contextualized recommendation sequential attention
A Neural Influence Diffusion Model for Social Recommendation
[TOC] > [Wu L., Sun P., Fu Y., Hong R., Wang X. and Wang M. A neural influence diffusion model for social recommendation. SIGIR, 2019.](https://dl.acm ......
SocialLGN Light graph convolution network for social recommendation
[TOC] > [Liao J., Zhou W., Luo F., Wen J., Gao M., Li X. and Zeng J. SocialLGN: Light graph convolution network for social recommendation. Information ......
搭建小实战和Sequential的使用
# 搭建小实战和Sequential的使用 ## 模型搭建 以CIFAR 10 model结构为例搭建网络 **CIFAR 10 model结构** 《Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 论文信息 论文标题:Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation论文作者:Junliang Yu ......
pytorch-两个PyTorch中的Sequential模型合并成一个
要将两个PyTorch中的Sequential模型合并成一个,你可以使用`nn.Sequential`的`add_module`方法或者直接使用`*`操作符来解包Sequential模型并将它们合并。以下是两种方法的示例: 方法一:使用`add_module`方法 ```python import ......
论文解读(LightGCL)《LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 论文信息 论文标题:LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation论文作者:Cai, Xuheng and Huang, ......
HS-GCN Hamming Spatial Graph Convolutional Networks for Recommendation
[TOC] > [Liu H., Wei Y., Yin J. and Nie L. HS-GCN: Hamming spatial graph convolutional networks for recommendation. IEEE TKDE.](https://arxiv.org/pdf/ ......
SIAMHAN:IPv6 Address Correlation Attacks on TLS E ncrypted Trafic via Siamese Heterogeneous Graph Attention Network解读
1. Address 论文来自于USENIX Security Symposium 2021 2. Paper summary 与ipv4地址采用nat掩盖不同,ipv6地址更加容易关联到用户活动上,从而泄露隐私。但现在已经有解决隐私担忧的方法被部署,导致现有的方法不再可靠。这篇文章发现尽管在有防护 ......
Attention机制竟有bug?Softmax是罪魁祸首,影响所有Transformer
前言 「大模型开发者,你们错了。」 本文转载自机器之心 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。 CV各大方向专栏与各个部署框架最全教程整理 【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线! ......
斯坦福博士一己之力让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
前言 FlashAttention新升级!斯坦福博士一人重写算法,第二代实现了最高9倍速提升。 本文转载自新智元 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。 CV各大方向专栏与各个部署框架最全教程整理 【CV技 ......
self-attention
Self attention考虑了整个sequence的资讯【transfermer中重要的架构是self-attention】 解决sequence2sequence的问题,考虑前后文 I saw a saw 第一个saw对应输出动词 第二个输出名词 如何计算相关性【attention score ......
Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning
图的作用: 图结构捕捉不同类型节点(即用户、项目和属性)之间丰富的关联信息,使我们能够发现协作用户对属性和项目的偏好。因此,我们可以利用图结构将推荐和对话组件有机地整合在一起,其中对话会话可以被视为在图中维护的节点序列,以动态地利用对话历史来预测下一轮的行动。 由四个主要组件组成:基于图的 MDP ......
粗读Multi-Task Recommendations with Reinforcement Learning
论文: Multi-Task Recommendations with Reinforcement Learning 地址: https://arxiv.org/abs/2302.03328 # 摘要 In recent years, Multi-task Learning (MTL) has yi ......
seq2seq+attention的个人理解
[toc] ## RNN 经典的RNN结构: 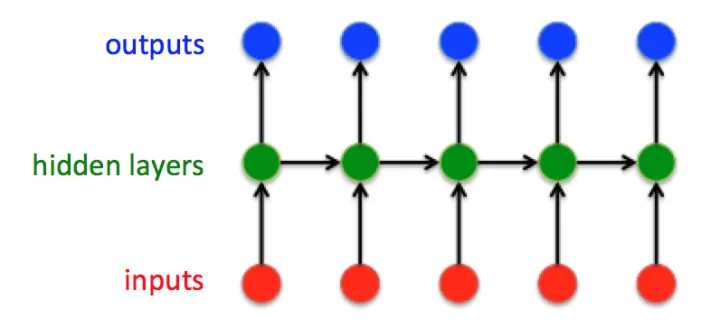 这是经典的RNN结构,输入向量是:  ## Introd ......
【论文阅读】CrossViT:Cross-Attention Multi-Scale Vision Transformer for Image Classification
> # 🚩前言 > > - 🐳博客主页:😚[睡晚不猿序程](https://www.cnblogs.com/whp135/)😚 > - ⌚首发时间:23.7.10 > - ⏰最近更新时间:23.7.10 > - 🙆本文由 **睡晚不猿序程** 原创 > - 🤡作者是蒻蒟本蒟,如果文章里有 ......
Multi-Modal Attention Network Learning for Semantic Source Code Retrieval 解读
# Multi-Modal Attention Network Learning for Semantic Source Code Retrieva Multi-Modal Attention Network Learning for Semantic Source Code Retrieval,题 ......
Memory Augmented Graph Neural Networks for Sequential Recommendation
[TOC] > [Ma C., Ma L., Zhang Y., Sun J., Liu X. and Coates M. Memory augmented graph neural networks for sequential recommendation. AAAI, 2021.](http: ......
【论文阅读】CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
来自CVPR 2021 论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2108.00154.pdf 代码地址:https://link.zhihu.com/?target=https%3A//github.com/cheers ......
4.1 Self-attention
# 1. 问题引入 我们在之前的课程里遇到的都是输入是一个向量,输出是类别或者标量.但如果输入是向量的集合且向量长度还会变化,又应该怎么处理呢?  - [备份网址] ......
什么是 Kernel Smoother ?它与 Self Attention 有什么关系?
[1] **带权滑动平均(Weighted Moving Average, WMA)** 是标量场上的滑动窗口内的加权平均,数学上等价于卷积。[^WMA] [2] **Kernel Smoother** 是一种特殊的 WMA 方法,特殊在于权重是由**核函数**决定的,相互之间越接近的点具有越高的权 ......
Attention is All you need
转载:https://zhuanlan.zhihu.com/p/46990010 Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型, ......
Self-attention with Functional Time Representation Learning
[TOC] > [Xu D., Ruan C., Kumar S., Korpeoglu E. and Achan K. Self-attention with functional time representation learning. NIPS, 2019.](http://arxiv.or ......
Graph Masked Autoencoder for Sequential Recommendation
[TOC] > [Ye Y., Xia L. and Huang C. Graph masked autoencoder for sequential recommendation. SIGIR, 2023.](http://arxiv.org/abs/2305.04619) ## 概 图 + MA ......
混合性对话:Towards Conversational Recommendation over Multi-Type Dialogs
## 混合型对话 传统的人机对话研究专注于单一类型的对话,并且往往预设用户一开始就清楚对话目标。但实际应用中,人机对话常常混合了多种类型,例如闲聊、任务导向对话、推荐对话、问答等,并且用户目标是未知的。在这样的混合型对话中,机器人需要主动自然地进行对话推荐。 “混合型对话”这个新颖的任务于2020年 ......
Time Interval Aware Self-Attention for Sequential Recommendation
[TOC] > [Li J., Wang Y., McAuley J. Time interval aware self-attention for sequential recommendation. WSDM, 2020.](https://dl.acm.org/doi/10.1145/3336 ......