经典resnet论文
macbook苹果m1芯片训练机器学习、深度学习模型,resnet101在mnist手写数字识别上做加速,torch.device("mps")
apple的m1芯片比以往cpu芯片在机器学习加速上听说有15倍的提升,也就是可以使用apple mac训练深度学习pytorch模型!!!惊呆了 安装apple m1芯片版本的pytorch 然后使用chatGPT生成一个resnet101的训练代码,这里注意,如果网络特别轻的话是没有加速效果的, ......
前缀和经典问题整理
1、一般形式 -- 区域和检索 - 数组不可变 class NumArray: def __init__(self, nums: List[int]): self.pre = [0] for num in nums: self.pre.append(self.pre[-1] + num) ####或 ......
经典的Graph Embedding方法:DeepWalk 和 Node2vec
DeepWalk Deep Walk,它是 2014 年由美国石溪大学的研究者提出的。它的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入 Word2vec 进行训练,最终得到物品的 Embedding Node2vec 2016 年,斯坦福大学的研 ......
Open-Vocabulary Panoptic Segmentation with MaskCLIP论文阅读笔记
这篇文章的arxiv版看着太折磨了,可以直接看openreview上作者修改后的版本https://openreview.net/forum?id=zWudXc9343以及rebuttal帮助理解。 ## 摘要 本文提出了一个新任务:开放词汇全景分割,同时作者给出了基于ViT CLIP骨干的base ......
梯度降方差/全量数据的近似评估-系列论文小结
问题建模: Model 参数 , 输入 、两汉(22)、明代(25)、南北朝(24)、清代(27)、宋代(348)、唐代(373 ......
CLIP-S^4:Language-Guided Self-Supervised Semantic Segmentation论文阅读笔记
## 摘要 作者提出了CLIP-S4,借助自监督像素表示学习和V-L模型实现各种语义分割任务,不需要使用任何像素级别标注以及未知类的信息。作者首先通过对图像的不同增强视角进行像素-分割对比学习来学习像素嵌入。之后,为进一步改善像素嵌入并实现基于自然语言的语义分割,作者设计了由V-L模型指导的嵌入一致 ......
[论文阅读] SGCE-Font@ Skeleton Guided Channel Expansion for Chinese Font Generation
## Pre title: SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation accepted: Arxiv 2022 paper: https://arxiv.org/abs/2211.14475 co ......
【论文笔记】Deeplab系列
【深度学习】总目录 DeepLab系列是谷歌团队提出的一系列语义分割算法。DeepLab v1于2014年推出,随后2017到2018年又相继推出了DeepLab v2,DeepLab v3以及DeepLab v3+。 DeepLab v1《Semantic Image Segmentation w ......
10种超经典的软件滤波方法
1、限幅滤波法(又称程序判断滤波法) A、方法: 根据经验判断,确定两次采样允许的最大偏差值(设为A); 每次检测到新值时判断: 如果本次值与上次值之差<=A,则本次值有效; 如果本次值与上次值之差>A,则本次值无效,放弃本次值,用上次值代替本次值。 B、优点: 能有效克服因偶然因素引起的脉冲干扰。 ......
《AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks》特征交叉论文阅读
背景 这是一篇利用多头attention机制来做特征交叉的论文 模型结构 AutoInt的模型结构如上图所示,搞模型包含 Embedding Layer、Interacting Layer、Output Layer三个部分,其中Embedding Layer和Output Layer和普通模型没什么 ......
论文初稿
第1章 前 言 1.1 研究背景与意义 随着互联网的快速发展和普及,计算机网络安全问题越来越受到人们的关注。主机入侵事件已成为一个重要的网络安全威胁,对于企业和个人而言,入侵事件的发生不仅会导致数据泄露、系统瘫痪等损失,还会给用户带来重大经济和社会影响。因此,如何有效地保护主机免受入侵是一个非常紧迫 ......
OPT论文
相关工作 单模态预训练。最近,无监督预训练语言模型,如GPT [30]、BERT [7]、XLNet [47]、MASS [37]、UniLM [8]和BART [19]在自然语言处理任务上取得了巨大成功。GPT [30]是早期的成功之一,它利用单向词语上下文来学习通用语言表示。BERT [7]通过 ......
论文阅读笔记《Training Socially Engaging Robots Modeling Backchannel Behaviors with Batch Reinforcement Learning》
Training Socially Engaging Robots Modeling Backchannel Behaviors with Batch Reinforcement Learning 训练社交机器人:使用批量强化学习对反馈信号行为进行建模 发表于TAC 2022。 Hussain N, ......
buck-boost变换器的非线性PID控制,主电路也可以换成别的电路。 在经典P
buck-boost变换器的非线性PID控制,主电路也可以换成别的电路。在经典PID中引入了两个TD非线性跟踪微分器,构成了非线性PID控制器。当TD的输入为方波时,TD的输出,跟踪方波信号也没有超调,仿真波形如下所示。输入电压由20V逐渐变化到35V,设置输出参考电压为10V,在非线性PID的控制 ......
PaddlePaddle 飞桨复现 ResNet34
import paddle.nn as nn class ResidualBlock(nn.Layer): def __init__(self, in_channels, out_channels, stride = 1, downsample = None): super(ResidualBloc ......
[重读经典论文]YOLOX
参考博客:YOLOX网络结构详解 参考视频:YOLOX网络结构详解 亮点: 网络检测头部分,改成解耦的结构,将类别分数、边界框回归参数和objectness分别预测,提高网络收敛速度。 使用Anchor free对目标进行预测。 正负样本匹配策略SimOTA。 (完) ......
