:如何通过数据挖掘和机器学习技术发现文本中的有价值的信息 1. 引言 1.1. 背景介绍 随着互联网的快速发展,文本数据量不断增加,人们对文本数据的需求也越来越高。文本数据具有丰富的信息量,对于企业、政府、金融等各行业来说,都具有重要意义。但是,如何从大量的文本 ......
最佳实践|亚马逊可持续发展的架构模型
在过去的十年里面,亚马逊云科技一直都致力于帮助企业和开发者实现数字化转型,包括如何使用云技术帮助企业提高运营中资源利用率;如何通过云基础架构、容器、DevOps 进行业务的创新和敏捷性;未来的十年,亚马逊云科技将帮助开发者和企业开始新的可持续发展转型。让开发者可以使用相同的工具更专注于可持续性工作, ......
Bertviz: 在Transformer模型中可视化注意力的工具(BERT,GPT-2,Albert,XLNet,RoBERTa,CTRL,etc.)
BertViz BertViz是一个在Transformer模型中可视化注意力的工具,支持transformers库中的所有模型(BERT,GPT-2,XLNet,RoBERTa,XLM,CTRL等)。它扩展了Llion Jones的Tensor2Tensor可视化工具和HuggingFace的tr ......
最强NLP模型BERT可视化学习
2023年06月26日是自然语言处理(Natural Language Processing, NLP)领域的转折点,一系列深度学习模型在智能问答及情感分类等NLP任务中均取得了最先进的成果。近期,谷歌提出了BERT模型,在各种任务上表现卓越,有人称其为“一个解决所有问题的模型”。 BERT模型的核 ......
Python基于SVM和RankGauss的低消费指数构建模型
全文链接:https://tecdat.cn/?p=32968 原文出处:拓端数据部落公众号 分析师:Wenyi Shen 校园的温情关怀是智慧校园的一项重要内容。通过大数据与数据挖掘技术对学生日常校园内的消费信息进行快速筛选和比对,建立大数据模型,对校园内需要帮助的同学进行精准识别,为高校温情关怀 ......
R语言用灰色模型 GM (1,1)、神经网络预测房价数据和可视化|附代码数据
被客户要求撰写关于灰色模型的研究报告,包括一些图形和统计输出。 以苏州商品房房价为研究对象,帮助客户建立了灰色预测模型 GM (1,1)、 BP神经网络房价预测模型,利用R语言分别实现了 GM (1,1)和 BP神经网络房价预测可视化 由于房价的长期波动性及预测的复杂性,利用传统的方法很难准确预测房 ......
Hugging News #0626: 音频课程更新、在线体验 baichuan-7B 模型、ChatGLM2-6B 重磅发
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」,本期 Hugging News 有哪些有趣的消息,快来看看吧! ## 重要更新 ### 最新 ......
大模型微调技术LoRA与QLoRA
LoRA: Low-Rank Adaptation of Large Language Models 动机 大模型的参数量都在100B级别,由于算力的吃紧,在这个基础上进行所有参数的微调变得不可能。LoRA正是在这个背景下提出的解决方案。 原理 虽然模型的参数众多,但其实模型主要依赖低秩维度的内容( ......
多模态大语言模型 LlaVA 论文解读:Visual Instruction Tuning
 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatG... ......
OpenCV4.7+Contrib+VSCode安装
## 下载OpenCV和Contrib [https://opencv.org/releases/](https://opencv.org/releases/) [https://www.raoyunsoft.com/opencv/opencv_contrib/](https://www.raoyu ......
通用大模型如何突破垂直行业场景?
从京东离开后,周伯文已经很久没有这么兴奋了。 ChatGPT横空出世搅动乾坤,如同一声春雷惊醒各行各业的从业者,让他们都不约而同地听到,AGI走进现实的脚步声。 热潮之下,人们看到王慧文、王小川下场创业,也看到百度、阿里虎踞龙盘。周伯文作为IBM、京东两家大厂的AI研究院前院长,研究人工智能基础理论 ......
LLM-Blender:大语言模型排序融合框架
随着Alpaca, Vicuna, Baize, Koala等诸多大型语言模型的问世,研究人员发现虽然一些模型比如Vicuna的整体的平均表现最优,但是针对每个单独的输入,其最优模型的分布实际上是非常分散的,比如最好的Vicuna也只在20%的任务里比其他模型有优势。 有没有可能通过集成学习来综合诸 ......
本地部署开源大模型的完整教程:LangChain + Streamlit+ Llama
在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作的开发人员。 大型语言模型(llm)是指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型。这些模型使用广泛的数据集进行训练,这些数据集包括书籍、文章、 ......
