样本zero-shot learning zero
FOSTER:Feature Boosting and Compression for Class-Incremental Learning论文阅读笔记
## 摘要 先前的类增量学习方法要么难以在稳定性-可塑性之间取得较好的平衡,要么会带来较大的计算/存储开销。受gradient boosting的启发,作者提出了一种新型的两阶段学习范式FOSTER,以逐步适应目标模型和先前的集合模型之间的残差,使得该模型能够自适应地学习新的类别。具体来说,作者首先 ......
Orangepi.Zero2.IR 香橙派02的红外操作踩坑指南
最近拿出了我吃灰已久的香橙派 zero2,想着它有着红外功能,刚好最近买了一些红外遥控器,想着做些好玩的红外功能。 首先是安装新系统,装的armbian 最新的ubuntu 22.04。搜索一下 /dev 文件夹 ,发现了 lirc0 这个设备,这个就是我要找的红外设备了。 然后去 lirc 官网 ......
加速体细胞突变检测分析流程-系列2(ctDNA等高深度样本)
Sentieon●体细胞变异检测系列-2 Sentieon 致力于解决生物信息数据分析中的速度与准确度瓶颈,通过算法的深度优化和企业级的软件工程,大幅度提升NGS数据处理的效率、准确度和可靠性。 针对体细胞变异检测,Sentieon软件提供两个模块:TNscope和TNhaplotyer2。 TNs ......
go-zero 源码——syncx/singleflight
```go package syncx import "sync" /** * [rtfsc] * 主题: singleflight.go * 摘要: 相同的任务,只需要一个人执行完成,剩下的享受成果即可 * 功能: 多个协程执行同一个任务时,只需要一个执行成功,其余的共享结果即可 * 应用: 高并 ......
go-zero 源码——syncx/limit
rtfsc: read the fucking source code 以下为源码注释: ```go package syncx import ( "errors" "github.com/zeromicro/go-zero/core/lang" ) /** * [rtfsc] * 主题: limi ......
随机现象之: 样本空间的“分割”•随机事件(结果集)的“分布”•样本空间事件域(可测度性, 集合运算封闭性)
样本空间的分割:i~[1, n], 有A1, A2,…,An两两相互不相容,且 A1+A2+…+An = Omega(样本空间, 全集) 随机事件的概率分布:对随机事件E={e1, e2,…en}, 有: * e1,e2,…,en两两互不相容,且 P(e1) + P(e2) + … + P(en) ......
Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning---reading
# Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning reading - 攻击目标 - 安全破坏 - 完整性破坏: 逃避检测,而不影响正常的系统运行 - 可用性破坏: 使得合法用户不能正常使用系统 - 隐私 ......
Spectrum Random Masking for Generalization in Image-based Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! ......
COMP9444 Neural Networks and Deep Learning
COMP9444 Neural Networks and Deep LearningTerm 2, 2023Project 1 - Characters and Hidden UnitDynamicsDue: Wednesday 5 July, 23:59 pmMarks: 20% of final ......
医学案例|配对样本t检验
一、案例介绍 为比较两种方法对乳酸饮料中脂肪含量测定结果是否不同,随机抽取了10份乳酸饮料制品,非别用脂肪酸水解法和哥特里-罗紫法测定,其结果图1。问两种测定结果是否不同? 图1 二、问题分析 本案例的分析目的是比较两种方法对同一批样本检测结果是否存在差异,属于对同一样本进行不同处理比较,所以可以使 ......
单样本t检验
一、案例介绍 某医生测量了36名从事铅作业男性工人的血红蛋白含量,算得其均数为130.83g/L,标准差为25.74g/L。问,从事铅作业男性工人的血红蛋白含量均数是否不等于正常男性的均数140g/L?部分数据如图1: 图1 二、问题分析 检验样本均数与已知总体均数的是否有差别,即判断36名从事铅作 ......
CVPR23 | 浙大、NTU提出零样本通用分割框架PADing
前言 本文分享论文【Primitive Generation and Semantic-related Alignment for Universal Zero-Shot Segmentation】,由浙大、NTU提出零样本通用分割框架PADing。 本文转载自我爱计算机视觉 仅用于学术分享,若侵权 ......
Faster sorting algorithms discovered using deep reinforcement learning
## 摘要: - `AlphaDev`模型优化排序算法,将排序算法提速70%。通过强化学习,AlphaDev发现了更加有效的算法,直接超越了科学家和工程师们几十年来的精心打磨。现在,新的算法已经成为两个标准C++编码库的一部分,每天都会被全球的程序员使用数万亿次。 ## 介绍 - 优化目标为排序算法 ......