CF213C (棋盘dp的经典例题)
Relay Race - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 本题是棋盘dp的经典例题。 可以先转化一下题意:从(1,1)走两条路径到(n,n),再确保两人是同步行走的。 我们可以让一人的走路范围一直在左下方向,一人的走路范围一直在右上方向。(倘若两人的路径交叉,则都可以转 ......
多模态里程碑论文(ALBEF、BLIP、BLIP-2)
1. ALBEF: ALign the image and text BEfore Fusing 1.1 论文与代码链接: https://arxiv.org/abs/2107.07651 GitHub - salesforce/ALBEF: Code for ALBEF: a new ......
大数据ETL开发之图解Kettle工具入门到精通(经典转载)
大数据ETL开发之图解Kettle工具(入门到精通) 置顶 袁袁袁袁满 文章目录 第0章 ETL简介 第1章 Kettle简介 1.1 Kettle是什么 1.2 Kettle的两种设计 1.3 Kettle的核心组件 1.4 Kettle的特点 第2章 Kettle安装部署 2.1 Kettle ......
论文阅读 | Déjà Vu? Client-Side Fingerprinting and Version Detection of Web Application Software 似曾相识? Web应用软件的客户端指纹识别与版本检测
https://ieeexplore.ieee.org/abstract/document/9524885 Introduction 在这项工作中,我们提出了一种新颖的方法,该方法能够使用被动扫描技术为不同的 Web 应用程序自动构建指纹。除了资产文件的哈希值,我们还建议在指纹识别过程中使用 XPa ......
论文解读《Mixup for Node and Graph Classification》
论文信息 论文标题:Mixup for Node and Graph Classification论文作者:Yiwei Wang、Wei Wang论文来源:WWW 2021论文地址:download 论文代码:download视屏讲解:click 1 介绍 ......
数学建模论文排版(公式自动排序)
本文为学习清风数学建模排版的公式编号部分的笔记 配套资料可以在微信公众号《数学建模学习交流》后台发送“论文排版”免费获取。 步骤 先插入一个“无边框“,“格式居中”表格如图(表格工具——布局——查看网格线),并随便在第一列输入公式,第二列输入(),并将光标放到括号里 然后插入——文档部件——域——A ......
【课程作业】计算机图形学—经典算法实现
【课程作业】计算机图形学—经典算法实现 【Github】 1.【Radial Basis Functions】 2023-3-18-update Matlab 使用 RBF 算法实现图像变形。 参考文献:Nur Arad and Daniel Reisfeld. Image Warping Usin ......
论文解读(ID-MixGCL)《ID-MixGCL: Identity Mixup for Graph Contrastive Learning》
论文信息 论文标题:ID-MixGCL: Identity Mixup for Graph Contrastive Learning论文作者:Gehang Zhang.....论文来源:2023 aRxiv论文地址:download 论文代码:download视屏讲解:click 介绍 ......
SAM:SegMent Anything万物分割论文解读
SAM: SegMent Anything 作者:elfin 资料来源:SAM论文 论文:https://ai.facebook.com/research/publications/segment-anything/ 代码:https://github.com/facebookresearch/se ......
Twitter延迟转化论文《Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction》阅读
背景 由于用户的兴趣是实时变化的,现代推荐、广告系统采用了流式更新的方式来捕捉用户实时兴趣的变化。实时训练的方式面临的一个难题就是正样本的回传是有延迟的,一个实时发送的负样本其实是无法确认是否是真的负样本的。也就是说实时观测到的数据流是一个有偏数据流,并不是真实的数据。如果模型在这个有偏分布上学习, ......
[重读经典论文]YOLOv4
推荐博客:YOLOv4网络详解 配套视频:YOLOv4网络详解 补充知识:3.1 YOLO系列理论合集(YOLOv1~v3) 中的yolov3spp理论讲解(包括CIoU以及Focal Loss) (完) ......
【论文】Range-Focused Fusion of Camera-IMU-UWB for Accurate and Drift-Reduced Localization
## Abstract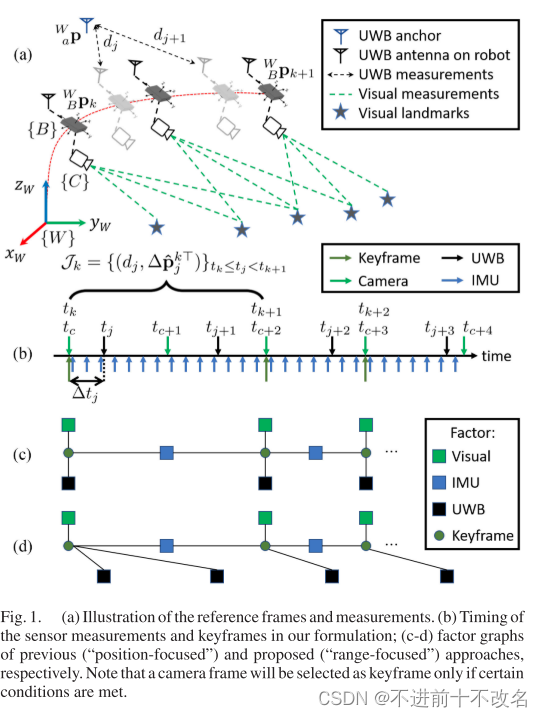## I. INTRODUCTION为什么需要添加UWB?因为传统的VIO会由于传感器的噪声和计算误差产生累计偏移。所以需要G ......