sqlalchemy模型flask model
实用模型推荐(三)语音转文本模型:whisper
1.开原地址:https://github.com/openai/whisper https://github.com/guillaumekln/faster-whisper 2.使用场景:语音转文字 3.api封装: import os import uvicorn from fastapi im ......
实用模型推荐(二)中译英翻译模型:opus-mt-zh-en
1.开源地址:https://huggingface.co/Helsinki-NLP/opus-mt-zh-en 2.使用场景:中译英,多模型场景的中英转换 3.API封装 import uvicorn from fastapi import FastAPI from loguru import l ......
LLaMA模型微调版本 Vicuna 和 Stable Vicuna 解读
相似度,文本向量化:text2vec-base-chinese
1.开源地址:https://github.com/shibing624/text2vec 2.使用场景:文本相似度计算,文本转指令 3.API封装: import uvicorn from fastapi import FastAPI from loguru import logger from ......
phi-1:高质量小数据小模型逆袭大模型
人工智能的三个核心要素是算力、算法和数据,这是大多数人在初识人工智能时都会接触到的一个观点。不过,在深入阐述该观点时,很多材料都倾向于解释数据「大」的一面,毕竟当前的大模型一直在由不断增加的「大数据」来推动,而且这条路似乎还没有走到极限。 不过,随着数据获取难度增加以及算力增长出现瓶颈,单纯追求「大 ......
LangKit:大语言模型界的“安全管家”
ChatGPT等大语言模型一直有生成虚假信息、数据隐私、生成歧视信息等难题,阻碍了业务场景化落地。为了解决这些痛点并增强大语言模型的安全性,AI和数据监控平台WhyLabs推出了LangKit。(开源地址:https://github.com/whylabs/langkit) LangKit提供文本 ......
《安富莱嵌入式周报》第316期:垂直降落火箭模型,超低噪声测量,开源电流探头,吸尘器BLDC,绕过TrustZone,提高频率计精度,CMSIS V6.0文档
周报汇总地址:http://www.armbbs.cn/forum.php?mod=forumdisplay&fid=12&filter=typeid&typeid=104 视频版: https://www.bilibili.com/video/BV1rz4y1H71w/ 1、基于罗氏线圈的开源电流 ......
Rabbitmq:消息队列介绍、Rabbitmq安装、 基于Queue实现生产者消费者模型、基本使用(生产者消费者模型)、消息安全之ack、 消息安全之durable持久化、发布订阅闲置消费、
[toc] ### 一、消息队列介绍 #### 1.1介绍 消息队列就是基础数据结构中的“先进先出”的一种数据机构。想一下,生活中买东西,需要排队,先排的人先买消费,就是典型的“先进先出” 
BertViz BertViz是一个在Transformer模型中可视化注意力的工具,支持transformers库中的所有模型(BERT,GPT-2,XLNet,RoBERTa,XLM,CTRL等)。它扩展了Llion Jones的Tensor2Tensor可视化工具和HuggingFace的tr ......
最强NLP模型BERT可视化学习
2023年06月26日是自然语言处理(Natural Language Processing, NLP)领域的转折点,一系列深度学习模型在智能问答及情感分类等NLP任务中均取得了最先进的成果。近期,谷歌提出了BERT模型,在各种任务上表现卓越,有人称其为“一个解决所有问题的模型”。 BERT模型的核 ......
Python基于SVM和RankGauss的低消费指数构建模型
全文链接:https://tecdat.cn/?p=32968 原文出处:拓端数据部落公众号 分析师:Wenyi Shen 校园的温情关怀是智慧校园的一项重要内容。通过大数据与数据挖掘技术对学生日常校园内的消费信息进行快速筛选和比对,建立大数据模型,对校园内需要帮助的同学进行精准识别,为高校温情关怀 ......
R语言用灰色模型 GM (1,1)、神经网络预测房价数据和可视化|附代码数据
被客户要求撰写关于灰色模型的研究报告,包括一些图形和统计输出。 以苏州商品房房价为研究对象,帮助客户建立了灰色预测模型 GM (1,1)、 BP神经网络房价预测模型,利用R语言分别实现了 GM (1,1)和 BP神经网络房价预测可视化 由于房价的长期波动性及预测的复杂性,利用传统的方法很难准确预测房 ......
Hugging News #0626: 音频课程更新、在线体验 baichuan-7B 模型、ChatGLM2-6B 重磅发
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」,本期 Hugging News 有哪些有趣的消息,快来看看吧! ## 重要更新 ### 最新 ......
大模型微调技术LoRA与QLoRA
LoRA: Low-Rank Adaptation of Large Language Models 动机 大模型的参数量都在100B级别,由于算力的吃紧,在这个基础上进行所有参数的微调变得不可能。LoRA正是在这个背景下提出的解决方案。 原理 虽然模型的参数众多,但其实模型主要依赖低秩维度的内容( ......
多模态大语言模型 LlaVA 论文解读:Visual Instruction Tuning
 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatG... ......
Pytorch | 输入的形状为[seq_len, batch_size, d_model]和 [batch_size, seq_len, d_model]的区别
首先导入依赖的torch包。 ```python import torch ``` 我们设: + seq_len(序列的最大长度):5 + batch_size(批量大小):2 + d_model(每个单词被映射为的向量的维度):10 + heads(多头注意力机制的头数):5 + d_k(每个头的 ......
