ATTENTION
FlashAttention 如何加速Attention计算?
代数聚合 计算向量\(\mathbf x^l \in \mathbb R^{1 \times d}\)的softmax值 \[m(\mathbf x^l) = max(x_i^{l}) \\ f(\mathbf x^l) = [e^{x_1^l-m(\mathbf x^l)}, \cdots, e^ ......
Attention Is All You Need
Attention Is All You Need 关键词:Self-Attention、Transformer 📜 研究主题 设计仅基于注意力机制的网络Transformer Transformer仍然采用Encoder-Decoder结构,但脱离了Seq2Seq结构,不采用RNN或CNN单元 ......
attention案列
1、自注意力案例 import torch import torch.nn as nn class Selfattention(nn.Module): def __init__(self,input_dim): super(Selfattention, self).__init__() self.q ......
【NIPS2021】Twins: Revisiting the Design of Spatial Attention in Vision Transformers
来自美团技术团队♪(^∀^●)ノシ 论文地址:https://arxiv.org/abs/2104.13840 代码地址:https://git.io/Twins 一、写在前面 本文提出了两种视觉转换器架构,即Twins-PCPVT和Twins-SVT。 Twins-PCPVT 将金字塔 Trans ......
详细了解Transformer:Attention Is All You Need
--> 原文链接:Attention Is All You Need 1. 背景 在机器翻译任务下,RNN、LSTM、GRU等序列模型在NLP中取得了巨大的成功,但是这些模型的训练是通常沿着输入和输出序列的符号位置进行计算的顺序计算,无法并行。 文中提出了名为Transformer的模型架构,完全依 ......
Attention
注意力实现: import math import torch from torch import nn import matplotlib.pyplot as plt from d2l import torch as d2l def sequence_mask(X, valid_len, valu ......
【NIPS2021】Focal Self-attention for Local-Global Interactions in Vision Transformers
来自微软(*^____^*) 论文地址:[2107.00641] Focal Self-attention for Local-Global Interactions in Vision Transformers (arxiv.org) 代码地址:microsoft/Focal-Transforme ......
Attention Mixtures for Time-Aware Sequential Recommendation
目录概符号说明MOJITO代码 Tran V., Salha-Galvan G., Sguerra B. and Hennequin R. Attention mixtures for time-aware sequential recommendation. SIGIR, 2023. 概 本文希望 ......
【CVPR2022】Shunted Self-Attention via Multi-Scale Token Aggregation
来自CVPR2022 基于多尺度令牌聚合的分流自注意力 论文地址:[2111.15193] Shunted Self-Attention via Multi-Scale Token Aggregation (arxiv.org) 项目地址:https://github.com/OliverRensu ......
【学习笔记】Self-attention
最近想学点NLP的东西,开始看BERT,看了发现transformer知识丢光了,又来看self-attention;看完self-attention发现还得再去学学word embedding... 推荐学习顺序是:word embedding、self-attention / transform ......
【论文阅读】CAT: Cross Attention in Vision Transformer
论文地址:[2106.05786] CAT: Cross Attention in Vision Transformer (arxiv.org) 项目地址:https://github.com/linhezheng19/CAT 一、Abstract 由于Transformer在NLP中得到了广泛的应 ......
A Contextualized Temporal Attention Mechanism for Sequential Recommendation
[TOC] > [Wu J., Cai R. and Wang H. D\'ej\`a vu: A contextualized temporal attention mechanism for sequential recommendation. WWW, 2020.](http://arxiv. ......
Self-Attention
# Self-Attention - 参考:https://zhuanlan.zhihu.com/p/619154409 在Attention is all you need这篇论文中,可以看到这样一个公式: $Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt ......
Attention
``` #include #include #include #include #include #include #include #include #include #include #include #include #include #include #include #include #i ......
