reinforcement perturbations observations adversarial
什么是 Rxjs Observable subscribe 方法的副作用
RxJS Observable 是一个强大的用于处理异步或多值的工具。它可以被看作一个事件流,开发人员可以监听这个事件流,并在事件发生时执行一些操作。这就是为什么说 Observable 的 subscribe 方法有副作用(side effects):因为当开发人员订阅(subscribe)一个 ......
关于 Observable 对象调用 subscribe 方法时不传递任何参数值的用法讨论
在 RxJS 中,`subscribe` 方法是用于订阅 Observable 对象并接收数据的关键方法。通过 `subscribe` 方法,我们可以注册观察者(Observer)来处理 Observable 发出的数据、错误和完成信号。该方法接收三个可选的回调函数作为参数:`next`、`erro ......
Observe.ai推出全球首个客服领域GPT
目前,金融、医疗、旅游、证券、法律等行业,相继推出了垂直业务场景的类ChatGPT大语言模型,客户服务领域还处于空白,即便是有也是通过微调方式打造而成。 知名客服平台Observe.AI凭借自己多年客服语料数据和技术沉淀,推出了只专注客服领域完全自研的300亿参数的大语言模型。(申请测试地址:htt ......
Regret Minimization Experience Replay in Off-Policy Reinforcement Learning
**发表时间:**2021 (NeurIPS 2021) **文章要点:**理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with highe ......
Effective Diversity in Population-Based Reinforcement Learning
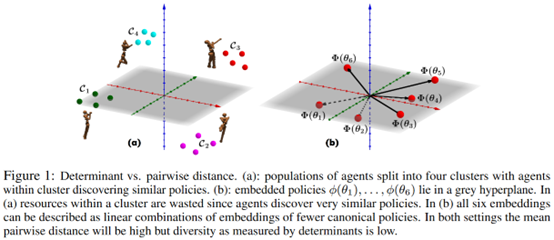 **发表时间:**2020 (NeurIPS 2020) **文章要点:**这篇文章提出了Diversity v ......
Vue 数组中出现__ob__: Observer无法取值[已解决]
Vue 数组中出现__ob__: Observer无法取值[已解决] 代码如下 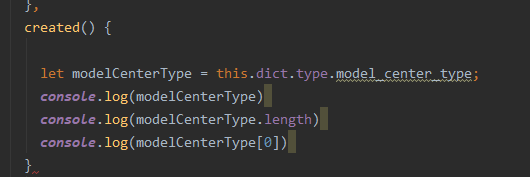 ,以及旨在提高代理性能的生成式 AI 套件。 该公司声称,与 GPT 等模型相比,其专有的 LLM 是在大量真实世界的联络中心交互数据集上进行了训练,能够处理为联 ......
简单实现线程安全的Observer模式
title: 简单实现线程安全的Observer模式 date: 2022-10-20 23:08:43 tags: # 简单实现线程安全的Observer模式 最近开始看陈硕老师的《Linux多线程服务器编程》,刚好发现b站Up主啊起个名字不容易的[总结视频](https://www.bilibi ......
Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning---reading
# Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning reading - 攻击目标 - 安全破坏 - 完整性破坏: 逃避检测,而不影响正常的系统运行 - 可用性破坏: 使得合法用户不能正常使用系统 - 隐私 ......
Spectrum Random Masking for Generalization in Image-based Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! ......
【五期邹昱夫】CCF-A(NeurIPS'21)Adversarial Neuron Pruning Purifies Backdoored Deep Models
> "Wu, Dongxian, and Yisen Wang. "Adversarial neuron pruning purifies backdoored deep models." Advances in Neural Information Processing Systems 34 (2 ......
Faster sorting algorithms discovered using deep reinforcement learning
## 摘要: - `AlphaDev`模型优化排序算法,将排序算法提速70%。通过强化学习,AlphaDev发现了更加有效的算法,直接超越了科学家和工程师们几十年来的精心打磨。现在,新的算法已经成为两个标准C++编码库的一部分,每天都会被全球的程序员使用数万亿次。 ## 介绍 - 优化目标为排序算法 ......
