engineering thinking teaching learning
基于时态差分法的强化学习:Sarsa和Q-learning
时态差分法(Temporal Difference, TD)是一类在强化学习中广泛应用的算法,用于学习价值函数或策略。Sarsa和Q-learning都是基于时态差分法的重要算法,用于解决马尔可夫决策过程(Markov Decision Process, MDP)中的强化学习问题。 下面是最简单的T ......
论文解读(SimGCL)《Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 论文信息 论文标题:Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation论文作者:Junliang Yu ......
提升ChatGPT性能的实用指南:Prompt Engineering的艺术
一起探索 Prompt Engineering 的奥秘,并学习如何用它来让 ChatGPT 发挥出最大的潜力。 什么是提示工程? 提示工程是一门新兴学科,就像是为大语言模型(LLM)设计的"语言游戏"。通过这个"游戏",我们可以更有效地引导 LLM 来处理问题。只有熟悉了这个游戏的规则,我们才能更清 ......
Unreal Engine 5.2 .uasset文件格式分析
以下内容只包含UE5的5.2版本,不包含兼容性内容,不同版本可能会有所不同。 提示: N :通常代表数组个数 ? :代表不确定,比如字符串的长度。 * : 乘积 Type Name : Size : 此说明并非定义位域,是在说明此处的数据类型、名称以及空间占用,空间单位为字节。 基础类型序列化 这里 ......
Paper Reading: Multitree Genetic Programming With New Operators for Transfer Learning in Symbolic Regression With Incomplete Data
针对数据集存在缺失值的问题,本文提出了一种基于多树 GP(MTGP) 的迁移学习方法 pMTGPDA,用于将知识从完整的源域转移到不完整的目标域中。首先在源域的数据集上训练多个 SR 模型,通过模型中的训练细节计算源域的特征和实例的权重作为先验知识。然后将提取的权重知识用于基于 MTGP 的转换,构... ......
论文阅读 | Layer-wised Model Aggregation for Personalized Federated Learning
面向个性化联合学习的分层模型聚合 ==在本文中,我们提出了一种新的pFedLA训练框架,该框架能够区分不同客户端的每一层的重要性,从而能够优化具有异构数据的客户端的个性化模型聚合。==具体来说,我们在服务器端为每个客户端使用一个专用的超网络,它被训练来识别层粒度上的相互贡献因素。同时,引入参数化机制 ......
论文解读(LightGCL)《LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 论文信息 论文标题:LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation论文作者:Cai, Xuheng and Huang, ......
Learning by teaching --- 费曼学习法
世界上存在成千上万种学习法,如果上天只让我掌握一种,那一定就是“费曼学习法”。 ## 介绍 费曼学习法是由诺贝尔物理学奖获得者理查德·费曼提出的一种学习方法,其核心思想是将所学内容用自己的话表达出来,以此检验自己对知识的掌握程度。 费曼学习法可以简化为四个单词:**Concept**、**Teach ......
论文解读(DWL)《Dynamic Weighted Learning for Unsupervised Domain Adaptation》
[ Wechat:Y466551 | 付费咨询,非诚勿扰 ] 论文信息 论文标题:Dynamic Weighted Learning for Unsupervised Domain Adaptation 论文作者:Jihong Ouyang、Zhengjie Zhang、Qingyi Meng论文来 ......
农业工程与信息技术专业(Agricultural Engineering and Information Technology)
农业工程与信息技术专业的研究生考试情况。 (1)农业工程与信息技术是什么? 农业工程与信息技术专业(Agricultural Engineering and Information Technology),是一门集农业科学、环境生态工程、计算机科学、机械设备科学研究、工程项目科学研究、管理学等为一体 ......
InnoDB – the best storage engine for MySQL?
https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html InnoDB is a general-purpose storage engine that balances high reliability and high pe ......
《Decision Transformer: Reinforcement Learning via Sequence Modeling》论文学习
一、Introduction 先前的研究工作表明,Transformer可以对处于高维分布的语义概念进行大规模建模抽象,比较典型地体现如: 基于自然语言的零样本泛化(zero-shot generalization) 分布外图像生成(out-of-distribution image generat ......
Learning hard C#学习笔记——读书笔记 08
这篇文章介绍了什么是事件,以及如何在C#中使用事件。事件是在生活中发生的事情,它涉及到事件的发布者和事件的订阅者,当事件发生时,发布者会发布消息,订阅者会接收通知并做出相应的处理。在C#中,我们可以使用event关键字定义一个事件,然后订阅和取消事件的方法与委托链的取消和链接相同。 ......
提取wallpaper engine中的原图
# 提取wallpaper engine中的原图 在github中发现了一个可以提取wallpaper engine中场景原图的项目:[notscuffed/repkg: Wallpaper engine PKG extractor/TEX to image converter (github.co ......
Improved deep reinforcement learning for robotics through distribution-based experience retention
 **发表时间:**2016(IROS 2016) **文章要点:**这篇文章提出了experience repl ......
Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection(1)
MonoCon的网络结构和MonoDLE几乎一样,只是添加了辅助学习(Auxiliary Learning, AL)模块. 网络结构如上图所示,对于3D目标检测来说,预测2D框是没有必要的,但是MonoCon在训练阶段仍然计算了2D框的损失函数,但是在推理的时候,并不会预测2D框,这就是所谓的辅助学 ......