Linux多线程12-生产者和消费者模型
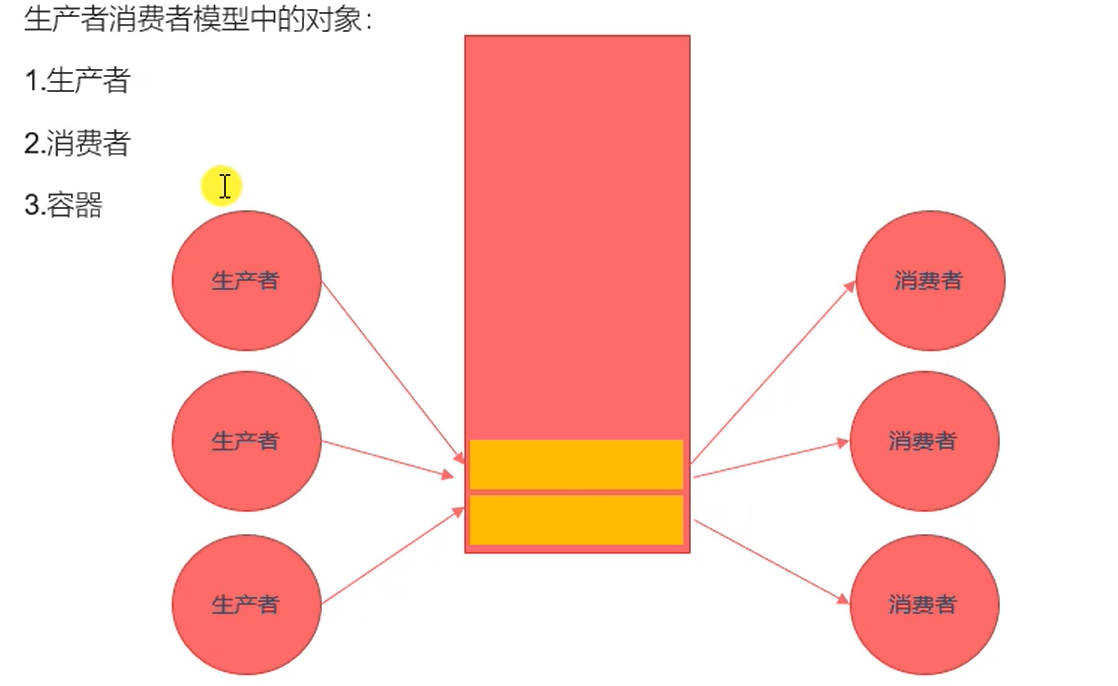 一个最简单的生产者消费者模型 ```c /* 生产者消费者模型(粗略版) */ #include #inc ......
R语言618电商大数据文本分析LDA主题模型可视化报告|附代码数据
原文链接:http://tecdat.cn/?p=1078 最近我们被客户要求撰写关于文本分析LDA主题模型的研究报告,包括一些图形和统计输出。 618购物狂欢节前后,网民较常搜索的关键词在微博、微信、新闻三大渠道的互联网数据表现,同时通过分析平台采集618相关媒体报道和消费者提及数据 社交媒体指数 ......
opencv学习笔记(十二)
harris角点检测: #角点检测 import cv2 import numpy as np """cv2.cornerHarris() img:数据类型为float32 bolckSize:角点检测中指定区域的大小 ksize:Sobel求导中使用的窗口大小,一般为3 K:取值参数为[0.04, ......
怎么让英文大预言模型支持中文?(一)继续预训练
代码已上传到github: https://github.com/taishan1994/chinese_llm_pretrained Part1前言 前面我们已经讲过怎么构建中文领域的tokenization: https://zhuanlan.zhihu.com/p/639144223 接下来我 ......
园子的商业化努力:今晚8点有一场直播《大模型训练数据的一些事》
今晚8点有一场直播《大模型训练数据的一些事》,欢迎大家加下面的企业微信(行行人才小秘书)到时观看直播。园子最近推出的直播是行行AI人才运营的主要内容,行行AI人才是园子商业化努力的重要一步,是园子和园子的天使投资方顺顺智慧成立新公司共同运营的新业务。 ......
构件组装模型
模型的过程是: 先进行需求分析和定义,接着是设计构件组装:在整体上考虑,建立构件库:根据构件标准获取或管理构件,构件应用程序 ,测试与发布。 优点是,易扩展、重用,成本低、灵活 缺点是,需要经验丰富的设计人员,强调重用可能牺牲性能指标,第三方构件不可控 ......
opencv学习笔记(十一)
傅里叶变换: 作用: 高频:变化剧烈的灰度分量,例如边界; 低频:变化缓慢的灰度分量,例如大海 滤波: 低通滤波器:只保留低频,会使图像模糊 高通滤波器:只保留高频,会使图像细节增强 opencv中主要就是 cv2.dft() 和c v2.idft() ,输入图像需要先转换为np.floa32的格式 ......
什么时候需要微调你的大模型(LLM)?
前言 在AI盛起的当下,各类AI应用不断地出现在人们的视野中,AI正在重塑着各行各业。相信现在各大公司都在进行着不同程度的AI布局,有AI大模型自研能力的公司毕竟是少数,对于大部分公司来说,在一款开源可商用的大模型基础上进行行业数据微调也正在成为一种不错的选择。 本文主要用于向大家讲解该如何微调你的 ......
一篇一个CV模型,第(1)篇:StyleGAN
写在前面: 虽说自己肯定对外宣称自己是搞CV的,但是其实在自己接近两年半(🐔)的研究生生涯中,也没有熟练掌握过很多个CV领域的模型,或者说是CV领域的概念。我认为这个东西是必须得补的,不然作为CV算法工程师是肯定要被淘汰的。目前激发自己研究和学习热情的最好方式还是经营自己小小的博客,因此想开一个系 ......
V模型
v模型就是测试贯穿始终的开发模型, 它是提前做测试计划, v模型分几个阶段 需求分析、概要设计、详细设计、编码 而对标的测试是 验收测试、系统测试,集成设计,单元测试。 概要设计主要是分子系统,所以集成测试就是测系统的各个调用接口。 ......
多分类模型训练使用交叉熵损失的一个注意的点
使用交叉熵损失的网络模型最后一层不要用softmax,交叉熵损失函数会在计算的时候做softmax,如果用了会导致模型训练异常, 如果模型最后一层有softmax,则损失函数要写成 loss_fun = nn.NLLLoss() x = model(data) loss = loss_fun(tor ......