Reinforcement learning
如图1所示,强化学习中,state是环境的状态,就是observation。 图1 强化学习 一、Policy based approach learning an actor The policy based approach is to learn an actor (agent or poli ......
SNN-RAT: Robustness-enhanced Spiking Neural Network through Regularized Adversarial Training
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 同大组工作 Abstract ......
Phenomenon•Observation•Uncertainty/Certainty•Statistical law•Random phenomenon•Theory of Probability
Mathematics: the logic of certainty. Statistics: the logic of uncertainty. Certainty/Uncertainty: Phenomenon • Result Phenomenon -> Observation -> (Ce ......
Intersection Observer
# Intersection Observer 在日常开发中,经常会遇到对数据、图片进行懒加载的处理,要判断用户是否已经看到了数据或者图片。之前用的方法是通过听到scroll事件或者使用setInterval来判断,这种方法的缺点是,由于scroll事件触发频率高,计算量很大,如果不做防抖节流的话, ......
20) Observer pattern
类别: Behavioral Pattern 问题: 方案1: 示例1: import java.util.ArrayList; import java.util.List; public class ObserverPatternDemo { public static void main(Str ......
Reward Modelling(RM)and Reinforcement Learning from Human Feedback(RLHF)for Large language models(LLM)技术初探
Reward Modelling(RM)and Reinforcement Learning from Human Feedback(RLHF)for Large language models(LLM)技术初探 ......
Reinforcement Learning之Q-Learning - Python实现
- **算法特征** ①. 以真实reward训练Q-function; ②. 从最大Q方向更新policy $\pi$ - **算法推导** **Part Ⅰ: RL之原理** 整体交互流程如下, 定义策略函数(policy)$\pi$, 输入为状态(state)$s$, 输出为动作(action ......
Intersection Observer API 交叉观察器 API vue3 antd table 滚动加载 使用过程
需求:表格滚动加载 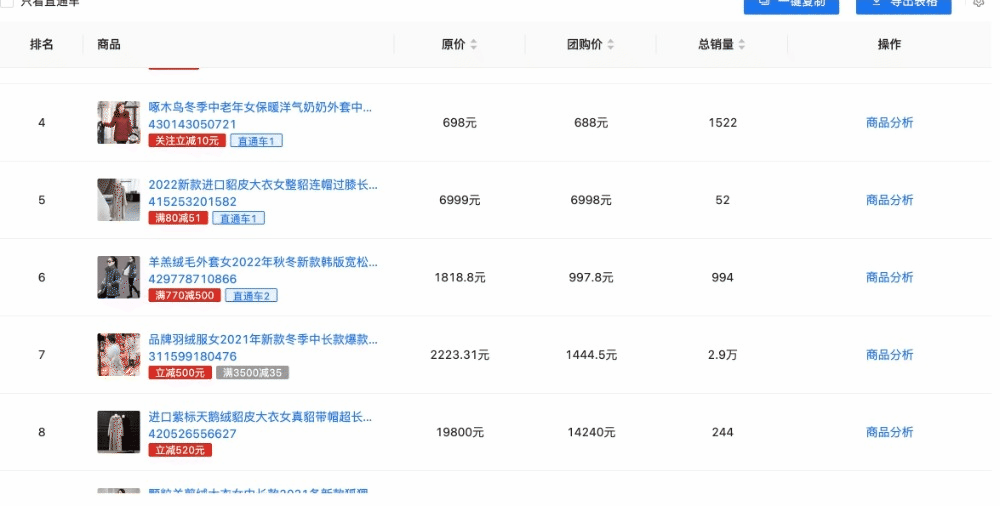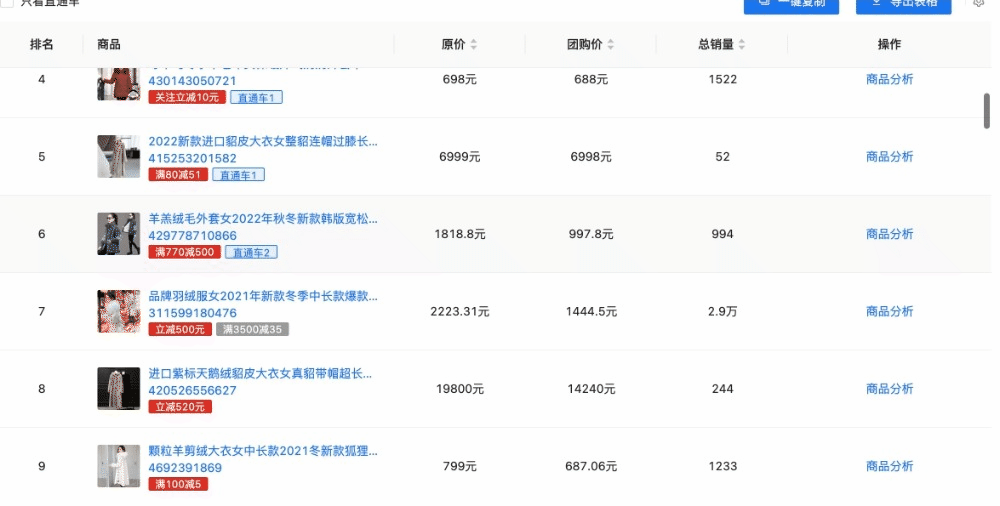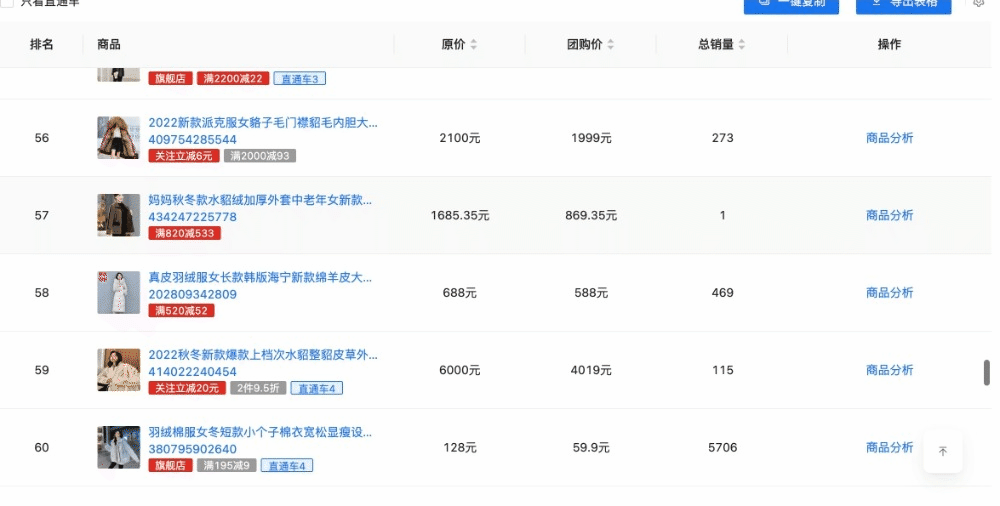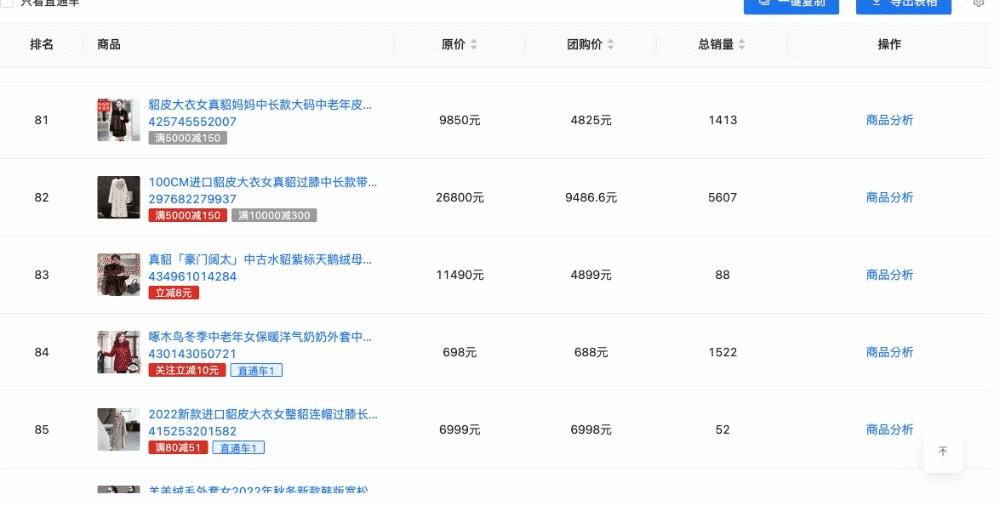 做法: 步骤一:给表格最后一行添加特定标识,类名或者id等 :智能体是强化学习算法的主体,它能够根据经验做出主观判断并执行动作,是整个智能系统的核心。 环境(environment):智能体以外的一切统称为环 ......