SIAMHAN:IPv6 Address Correlation Attacks on TLS E ncrypted Trafic via Siamese Heterogeneous Graph Attention Network解读
1. Address 论文来自于USENIX Security Symposium 2021 2. Paper summary 与ipv4地址采用nat掩盖不同,ipv6地址更加容易关联到用户活动上,从而泄露隐私。但现在已经有解决隐私担忧的方法被部署,导致现有的方法不再可靠。这篇文章发现尽管在有防护 ......
Attention机制竟有bug?Softmax是罪魁祸首,影响所有Transformer
前言 「大模型开发者,你们错了。」 本文转载自机器之心 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。 CV各大方向专栏与各个部署框架最全教程整理 【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线! ......
斯坦福博士一己之力让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
前言 FlashAttention新升级!斯坦福博士一人重写算法,第二代实现了最高9倍速提升。 本文转载自新智元 仅用于学术分享,若侵权请联系删除 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。 CV各大方向专栏与各个部署框架最全教程整理 【CV技 ......
self-attention
Self attention考虑了整个sequence的资讯【transfermer中重要的架构是self-attention】 解决sequence2sequence的问题,考虑前后文 I saw a saw 第一个saw对应输出动词 第二个输出名词 如何计算相关性【attention score ......
seq2seq+attention的个人理解
[toc] ## RNN 经典的RNN结构: 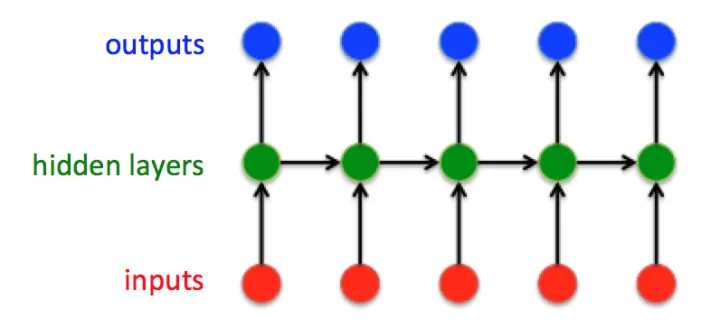 这是经典的RNN结构,输入向量是:  ## Introd ......
【论文阅读】CrossViT:Cross-Attention Multi-Scale Vision Transformer for Image Classification
> # 🚩前言 > > - 🐳博客主页:😚[睡晚不猿序程](https://www.cnblogs.com/whp135/)😚 > - ⌚首发时间:23.7.10 > - ⏰最近更新时间:23.7.10 > - 🙆本文由 **睡晚不猿序程** 原创 > - 🤡作者是蒻蒟本蒟,如果文章里有 ......
Multi-Modal Attention Network Learning for Semantic Source Code Retrieval 解读
# Multi-Modal Attention Network Learning for Semantic Source Code Retrieva Multi-Modal Attention Network Learning for Semantic Source Code Retrieval,题 ......
【论文阅读】CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
来自CVPR 2021 论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2108.00154.pdf 代码地址:https://link.zhihu.com/?target=https%3A//github.com/cheers ......
4.1 Self-attention
# 1. 问题引入 我们在之前的课程里遇到的都是输入是一个向量,输出是类别或者标量.但如果输入是向量的集合且向量长度还会变化,又应该怎么处理呢? ** 是标量场上的滑动窗口内的加权平均,数学上等价于卷积。[^WMA] [2] **Kernel Smoother** 是一种特殊的 WMA 方法,特殊在于权重是由**核函数**决定的,相互之间越接近的点具有越高的权 ......
Attention is All you need
转载:https://zhuanlan.zhihu.com/p/46990010 Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型, ......
Self-attention with Functional Time Representation Learning
[TOC] > [Xu D., Ruan C., Kumar S., Korpeoglu E. and Achan K. Self-attention with functional time representation learning. NIPS, 2019.](http://arxiv.or ......
Time Interval Aware Self-Attention for Sequential Recommendation
[TOC] > [Li J., Wang Y., McAuley J. Time interval aware self-attention for sequential recommendation. WSDM, 2020.](https://dl.acm.org/doi/10.1145/3336 ......