样本zero-shot learning zero
Learning hard C#学习笔记——读书笔记 08
这篇文章介绍了什么是事件,以及如何在C#中使用事件。事件是在生活中发生的事情,它涉及到事件的发布者和事件的订阅者,当事件发生时,发布者会发布消息,订阅者会接收通知并做出相应的处理。在C#中,我们可以使用event关键字定义一个事件,然后订阅和取消事件的方法与委托链的取消和链接相同。 ......
IJCAI 2023 | 腾讯优图实验室入选论文解读,含小样本学习方法、玻璃物体分割、RSI变化检测研究方向
前言 近日,IJCAI 2023(International Joint Conference on Artificial Intelligence)国际人工智能联合大会公布了录用结果。本届会议共有4566篇投稿,接收率为15%。作为当前全球最负盛名的 AI 学术会议之一,IJCAI将于今年 8月在 ......
手机免root安装最新青龙面板(非Alpine term | Zero term软件)
##### 使用软件:Termux ##### 可以用于任何支持qemu虚拟机的环境、APP ##### 制作了基本的系统环境、开发环境和青龙面板环境、多个虚拟机,按需求下载 ##### 官方网站:[https://api.wer.plus](https://api.wer.plus "https: ......
Improved deep reinforcement learning for robotics through distribution-based experience retention
 **发表时间:**2016(IROS 2016) **文章要点:**这篇文章提出了experience repl ......
ChatGPT技巧之Few-Shot Chain of Thought(少样本思维链)
**Few-Shot Chain of Thought(少样本思维链)** 这个技巧使用的关键就是在给AI提供示例的同时解释示例的逻辑。 比如这样 - 这组数字中的奇数加起来得到一个偶数:4、8、9、15、12、2、1。A:将所有奇数相加(9、15、1),得到25。答案是False。 - 这组数字中 ......
Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection(1)
MonoCon的网络结构和MonoDLE几乎一样,只是添加了辅助学习(Auxiliary Learning, AL)模块. 网络结构如上图所示,对于3D目标检测来说,预测2D框是没有必要的,但是MonoCon在训练阶段仍然计算了2D框的损失函数,但是在推理的时候,并不会预测2D框,这就是所谓的辅助学 ......
深入Scikit-learn:掌握Python最强大的机器学习库
> 本篇博客详细介绍了Python机器学习库Scikit-learn的使用方法和主要特性。内容涵盖了如何安装和配置Scikit-learn,Scikit-learn的主要特性,如何进行数据预处理,如何使用监督学习和无监督学习算法,以及如何评估模型和进行参数调优。本文旨在帮助读者深入理解Scikit- ......
The importance of experience replay database composition in deep reinforcement learning
 **发表时间:**2015(Deep Reinforcement Learning Workshop, NIPS ......
CF1184A3 Heidi Learns Hashing (Hard)
令 $c_i={w_1}_i-{w_2}_i$,相当于找到 $(r,P)$,满足: $$\sum\limits_{i=0}^nc_ir^i\equiv 0 \pmod P$$ 把这个东西写成多项式形式,令 $f(x)=\sum\limits_{i=0}^nc_ix^i$,即找到一个 $(r,P)$, ......
基于LSTM深度学习网络的人员行走速度识别matlab仿真,以第一视角视频为样本进行跑或者走识别
1.算法理论概述 人员行走速度是衡量人体运动能力和身体健康的重要指标之一。目前,常见的人员行走速度识别方法主要基于传感器或摄像头获取的数据,如加速度计数据、GPS数据和视频数据等等。其中,基于视频数据的方法因为其易于获取和处理而备受关注。但是,传统的基于特征提取的方法往往需要手工选择特征并进行复杂的 ......
Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)论文阅读
深度估计问题 从输入的单目或双目图像,计算图像物体与摄像头之间距离(输出距离图),双目的距离估计应该是比较成熟和完善,但往单目上考虑主要还是成本的问题,所以做好单目的深度估计有一定的意义。单目的意思是只有一个摄像头,同一个时间点只有一张图片。就象你闭上一只眼睛,只用一只眼睛看这个世界的事物一样,距离 ......
Selective Experience Replay for Lifelong Learning
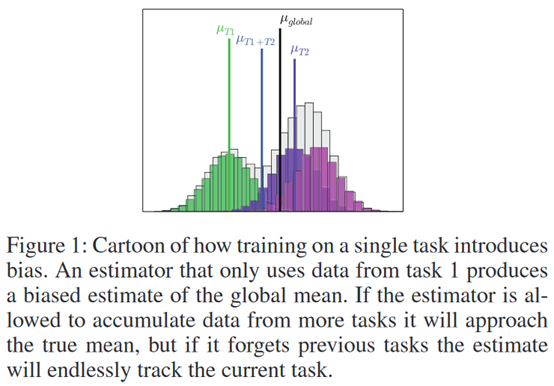 **发表时间:**2018(AAAI 2018) **文章要点:**这篇文章想解决强化学习在学多个任务时候的遗忘 ......
模型训练——样本选择,训练方式,loss等
数据采样第一阶段预训练时,通过 是否点击、点击位次等,将曝光点击率大于一定阈值Query-POI对 作为正样本。负样本采样上,skip-above采样策略将位于点击POI之前 & 点击率小于阈值的POI,这样的query-POI对 作为负样本。此外,也可以随机负采样补充简单负例。 欠采样 过采样 样 ......
