爬虫httpclient https
Python爬虫-排行榜数据爬取
前言开始接触 CTF 网络安全比赛发现不会写 Python 脚本的话简直寸步难行……故丢弃 Java 学习下 Python 语言,但单纯学习语法又觉得枯燥……所以从 Python 爬虫应用实战入手进行学习 Python。本文将简述爬虫定义、爬虫基础、反爬技术 和 CSDN博客排行榜数据爬取实战。 网 ......
python爬虫算法深度优先遍历_爬虫基础 之深度优先,广度优先策略
1.深度优先递归方式; import re import requests headers = { 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrom ......
设置DefaultHttpClient和HttpClient的超时时间的方法
转自:https://blog.csdn.net/sdujava2011/article/details/38921019 DefaultHttpClient超时设置: 1.其实是在HttpConnectionParams里设置的。我自己写了一个继承DefaultHttpClient的类,以后使用用 ......
HTTPS加密套件的笔记
本文于2016年5月份完成,发布在个人博客网站上。 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来。 按照如下配置(适用于Tomcat 7.0.x),为Tomcat启用了HTTPS协议,用户访问站点时是否就安全了呢? <!-- HTTP通道,跳转至8443端口 --> ......
爬虫01
微服务学的蛮多的 笔记没传 就这样吧 爬虫 基础01 1.爬虫分类 通用爬虫: 聚焦爬虫 功能爬虫 增量式爬虫 分布式爬虫 2.requests基础操作 1.环境安装 案例1 搜狗首页数据和持续存储 import requests url = 'https://www.sogou.com/' r = ......
指定url和深度的广度优先算法爬虫的python实现
广度优先算法介绍 整个的广度优先爬虫过程就是从一系列的种子节点开始,把这些网页中的"子节点"(也就是超链接)提取出来,放入队列中依次进行抓取。被处理过的链接需要放 入一张表(通常称为Visited表)中。每次新处理一个链接之前,需要查看这个链接是否已经存在于Visited表中。如果存在,证明链接已经 ......
始智AI —— https://wisemodel.cn/ —— 试用
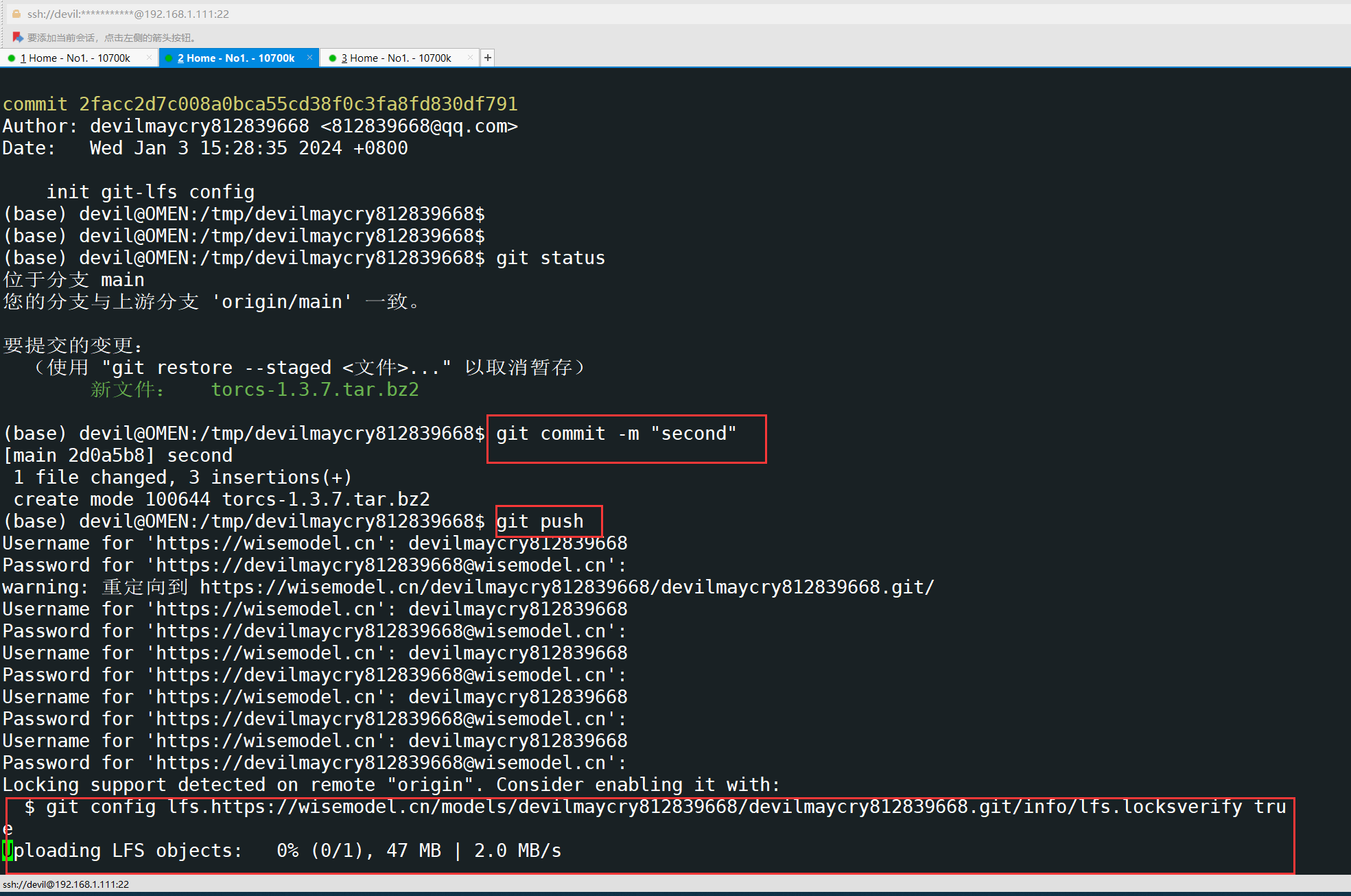 ......
自签名证书与Nginx配置Https证书
0.背景 公私钥、证书体系、Https等基础知识。 这个之前有写过ppt,空了我编辑成文章传上来,再更新这里。 1.密钥及证书角色 1.1 CA 以RSA为例 该环节,模拟自己作为CA,生成ca的私钥和根证书。 1.1.1 私钥生成 openssl genrsa -out ca-private.ke ......
前端与爬虫