通用大模型如何突破垂直行业场景?
从京东离开后,周伯文已经很久没有这么兴奋了。 ChatGPT横空出世搅动乾坤,如同一声春雷惊醒各行各业的从业者,让他们都不约而同地听到,AGI走进现实的脚步声。 热潮之下,人们看到王慧文、王小川下场创业,也看到百度、阿里虎踞龙盘。周伯文作为IBM、京东两家大厂的AI研究院前院长,研究人工智能基础理论 ......
flask中添加路由的方式
在Flask中,添加路由有两种方式:(一般情况下都是用第一种方式) 方式一:常见的装饰器模式 @app.route("/") def index(): return "Hello World" 方式二:通过阅读装饰器模式添加路由的源码发现 def route(self, rule, **option ......
LLM-Blender:大语言模型排序融合框架
随着Alpaca, Vicuna, Baize, Koala等诸多大型语言模型的问世,研究人员发现虽然一些模型比如Vicuna的整体的平均表现最优,但是针对每个单独的输入,其最优模型的分布实际上是非常分散的,比如最好的Vicuna也只在20%的任务里比其他模型有优势。 有没有可能通过集成学习来综合诸 ......
flask中关于配置文件写法
关于Flask中的配置文件有多种写法。 一、通过from_object写入 项目根目录下创建一个settings.py配置文件,代码如下 class BaseConfig(object): DEBUG = True SECRET_KEY = "fsdajklfjdsalk1654356" class ......
本地部署开源大模型的完整教程:LangChain + Streamlit+ Llama
在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作的开发人员。 大型语言模型(llm)是指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型。这些模型使用广泛的数据集进行训练,这些数据集包括书籍、文章、 ......
Linux多线程12-生产者和消费者模型
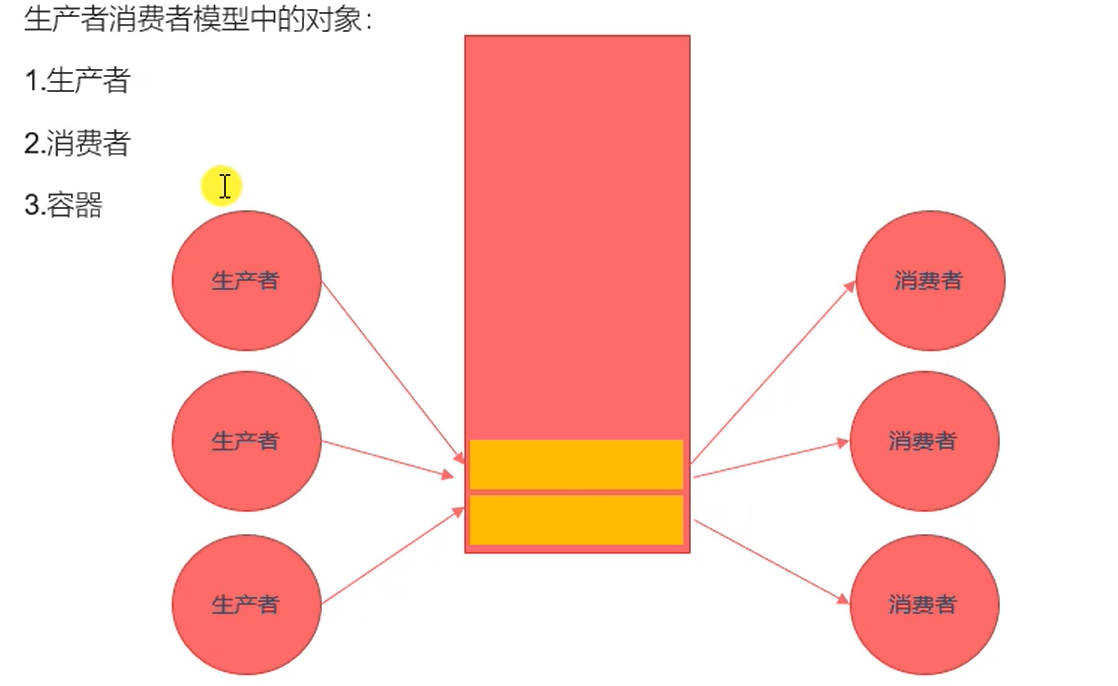 一个最简单的生产者消费者模型 ```c /* 生产者消费者模型(粗略版) */ #include #inc ......
R语言618电商大数据文本分析LDA主题模型可视化报告|附代码数据
原文链接:http://tecdat.cn/?p=1078 最近我们被客户要求撰写关于文本分析LDA主题模型的研究报告,包括一些图形和统计输出。 618购物狂欢节前后,网民较常搜索的关键词在微博、微信、新闻三大渠道的互联网数据表现,同时通过分析平台采集618相关媒体报道和消费者提及数据 社交媒体指数 ......
怎么让英文大预言模型支持中文?(一)继续预训练
代码已上传到github: https://github.com/taishan1994/chinese_llm_pretrained Part1前言 前面我们已经讲过怎么构建中文领域的tokenization: https://zhuanlan.zhihu.com/p/639144223 接下来我 ......