April 2023-Memory-efficient Reinforcement Learning with Value-based Knowledge Consolidation
本文基于深度q网络算法提出了记忆高效的强化学习算法来缓解这一问题。通过将目标q网络中的知识整合Knowledge Consolidation到当前q网络中,所提算法减少了遗忘并保持了较高的样本效率。 ......
The Difficulty of Passive Learning in Deep Reinforcement Learning
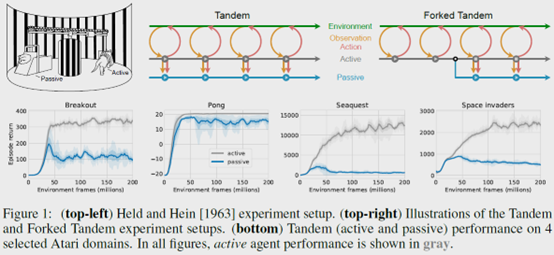 **发表时间:**2021(NeurIPS 2021) **文章要点:**这篇文章提出一个tandem learni ......
观察者模式(Observer Pattern)
## 一、模式动机 >观察者模式用于描述对象之间的依赖关系,它引入了观察者和观察目标两类不同的角色,由于提供了抽象层,它使得增加新的观察者和观察目标都很方便。观察者模式广泛应用于各种编程语言的事件处理模型中,Java语言也提供了对观察者模式的全面支持。 - 一个对象的状态或行为的变化将导致其他对象的 ......
Off-Policy Deep Reinforcement Learning without Exploration
**发表时间:**2019(ICML 2019) **文章要点:**这篇文章想说在offline RL的setting下,由于外推误差(extrapolation errors)的原因,标准的off-policy算法比如DQN,DDPG之类的,如果数据的分布和当前policy的分布差距很大的话,那就 ......
Jan 2023-Prioritizing Samples in Reinforcement Learning with Reducible Loss
#1 Introduction 本文建议根据样本的可学习性进行抽样,而不是从经验回放中随机抽样。如果有可能减少代理对该样本的损失,则认为该样本是可学习的。我们将可以减少样本损失的数量称为其可减少损失(ReLo)。这与Schaul等人[2016]的vanilla优先级不同,后者只是对具有高损失的样本给 ......
论文阅读笔记《Training Socially Engaging Robots Modeling Backchannel Behaviors with Batch Reinforcement Learning》
Training Socially Engaging Robots Modeling Backchannel Behaviors with Batch Reinforcement Learning 训练社交机器人:使用批量强化学习对反馈信号行为进行建模 发表于TAC 2022。 Hussain N, ......
Robust Deep Reinforcement Learning through Adversarial Loss
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Abstract 最近的研究表明,深度强化学习智能体很容易受到智能体输入上的小对抗性扰动的影响 ......
Heuristic-Guided Reinforcement Learning
**发表时间:**2021 (NeurIPS 2021) **文章要点:**这篇文章提出了一个Heuristic-Guided Reinforcement Learning (HuRL)的框架,用domain knowledge或者offline data构建heuristic,将问题变成一个sho ......
Intersection Observer API 实现图片懒加载
1,为需要延迟加载的图片设置data-src属性。 <img src="" data-src="image.jpg" alt="图片"> 2,使用Intersection Observer API监听可视区域内的元素变化,并将其data-src属性值赋给src属性,显示图片。 const lazyL ......