搜索爬虫, 我们会搜到一大堆 Python 相关的结果 问题: 爬虫和前端有关系吗? 爬虫是什么 爬虫程序是一种计算机程序,旨在通过执行自动化或重复性任务来模仿或替代人类的操作。 爬虫程序执行任务的速度和准确性比真实用户高得多。爬虫程序类型众多,可执行各种任务,并且爬虫程序在互联网流量中的比重也越来 ......
pnpm : 无法加载文件 路径因为在此系统上禁止运行脚本 。有关详细信息,请参阅 https:/go.microsoft.com/fwl ink/?LinkID=135170 中的 about_Execution_Policies。 所在位置 行:1 字符: 1
在vscode命令行输入npm i -D @types/wechat-miniprogram @uni-helper/uni-app- 报如下错误: pnpm : 无法加载文件 C:\Users\Administrator\AppData ** ** \Roaming\npm\pnpm.ps1,因为 ......
01-认识爬虫
requests模块快速使用 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib(内置模块),requests模块的api更加便捷(本质就是封装了urllib3) # 注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后 ......
02-爬虫的高阶使用
代理池的搭建 # 搭建步骤 -1、git clone git@github.com:jhao104/proxy_pool.git -2、在pycharm中打开项目 -3、创建虚拟环境,并且安装依赖 pip install -r requirements.txt -4、修改配置文件:DB_CONN = ......
python爬虫环境配置
环境配置 python3/请求库/解析库/数据库/存储库/web库/app爬取库/爬虫框架库 python3 win11下可以直接商店下载了( Linux下apt-get install python3 请求库 requests pip3 install requests selenium pip ......
07--爬虫入门概念
一 web请求全过程剖析 我们浏览器在输入完网址到我们看到网页的整体内容, 这个过程中究竟发生了些什么? 我们看一下一个浏览器请求的全过程 接下来就是一个比较重要的事情了. 所有的数据都在页面源代码里么? 非也~ 这里要介绍一个新的概念 那就是页面渲染数据的过程, 我们常见的页面渲染过程有两种 服务 ......
【Python爬虫课程设计】大数据分析——东方财富石头科技股市数据分析
一、选题课程背景 在当今信息化时代,数据已成为驱动各行各业发展的重要力量。股市作为经济的晴雨表,其数据更是备受关注。东方财富网作为国内知名的财经网站,拥有海量的股市数据。随着大数据技术的不断发展,数据在各行各业的应用越来越广泛。股市作为经济的核心,其数据的价值不言而喻。然而,获取股市数据并非易事,尤 ......
爬虫作业
import requests url = 'https://www.bing.com' for i in range(20): response = requests.get(url) print(f"第{i+1}次访问") print(f'Response status: {response.s ......
