identification residual learning buoyancy
Machine Learning 【note_01】
Declaration (2023/06/02): This note is the first note of a series of machine learning notes. At present, the main learning resource is *the 2022 Andre ......
论文阅读 | Learn from Others and Be Yourself in Heterogeneous Federated Learning
**在异构联邦学习中博采众长做自己** 代码:https://paperswithcode.com/paper/learn-from-others-and-be-yourself-in **摘要** 联邦学习中有异质性问题和灾难性遗忘。首先,由于非I.I.D(相同独立分布)数据和异构体系结构,模型在 ......
April 2023-Memory-efficient Reinforcement Learning with Value-based Knowledge Consolidation
本文基于深度q网络算法提出了记忆高效的强化学习算法来缓解这一问题。通过将目标q网络中的知识整合Knowledge Consolidation到当前q网络中,所提算法减少了遗忘并保持了较高的样本效率。 ......
零样本学习(Zero-shot Learning)
零样本学习是一种机器学习的问题设置,其中模型可以对从未在训练过程中见过的类别的样本进行分类,使用一些形式的辅助信息来关联已见和未见的类别。例如,一个模型可以根据动物的文本描述来识别动物,即使它从未见过那些动物的图像。 实现零样本学习有不同的方法,取决于辅助信息的类型和学习方法。以下是一些例子: 一种 ......
WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
# WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! ```shell WorkSpace>git clone git@github.com:******/****.git Cloning into '******'... @@@@@@@@@@@@@@ ......
事件抽取论文综述-A Survey on Deep Learning Event Extraction: Approaches and Applications
A Survey on Deep Learning Event Extraction: Approaches and Applications 1)发表信息: https://arxiv.org/abs/2107.02126 Qian Li, Jianxin Li, Member, IEEE, Ji ......
[论文速览] MAGE@MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
## Pre title: MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis accepted: CVPR2023 paper: https://arxiv.org/abs/221 ......
[论文阅读] Few-shot Font Generation by Learning Style Difference and Similarity
## Pre title: Few-shot Font Generation by Learning Style Difference and Similarity accepted: Arxiv 2023 paper: https://arxiv.org/abs/2301.10008 code: ......
[论文速览] RectifiedFlow@Flow Straight and Fast{colon}Learning to Generate and Transfer Data with Rectified Flow
## Pre title: Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow accepted: ICLR 2023 paper: https://arxiv.org/abs/2209 ......
2023CVPR_Learning a Simple Low-light Image Enhancer from Paired Low-light Instances(PairLLE)无监督
一. motivation 以前的大多数LIE算法使用单个输入图像和几个手工制作的先验来调整照明。然而,由于单幅图像信息有限,手工先验的适应性较差,这些解决方案往往无法揭示图像细节。 二. contribution 1. 提出一个成对低光图像输入(相同内容,不同的曝光度) 2. 在输入之前进行了一个 ......
The Difficulty of Passive Learning in Deep Reinforcement Learning
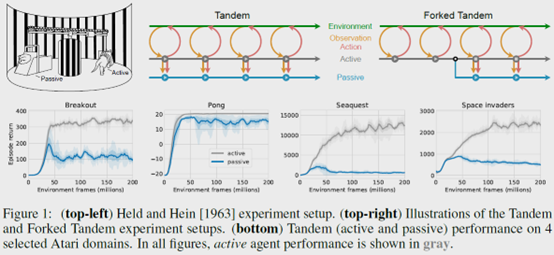 **发表时间:**2021(NeurIPS 2021) **文章要点:**这篇文章提出一个tandem learni ......
learn c++ 参数引用
#include <iostream> struct Role { int hp; int mp; int damage; }; bool Act(Role& Acter,Role& beAct) { beAct.hp -= Acter.damage; return beAct.hp < 0; } ......
Learning with Local and Global Consistency
[TOC] > [Zhou D., Bousquet O., Lal T. N., Weston J. and Scholk\ddot{o}pf B. Learning with local and global consistency. NIPS, 2003.](https://proceedin ......
2023CVPR_Learning a Simple Low-light Image Enhancer from Paired Low-light Instances(PairLIE)
1、nn.ReflectionPad2d 对输入图像以最外围像素为对称轴,做四周的轴对称镜像填充。 大佬链接:(14条消息) torch.nn.ReflectionPad2d()的用法简介_nn.reflectionpad2d(1)_啊菜来了的博客-CSDN博客 # 对四周都填充3行 nn.Refl ......
Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers概述
0.前言 相关资料: arxiv github 论文解读 论文基本信息: 领域:弱监督语义分割 发表时间: CVPR 2022(2022.3.5) 1.针对的问题 目前主流的弱监督语义分割方法通常首先训练分类模型,基于类别激活图(CAM)或其变种生成初始伪标签;然后对伪标签进行细化作为监督信息训练一 ......
learn c++ 智能指针
#include <iostream> int main() { int* p; { std::unique_ptr<int[]> a{std::make_unique<int[]>(50)}; a[2] = 240; p = a.get(); std::cout << p[2]; } std::c ......
Sep 2022-Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
提出了Reducible Holdout Loss Selection (RHOLOSS),一种简单但有原则的技术,近似地选择那些最能减少模型泛化损失的点进行训练 ......
C-pointer Learning
# 基础 ## 指针类型 ### 静态/全局内存 指在内存空间中的全局/静态数据区的指针变量 ### 自动内存 即局部作用域的指针,只有在函数被调用时才创建。 ### 动态内存 在堆区动态创建的指针变量,在不使用时需要即是释放该部分内存空间。 ## 特殊指针 ### NULL指针 在指针变量中,初始 ......
learn c++ 变量作用域
#include <iostream> int a{ 100 }; int main() { int a{160}; { std::cout << a << std::endl; char a = 'a'; std::cout << a << std::endl; std::cout << ::a ......
Off-Policy Deep Reinforcement Learning without Exploration
**发表时间:**2019(ICML 2019) **文章要点:**这篇文章想说在offline RL的setting下,由于外推误差(extrapolation errors)的原因,标准的off-policy算法比如DQN,DDPG之类的,如果数据的分布和当前policy的分布差距很大的话,那就 ......
《AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks》特征交叉论文阅读
背景 这是一篇利用多头attention机制来做特征交叉的论文 模型结构 AutoInt的模型结构如上图所示,搞模型包含 Embedding Layer、Interacting Layer、Output Layer三个部分,其中Embedding Layer和Output Layer和普通模型没什么 ......
【图像数据增强】Image Data Augmentation for Deep Learning: A Survey
| 原始题目 | Image Data Augmentation for Deep Learning: A Survey | | | | | 中文名称 | 深度学习的图像数据增强:综述 | | 发表时间 | 2022年4月19日 | | 平台 | arXiv | | 来源 | 南京大学 | | 文章 ......
Jan 2023-Prioritizing Samples in Reinforcement Learning with Reducible Loss
#1 Introduction 本文建议根据样本的可学习性进行抽样,而不是从经验回放中随机抽样。如果有可能减少代理对该样本的损失,则认为该样本是可学习的。我们将可以减少样本损失的数量称为其可减少损失(ReLo)。这与Schaul等人[2016]的vanilla优先级不同,后者只是对具有高损失的样本给 ......
Oracle 集合-Learning-1
集合-Test1 bulk collect into 批量插入,可用limit 限制插入行数 type ... is table of DataType Index by binary_Integer 其中 index by binary_integer 在定义schema级 type 时没有使用, ......
Short-Term Plasticity Neurons Learning to Learn and Forget
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Proceedings of the 39th International Conference on Machine Learning ......
论文阅读笔记《Training Socially Engaging Robots Modeling Backchannel Behaviors with Batch Reinforcement Learning》
Training Socially Engaging Robots Modeling Backchannel Behaviors with Batch Reinforcement Learning 训练社交机器人:使用批量强化学习对反馈信号行为进行建模 发表于TAC 2022。 Hussain N, ......
Robust Deep Reinforcement Learning through Adversarial Loss
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Abstract 最近的研究表明,深度强化学习智能体很容易受到智能体输入上的小对抗性扰动的影响 ......
【五期邹昱夫】CCF-A(NeurIPS'19)Inverting gradients-how easy is it to break privacy in federated learning?
"Geiping J, Bauermeister H, Dröge H, et al. Inverting gradients-how easy is it to break privacy in federated learning?[J]. Advances in Neural Informat ......
prompt learning如何计算损失的
在prompt learning中,对于一个类别的多个候选词,损失函数通常会计算所有词的logit和,并与真实标签作比较。以情感分类为例: 假设正面类别有两个候选词:“positive”和“optimistic”。负面类别有两个候选词:“negative”和“pessimistic”。 然后模型会计 ......