YOLOX中的SimOTA正负样本分配策略
一、样本匹配 YOLO系列算法一般的网络输出如图1所示: 图1 输出为80*80*85的Tensor(以COCO数据集为例),即在80*80的尺度上,每一个点位都输出一个长度85的Tensor,85意为80个类别信息、1个box坐标信息以及1个置信度信息。对于yolov5来说,每一个点位上有3个不同 ......
通过docker安装的jira提示We've detected a potential problem with JIRA's Dashboard configuration that your administrator can correct. Click here to learn more
正常通过docker安装jira后,访问是不会出问题的 但是如果使用nginx代理后,就是在nginx里配置了proxy_pass http://localhost:2800 再访问后,就会报错We've detected a potential problem with JIRA's Dashbo ......
代码实现-小样本-RN
>此篇为《Learning to Compare Relation Network for Few-Shot Learning》 只实现了基于Omniglot数据集的小样本代码 datas为数据集 models为训练好的模型 venv为配置文件 下面的py文件是具体实现代码 ### 1.结构 ![i ......
Large Language Models are Zero-Shot Reasoners
[TOC] > [Kojima T., Gu S. S., Reid M., Matsuo Y. and Iwasawa Y. Large language models are zero-shot reasoners. NIPS, 2022.](http://arxiv.org/abs/2205. ......
go-zero插件goctl-swagger的坑——第二弹
*截至本文发布,直接安装`goctl-swagger`还无法解决go-zero .api文件引入问题* 该文主要是记录在使用过程中遇到的问题和解决思路,不做详细教学使用。 ## 问题 在[go-zero插件goctl-swagger的坑](https://www.cnblogs.com/eatfis ......
Paper Reading: Exploratory Undersampling for Class-Imbalance Learning
本文是不平衡分类问题的经典论文,文中提出了 2 种不平衡集成学习模型都是简单而有效的 baseline 方法。 EasyEnsemble 方法直接对多数类样本进行采样得到几个子集,并使用这些子集分别训练基分类器。BalanceCascade 是使用训练好的分类器来指导后续分类器的采样过程,即在上一个... ......
Meta Learning(元学习)
Meta Learning(元学习) 元学习:学习如何学习:也是找一个函数,这个函数是学习算法,输出训练好的模型 假如教机器做了训练影像分类、影像识别等任务的模型,再去教机器训练语音识别的模型时,他可能学的更好,虽然语音和影像没有什么关系,但机器在多次的学习训练其他模型过程中,可能学到了如何去学习 ......
Life Long Learning(机器终身学习)
Life Long Learning(机器终身学习) Selective Synaptic plasticity(选择性突触可塑性) 只让类神经网路中,某一些神经元或某些神经元间的连接具有可塑性(只有部分的连接是有可塑性的,有些连接必须被固化,不能改变或移动他的数值) 为什么会灾难性遗忘: 假设模型 ......
概述增强式学习(Reinforcement Learning)
概述增强式学习(Reinforcement Learning) Supervised Learning(自监督学习):告诉机器输入和输出,用有标注的训练资料训练出的Network Reinforcement Learning(增强式学习):给机器一个输入,我们不知道最佳输出是什么(适用于标注困难或者 ......
小样本学习-RN
>论文阅读 《Learning to Compare Relation Network for Few-Shot Learning》 ### 相关链接 1. Relation Network 官方代码解析 2. github代码地址 3.基础知识视频 4.论文解析讲解视频 ......
pytorch使用(三)torch.zeros用法
#torch.zeros用法 torch.zeros() 是 PyTorch 中用来创建全 0 张量的函数。用法为 torch.zeros(size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=Fal ......
语言模型的预训练[6]:思维链(Chain-of-thought,CoT)定义原理详解、Zero-shot CoT、Few-shot CoT 以及在LLM上应用
语言模型的预训练[6]:思维链(Chain-of-thought,CoT)定义原理详解、Zero-shot CoT、Few-shot CoT 以及在LLM上应用 ......
machine learning-2023-07-19
questions【链接】 │ │──math │ │──线性回归 │ │──逻辑回归 │ └──梯度下降 │ │──python │ │──numpy(科学计算库) │ │──pandas(数据分析处理库) │ │──matplotlib(数据可视化库) │ └──scikit-learn(机器学 ......
Learn about some useful truck diagnostic scanner tools
Have you ever experienced the frustration of unexpected breakdowns with your truck? Or maybe you’re tired of paying expensive diagnostic fees at your ......
Learning hard C#学习笔记——读书笔记 07
## 1.值类型和引用类型 ### 1.1 什么是值类型和引用类型 * 值类型:包括简单类型,枚举类型,结构体类型等,值类型通常被分配在线程的堆栈上,变量保存的内容就是实例数据本身 * 引用类型:引用类型实例则被分配在托管堆上,变量保存的是实例数据的内存地址,引用类型主要包括类类型、接口类型、委托类 ......
大语言模型的预训练4:指示学习Instruction Learning详解以及和Prompt Learning,In-content Learning区别
# 大语言模型的预训练[4]:指示学习Instruction Learning:Entailment-oriented、PLM oriented、human-oriented详解以及和Prompt Learning,In-content Learning区别 # 1.指示学习的定义 Instruct ......
大语言模型的预训练[5]:语境学习、上下文学习In-Context Learning:精调LLM、Prompt设计和打分函数设计以及ICL底层机制等原理详解
大语言模型的预训练[5]:语境学习、上下文学习In-Context Learning:精调LLM、Prompt设计和打分函数设计以及ICL底层机制等原理详解 ......