Web服务器启用HTTPS的配置方法
本文于2016年3月完成,发布在个人博客网站上。 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来。 nginx的配置方法 可以参考Jerry Qu的本博客 Nginx 配置之完整篇。 Tomcat的配置方法 以Java语言实现的Connector为例,介绍配置方法。 创 ......
httpclient
java-httpclient 1.maven <!-- 主要的jar--> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</v ......
【python爬虫课程设计】大数据分析——有多少人花时间通过身体测量来思考自己的健康状况
一、选题背景介绍 在现代快节奏的生活中,越来越多的人开始关注自己的健康状况,并采取积极的措施来改善和维持健康。体重是一个重要的身体指标,对于评估健康状况和制定健康计划具有重要意义。 通过定期测量体重,人们可以了解自己的体重变化趋势,并将其与健康目标相比较。体重的增加或减少可能与饮食、运动、代谢等因素 ......
【Python爬虫课程设计】招聘网站数据分析与可视化
一、选题背景 随着互联网的快速发展和信息化时代的到来,招聘网站成为求职者和招聘公司之间最重要的信息交流平台之一。招聘网站上聚集了大量的职位信息、薪资数据和公司信息,这些数据蕴含着丰富的招聘市场和就业趋势的信息,对求职者和招聘公司都具有重要的参考价值。然而,由于招聘网站上的数据量庞大且复杂,求职者和招 ......
大数据分析与可视化 之 猫眼电影爬虫
大数据分析与可视化 之 猫眼电影爬虫 import random import time import re import requests import csv class MaoyanSpider(object): # 初始化 # 定义初始页面url def __init__(self): se ......
大数据分析与可视化 之 百度图片爬虫
大数据分析与可视化 之 百度图片爬虫 import requests import re from urllib import parse import os import time # Import the time module class BaiduImageSpider(object): d ......
大数据分析与可视化 之 百度贴吧爬虫
大数据分析与可视化 之 百度贴吧爬虫 import csv import datetime import json from urllib import request, parse import time import random from fake_useragent import UserA ......
大数据分析与可视化 之 小说爬虫类
大数据分析与可视化 之 小说爬虫类 import random import requests from lxml import etree import time class WebScraper: def __init__(self, url,output_file): self.url = u ......
大数据分析与可视化 之 实验01 Python爬虫
实验01 Python爬虫 实验学时:2学时 实验类型:验证 实验要求:必修 一、实验目的 理解爬虫技术 掌握正则表达式、网络编程 掌握re、socket、urllib、requests、lxml模块及其函数的使用 二、实验要求 分析所需爬取信息网页的源代码,使用re、socket、urllib、r ......
【Python爬虫课程设计】rottentomatoes爬取+数据可视化
一、选题背景 选择此选题的原因是为了进行电影数据的分析。电影作为一种重要的文化娱乐形式,对社会、经济和文化等方面都有着重要的影响。通过对电影数据的分析,可以揭示电影产业的发展趋势、观众喜好、电影市场的竞争情况等,为电影行业的决策制定提供依据。 二、主题式网络爬虫设计方案 1.主题式网络爬虫名称 Ro ......
【Python爬虫课程设计】--股票数据爬取+数据分析
一、选题课程背景 随着互联网技术的发展和信息爆炸的时代,人们对于获取和分析海量数据的需求日益增长。股票市场作为全球经济的重要风向标,其数据信息的获取和分析对于投资者、研究人员以及企业决策者具有重要的参考价值。然而,传统的股票数据分析方法往往受到数据来源限制和数据处理能力的制约,无法充分利用互联网上的 ......
【python爬虫课程设计】天气预报——分类数据爬取+数据可视化
一、选题的背景 随着人们对天气的关注逐渐增加,天气预报数据的获取与可视化成为了当今的热门话题,天气预报我们每天都会关注,天气情况会影响到我们日常的增减衣物、出行安排等。每天的气温、相对湿度、降水量以及风向风速是关注的焦点。通过Python网络爬虫爬取天气预报让我们快速获取和分析大量的天气数据,并通过 ......
【Python高级应用课程设计】——腾讯课堂爬虫数据可视化
一、选题背景 随着互联网的快速发展,在线教育已经成为越来越多人获取知识和技能的重要途径。其中,腾讯课堂作为国内知名的在线教育平台之一,提供了丰富的课程资源和学习机会。然而,对于广大学习者来说,如何快速有效地获取和筛选这些课程信息是一个重要的问题。此外,对于教育机构和课程提供者,如何对课程数据进行深入 ......