meta-reinforcement reinforcement probabilistic
Probabilistic Method
Probabilistic Method 符号约定 均值:\(\mu=\mathbb{E}[X]\) 方差:\(\sigma=\text{Var}[X]\). 斜方差:\(\text{Cov}(X,Y)\). 引入 对于 0/1 随机变量 \(X_i\)(也对应着一个事件是否发生),令 \(X=\s ......
概率霍夫变换(Progressive Probabilistic Hough Transform)原理详解
概率霍夫变换(Progressive Probabilistic Hough Transform)的原理很简单,如下所述: 1.随机获取边缘图像上的前景点,映射到极坐标系画曲线; 2.当极坐标系里面有交点达到最小投票数,将该点对应x-y坐标系的直线L找出来; 3.搜索边缘图像上前景点,在直线L上的点 ......
强化学习研究方向(研究领域)现有的不足(短板、无法落地性) —— Why You (Probably) Shouldn’t Use Reinforcement Learning
外文原文: Why You (Probably) Shouldn’t Use Reinforcement Learning 地址: https://towardsdatascience.com/why-you-shouldnt-use-reinforcement-learning-163bae193 ......
A fast and simple algorithm for training neural probabilistic language models
目录概Noise contrastive estimation Mnih A. and Teh Y. W. A fast and simple algorithm for training neural probabilistic language models. ICML, 2012. 概 NCE ......
2023 - LauraHughes - A Novel Method to Determine Probabilistic Tsunami Hazard Using a Physics‐Based Synthetic
概要 这篇文章主要讨论了使用基于物理的合成地震目录进行海啸危险评估的首次尝试,并展示了在新西兰海岸附近,近场地震海啸可以产生高达28米的最大海浪高度。文章介绍了使用Cornell Multi-grid Coupled Tsunami模型(COMCOT)进行海啸生成和传播模拟的方法,并对模拟结果进行了 ......
《Visual Analytics for RNN-Based Deep Reinforcement Learning》
摘要 准备开题报告,整理一篇 2022 年TOP 论文。 论文介绍 该论文是一篇 2022 年,有关可视化分析基于RNN 的深度强化学习训练过程的文章。一作是 Junpeng Wang ,作者主要研究领域就是:visualization, visual analytics, explainable ......
Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning
概述 Learning form the Void (LfVoid) 根据给定的language instruction对observation进行appearance-based and structure-based修改得到goal images,为RL提供奖励信号。提升了example-bas ......
Probabilistic principal component analysis-based anomaly detection for structures with missing data(概率主成分分析PPCA)
SHM can provide a large amount of data that can reveal the variation in the structure condition什么是压缩传感,数据重构,研究背景与意义,怎么用 基于模型的方法不可避免的缺点是模型的不确定性,因为很难创建能 ......
【略读论文|时序知识图谱补全】DREAM: Adaptive Reinforcement Learning based on Attention Mechanism for Temporal Knowledge Graph Reasoning
会议:SIGIR,时间:2023,学校:苏州大学计算机科学与技术学院,澳大利亚昆士兰布里斯班大学信息技术与电气工程学院,Griffith大学金海岸信息通信技术学院 摘要: 原因:现在的时序知识图谱推理方法无法生成显式推理路径,缺乏可解释性。 方法迁移:由于强化学习 (RL) 用于传统知识图谱上的多跳 ......
Reinforcement Learning Chapter 1
本文参考《Reinforcement Learning:An Introduction(2nd Edition)》Sutton. 强化学习是什么 传统机器学习方法可分为有监督与无监督两类; 有监督学习 > 任务驱动 无监督学习 > 数据驱动 强化学习则可看作机器学习的“第三范式” > 模拟驱动,具体 ......
TRL(Transformer Reinforcement Learning) PPO Trainer 学习笔记
(1) PPO Trainer TRL支持PPO Trainer通过RL训练语言模型上的任何奖励信号。奖励信号可以来自手工制作的规则、指标或使用奖励模型的偏好数据。要获得完整的示例,请查看examples/notebooks/gpt2-sentiment.ipynb。Trainer很大程度上受到了原 ......
Introduction of Deep Reinforcement Learning
Reading Notes about the book Deep Reinforcement Learning written by Aske Plaat Recently, I have been reading the book Deep Reinforcement Learning writ ......
Tabular Value-Based Reinforcement Learning
Reading Notes about the book Deep Reinforcement Learning written by Aske Plaat Recently, I have been reading the book Deep Reinforcement Learning writ ......
【论文阅读】DeepAR Probabilistic forecasting with autoregressive recurrent networks
原始题目:DeepAR: Probabilistic forecasting with autoregressive recurrent networks 中文翻译:DeepAR:自回归递归网络的概率预测 发表时间:2020年07月 平台:International Journal of Forec ......