深入Scikit-learn:掌握Python最强大的机器学习库
> 本篇博客详细介绍了Python机器学习库Scikit-learn的使用方法和主要特性。内容涵盖了如何安装和配置Scikit-learn,Scikit-learn的主要特性,如何进行数据预处理,如何使用监督学习和无监督学习算法,以及如何评估模型和进行参数调优。本文旨在帮助读者深入理解Scikit- ......
The importance of experience replay database composition in deep reinforcement learning
 **发表时间:**2015(Deep Reinforcement Learning Workshop, NIPS ......
CF1184A3 Heidi Learns Hashing (Hard)
令 $c_i={w_1}_i-{w_2}_i$,相当于找到 $(r,P)$,满足: $$\sum\limits_{i=0}^nc_ir^i\equiv 0 \pmod P$$ 把这个东西写成多项式形式,令 $f(x)=\sum\limits_{i=0}^nc_ix^i$,即找到一个 $(r,P)$, ......
Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)论文阅读
深度估计问题 从输入的单目或双目图像,计算图像物体与摄像头之间距离(输出距离图),双目的距离估计应该是比较成熟和完善,但往单目上考虑主要还是成本的问题,所以做好单目的深度估计有一定的意义。单目的意思是只有一个摄像头,同一个时间点只有一张图片。就象你闭上一只眼睛,只用一只眼睛看这个世界的事物一样,距离 ......
Selective Experience Replay for Lifelong Learning
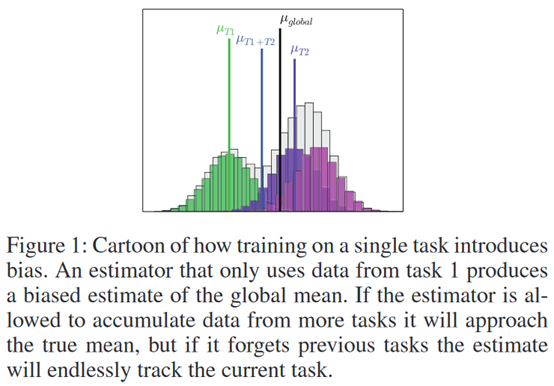 **发表时间:**2018(AAAI 2018) **文章要点:**这篇文章想解决强化学习在学多个任务时候的遗忘 ......
《LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS》论文学习
一、INTRODUCTION 深度神经网络规模和基于注意力的网络架构的结合,导致了语言模型具备了前所未有的通用性。“大型语言模型”(LLM)涌现出了很多令人惊艳的能力,包括: few-shot in-context learning zero-shot problem solving chain o ......
通过docker安装的jira提示We've detected a potential problem with JIRA's Dashboard configuration that your administrator can correct. Click here to learn more
正常通过docker安装jira后,访问是不会出问题的 但是如果使用nginx代理后,就是在nginx里配置了proxy_pass http://localhost:2800 再访问后,就会报错We've detected a potential problem with JIRA's Dashbo ......
Paper Reading: Exploratory Undersampling for Class-Imbalance Learning
本文是不平衡分类问题的经典论文,文中提出了 2 种不平衡集成学习模型都是简单而有效的 baseline 方法。 EasyEnsemble 方法直接对多数类样本进行采样得到几个子集,并使用这些子集分别训练基分类器。BalanceCascade 是使用训练好的分类器来指导后续分类器的采样过程,即在上一个... ......
Meta Learning(元学习)
Meta Learning(元学习) 元学习:学习如何学习:也是找一个函数,这个函数是学习算法,输出训练好的模型 假如教机器做了训练影像分类、影像识别等任务的模型,再去教机器训练语音识别的模型时,他可能学的更好,虽然语音和影像没有什么关系,但机器在多次的学习训练其他模型过程中,可能学到了如何去学习 ......
Life Long Learning(机器终身学习)
Life Long Learning(机器终身学习) Selective Synaptic plasticity(选择性突触可塑性) 只让类神经网路中,某一些神经元或某些神经元间的连接具有可塑性(只有部分的连接是有可塑性的,有些连接必须被固化,不能改变或移动他的数值) 为什么会灾难性遗忘: 假设模型 ......
概述增强式学习(Reinforcement Learning)
概述增强式学习(Reinforcement Learning) Supervised Learning(自监督学习):告诉机器输入和输出,用有标注的训练资料训练出的Network Reinforcement Learning(增强式学习):给机器一个输入,我们不知道最佳输出是什么(适用于标注困难或者 ......
Perkins Engines: Reliable Power in Harsh Environments and High-Strength Operations
Perkins Engines: Reliable Power in Harsh Environments and High-Strength OperationsHello everyone! Today I would like to share with you a powerful engi ......
machine learning-2023-07-19
questions【链接】 │ │──math │ │──线性回归 │ │──逻辑回归 │ └──梯度下降 │ │──python │ │──numpy(科学计算库) │ │──pandas(数据分析处理库) │ │──matplotlib(数据可视化库) │ └──scikit-learn(机器学 ......
Learn about some useful truck diagnostic scanner tools
Have you ever experienced the frustration of unexpected breakdowns with your truck? Or maybe you’re tired of paying expensive diagnostic fees at your ......