LEARNING TO SAMPLE WITH LOCAL AND GLOBAL CONTEXTS FROM EXPERIENCE REPLAY BUFFERS
 **发表时间:**2021(ICLR 2021) **文章要点:**这篇文章想说,之前的experience r ......
How about learning medical treatment model
> Learning medical treatment models can be a great way to gain a deeper understanding of how diseases are diagnosed and treated. There are many differ ......
Reinforcement learning
如图1所示,强化学习中,state是环境的状态,就是observation。 图1 强化学习 一、Policy based approach learning an actor The policy based approach is to learn an actor (agent or poli ......
Self-attention with Functional Time Representation Learning
[TOC] > [Xu D., Ruan C., Kumar S., Korpeoglu E. and Achan K. Self-attention with functional time representation learning. NIPS, 2019.](http://arxiv.or ......
论文阅读 | Soteria: Provable Defense against Privacy Leakage in Federated Learning from Representation Perspective
Soteria:基于表示的联邦学习中可证明的隐私泄露防御https://ieeexplore.ieee.org/document/9578192 # 3 FL隐私泄露的根本原因 ## 3.1 FL中的表示层信息泄露 **问题设置** 在FL中,有多个设备和一个中央服务器。服务器协调FL进程,其中每个 ......
悟空派WuKongPi/香橙派orangepi zero全志H3折腾记录(②kernel移植)
接上一节,这节开始移植内核。 首先获取一下内核源码,这里仍然使用香橙派的源码 git clone https://github.com/orangepi-xunlong/linux-orangepi.git 进入kernel根目录并切换到orangepi zero使用的分支 git checkout ......
Getting Zero(Bfs)
Getting Zero time limit per test 2 seconds memory limit per test 256 megabytes input standard input output standard output Suppose you have an integer ......
Proj. CAR Paper Reading: Augmenting Decompiler Output with Learned Variable Names and Types
## Abstract 背景: 1. decompilers难以恢复注释、variable names, custom variable types 本文: 工具:DIRTY((DecompIled variable ReTYper) 方法: postprocesses decompiled fil ......
EulerNet Adaptive Feature Interaction Learning via Euler’s Formula for CTR Prediction
[TOC] > [Tian Z., Bai T., Zhao W., Wen J. and Cao Z. Eulernet: Adaptive feature interaction learning via euler’s formula for ctr prediction. SIGIR, 20 ......
Welcome To Learn Dapper
Welcome To Learn Dapper This site is for developers who want to learn how to use Dapper - The micro ORM created by the people behind Stack Overflow. W ......
《深度学习(deep learning)》pdf电子书免费下载
《深度学习》由全球知名的三位专家Ian Goodfellow、Yoshua Bengio 和Aaron Courville撰写,是深度学习领域奠基性的经典教材。全书的内容包括3个部分:第 1部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第 2部分系统深入地讲解现今已成熟的深度学习 ......
COMP9417 - Machine Learning
COMP9417 - Machine LearningHomework 1: Regularized Regression & NumericalOptimizationIntroduction In this homework we will explore some algorithms for ......
选修-4-Optimization for Deep Learning
# 1. Some Nitations 在本小节开始之前,需要知道的符号含义. 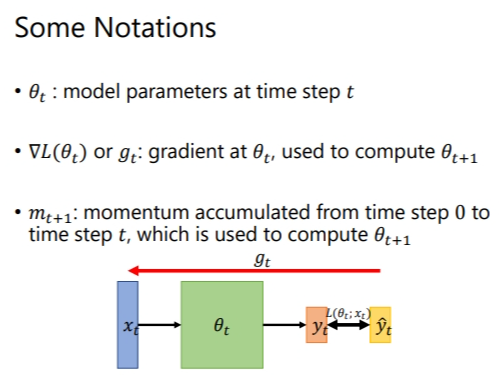 # 2. What is ......
【笔记】learning git branching
git图是由子节点指向父节点(可能有多个父节点) ### git commit  ### git branch ![ ......
了解基于模型的元学习:Learning to Learn优化策略和Meta-Learner LSTM
摘要:本文主要为大家讲解基于模型的元学习中的Learning to Learn优化策略和Meta-Learner LSTM。 本文分享自华为云社区《深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM》,作者:汀丶 。 1. ......
深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM
# 深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM # 1.Learning to Learn Learning to Learn by Gradient Descent by Gradient Descent 提出了 ......