Reinforcement Learning 学习笔记 1
什么是强化学习(reinforcement learning)? 假设一个场景,一个智能体(agent) 和环境(env)交互,智能体基于当前环境\(S_t\)每产生一个动作\(A_t\),环境便给它一个反馈,也被称为奖励(reward)\(R_{t+1}\), 随后,智能体的状态变为\(S_{t+ ......
Pink Noise Is All You Need: Colored Noise Exploration in Deep Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Published as a conference paper at ICLR 2023 ABSTRACT ......
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Proceedings of the 36th International Conference on Machine Learning, PMLR 97:5331-5340, 2019 ......
Meta-Reinforcement Learning of Structured Exploration Strategies
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! NeurIPS 2018 ......
语音合成技术6:DuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model
DuTa-VC: 一种具有扩散概率模型的时长感知典型到非典型语音转换方法 摘要 我们提出了一种新颖的典型到非典型语音转换方法(DuTa-VC),它具有以下特点:(i)可以使用非平行数据进行训练,(ii)首次引入了扩散概率模型,(iii)保留了目标说话者的身份,(iv)了解目标说话者的音素持续时间。D ......
强化学习——策略梯度之Reinforce
1、策略梯度介绍 相比与DQN,策略梯度方法的区别主要在于,我们对于在某个状态下所采取的动作,并不由一个神经网络来决定,而是由一个策略函数来给出,而这个策略函数的目的,就是使得最终的奖励的累加和最大,这也是训练目标,所以训练会围绕策略函数的梯度来进行。 2、策略函数 以Reinforce算法为例, ......
《Decision Transformer: Reinforcement Learning via Sequence Modeling》论文学习
一、Introduction 先前的研究工作表明,Transformer可以对处于高维分布的语义概念进行大规模建模抽象,比较典型地体现如: 基于自然语言的零样本泛化(zero-shot generalization) 分布外图像生成(out-of-distribution image generat ......
Improved deep reinforcement learning for robotics through distribution-based experience retention
 **发表时间:**2016(IROS 2016) **文章要点:**这篇文章提出了experience repl ......
The importance of experience replay database composition in deep reinforcement learning
 **发表时间:**2015(Deep Reinforcement Learning Workshop, NIPS ......
概述增强式学习(Reinforcement Learning)
概述增强式学习(Reinforcement Learning) Supervised Learning(自监督学习):告诉机器输入和输出,用有标注的训练资料训练出的Network Reinforcement Learning(增强式学习):给机器一个输入,我们不知道最佳输出是什么(适用于标注困难或者 ......
Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning
图的作用: 图结构捕捉不同类型节点(即用户、项目和属性)之间丰富的关联信息,使我们能够发现协作用户对属性和项目的偏好。因此,我们可以利用图结构将推荐和对话组件有机地整合在一起,其中对话会话可以被视为在图中维护的节点序列,以动态地利用对话历史来预测下一轮的行动。 由四个主要组件组成:基于图的 MDP ......
粗读Multi-Task Recommendations with Reinforcement Learning
论文: Multi-Task Recommendations with Reinforcement Learning 地址: https://arxiv.org/abs/2302.03328 # 摘要 In recent years, Multi-task Learning (MTL) has yi ......
Regret Minimization Experience Replay in Off-Policy Reinforcement Learning
**发表时间:**2021 (NeurIPS 2021) **文章要点:**理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with highe ......
Effective Diversity in Population-Based Reinforcement Learning
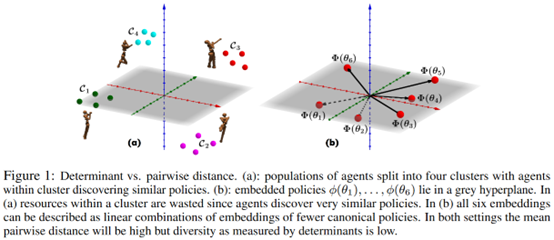 **发表时间:**2020 (NeurIPS 2020) **文章要点:**这篇文章提出了Diversity v ......
Spectrum Random Masking for Generalization in Image-based Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! ......
Faster sorting algorithms discovered using deep reinforcement learning
## 摘要: - `AlphaDev`模型优化排序算法,将排序算法提速70%。通过强化学习,AlphaDev发现了更加有效的算法,直接超越了科学家和工程师们几十年来的精心打磨。现在,新的算法已经成为两个标准C++编码库的一部分,每天都会被全球的程序员使用数万亿次。 ## 介绍 - 优化目标为排序算法 ......